标签:installer 管理 ref 取数据 shel date 变量 bin iba
最近在重构权限管理系统(PMS),因此在验证新开发功能的行为是否和旧功能相同时,采用了一种思路,
控制相同的输入,比对输出是否尽可能一致。因为重构选用了微服务的架构,对于数据库这边拆分成了
多个库。因此开发时需要将原先的PMS库的数据迁移到异构的多个数据库中。
迁移的基本思路是写转换sql语句,查出数据并导入目标库的目标表
查出的数据导出到Excel,然后通过Excel导入到目的库。这种做法想想都让人绝望。
如果有个dblink也很棒啊。可是数据库产品不同,是否存在强大而灵活的dblink功能尚待求证。
自己搞个程序来连接源数据库和目标数据库来转移数据吧。这个比较灵活。应该是最为灵活也最为复杂的。
但这不是当前开发工作的主要任务。
对于迁移数据应该是常见的场景,定有现成可用的轮子,结果在一篇介绍多种数据迁移工具的文章里
发现了ali的DataX。稍加了解发现可以满足需求,就果断选用了。
浏览器里CTRL+F搜索2.6.6。我是64位机,选择Download Windows x86-64 MSI installer
安装过程就不再赘述。
最后将安装目录(python.exe的上级目录)添加到系统环境变量中
(比如C:\Python26)。
注意如果本机事先安装了python3,需要将刚安装好的python2的python.exe修改为python2.exe。
这样待会在使用DataX时可以用python2命令运行
cmd先输入CHCP 65001,解决乱码
# 先简单了解下如下命令,D:\soft\datax\datax\为DataX解压后的目录,运行如下命令需替换为你的解压目录
# 自检
python2 D:\soft\datax\datax\bin\datax.py D:\soft\datax\datax\job\job.json
# 输入命令查看配置模板
python2 D:\soft\datax\datax\bin\datax.py -r streamreader -w streamwriter
DataX的迁移思路和我们迁移数据的思路差别不大,无非是从源读取数据,再将数据写到目标中。只不过
它的实现更为精妙。具体可参考官方介绍
为使用DataX。我们只需要提供一个json配置文件即可。如下为我从oracle迁移bar表数据到postgres bar表的一个
迁移job示例脚本xx.json。
{
"job": {
"setting": {
"speed": {
"channel": 1
}
},
"content": [
{
"reader": {
"name": "oraclereader",
"parameter": {
"username": "foo",
"password": "bar",
"where": "",
"connection": [
{
"querySql": [
"SELECT fooxx as foo from bar"
],
"jdbcUrl": [
"jdbc:oracle:thin:@localhost:1521:orcl"
]
}
]
}
},
"writer": {
"name": "postgresqlwriter",
"parameter": {
"username": "foo",
"password": "bar",
"column": [
"foo"
],
"preSql": [
"delete from bar"
],
"postSql": [
"update bar set foo = ‘‘"
],
"connection": [
{
"jdbcUrl": "jdbc:postgresql://localhost:5432/postgres?characterEncoding=utf8",
"table": [
"bar"
]
}
]
}
}
}
]
}
}
开始迁移
#cmd进入迁移job配置文件xx.json所在的目录,执行如下命令
python2 D:\soft\datax\datax\bin\datax.py xx.json
#结果如下图
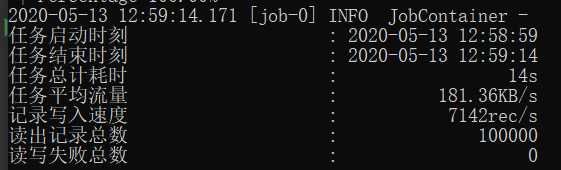
结果中需要关注的是读出记录总数和读写失败总数。
如果有读写失败,需要解决错误并判断是否要重新迁移。
如果要重新迁移,那之前已迁移的脏数据可以在preSql里做删除处理(生产环境中慎用)。
此外有些不能一下子迁移到目标表的情况,我们也可以在目标库中建一些辅助表。然后在postSql中作处理(比如将辅助表的某个栏位更新到目标表)
当job.json文件较多时,用dataX一个个指定json文件并运行,比较麻烦。因此写了一个
简单的python2脚本run.py来批量执行,脚本并不算健壮,这边作为一个示例。
# This Python file uses the following encoding: utf-8
import os
s = os.getcwd()
for f in os.listdir(s):
if f.endswith(‘.json‘):
# os.system(‘python2 D:\\soft\\datax\\datax\\bin\\datax.py ‘ + f)
print(‘运行‘ + f)
result = os.popen(‘python2 D:\\soft\\datax\\datax\\bin\\datax.py ‘ + f)
res = result.read()
read = 0
fail = 0
for line in res.splitlines():
if "读出记录总数" in line:
print(line)
read = int(line.split(‘:‘)[1])
if "读写失败总数" in line:
print(line)
fail = int(line.split(‘:‘)[1])
print(fail)
print(read)
if (fail > 0) or (read == 0):
print(‘pay attention‘)
进入job.json所在的目录,执行python2 run.py即可批量运行。运行结束需要关注下失败的情况。
PS: 我的个人博客 qiang哥
标签:installer 管理 ref 取数据 shel date 变量 bin iba
原文地址:https://www.cnblogs.com/hymanting/p/12897973.html