标签:设置 cdh 文本文件 inpu 配置说明 prope 查看 保存 tput
一、需求说明二、启动kettle
双击 Spoon.bat 就能启动 kettle 。
三、创建转换
1.Hadoop集群配置说明
首先需要从hadoop集群中(/../hadoop-3.1.2/etc/hadoop)复制core-site.xml,hdfs-site.xml,yarn-site.xml,mapred-site.xml文件到shim文件夹中(..\data-integration\plugins\pentaho-big-data-plugin\hadoop-configurations\cdh514),替换已有的文件。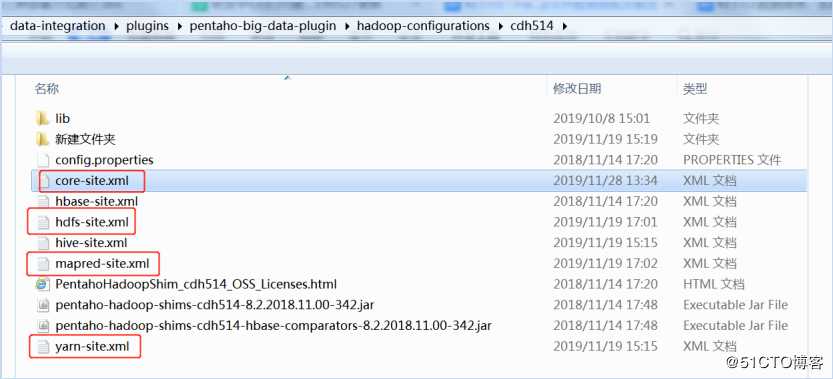
注意要修改这些配置文件。比如hadoop节点的地址是不是正确等。由于core-site.?xml 里面用的 hostname 连接的,而我们配置的时候用的 ip,所以需要修改core-site.xml为ip,然后重启Spoon。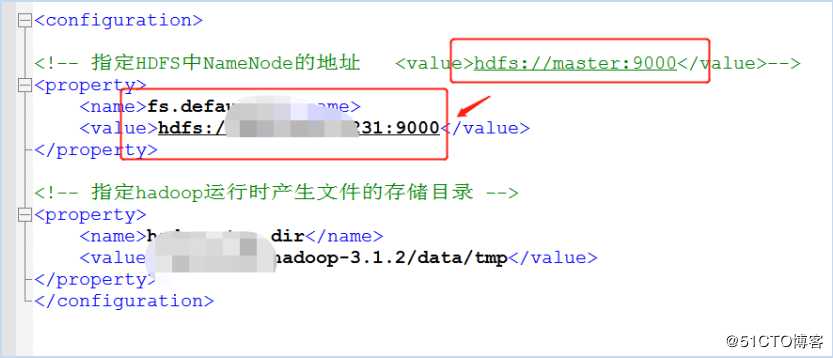
由于Hadoop权限管理是弱管理,此处用户名和密码可以缺省。不过往Hadoop创建文件需要进行权限鉴证,所以此处修改Hadoop中的core-site.xml文件如下所示,表示不经过任何验证,所有用户拥有全部权限。(修改此配置需要重启hadoop):<property>
<name>hadoop.security.authorization</name>
<value>false</value>
</property>
2.打开 kettle,点击 文件->新建->转换。
3.HDFS连接配置说明
打开左侧“主对象树”-》“Hadoop Clusters”新建一个Hadoop集群配置,此处我采用的是一个伪分布式集群环境,输入集群信息,点击测试,右边是测试结果。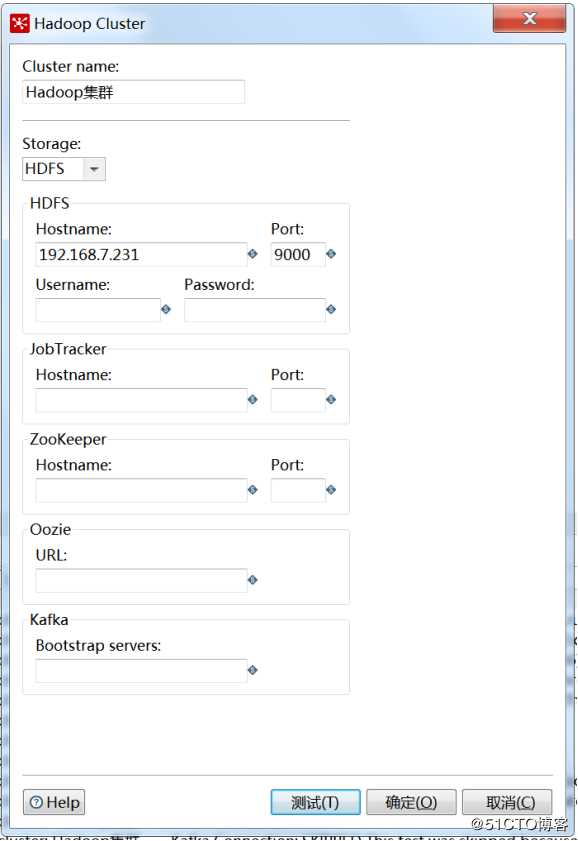
填写相应的配置值。具体含义见下表。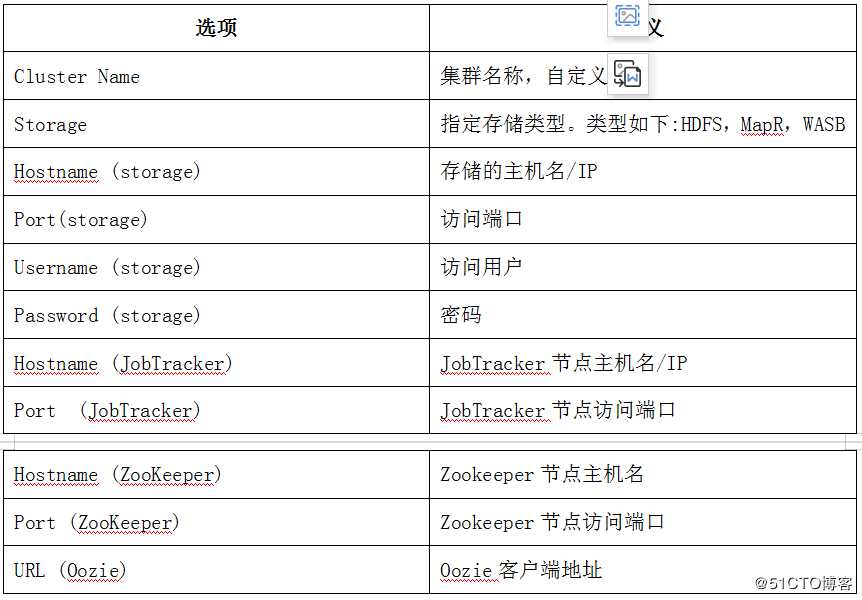
Hostname输入主节点IP,Port输入端口,此处跟core-site.xml中配置端口相同。
显示对勾的说明测试成功,红×说明出现问题,黄三角是警告。(上面这几个红叉不影响后面的使用,这块的排除暂且跳过)。
在左侧找到表输入(核心对象->输入->表输入),Hadoop文件输出(Big Data->Hadoop File output),如下所示: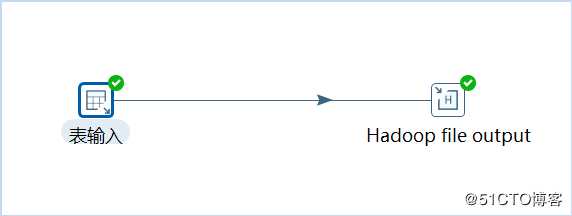
双击右侧表输入,进行配置,选择数据源,并输入 SQL。可以点击预览进行预览数据。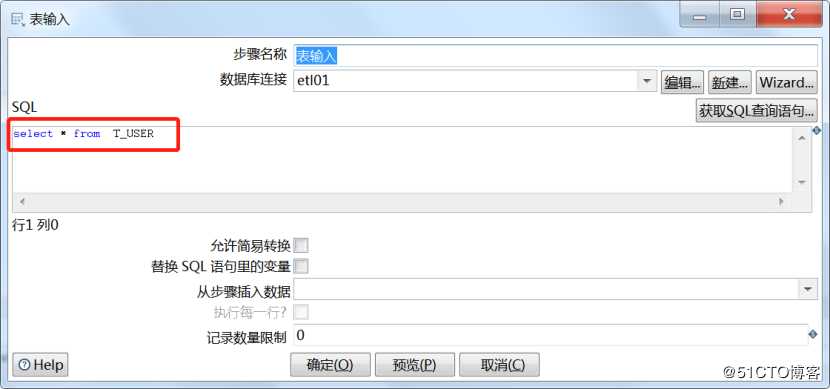
4.Hadoop文件输出配置
双击Hadoop文件输出,选择Hadoop集群配置,输出路径,文件扩展名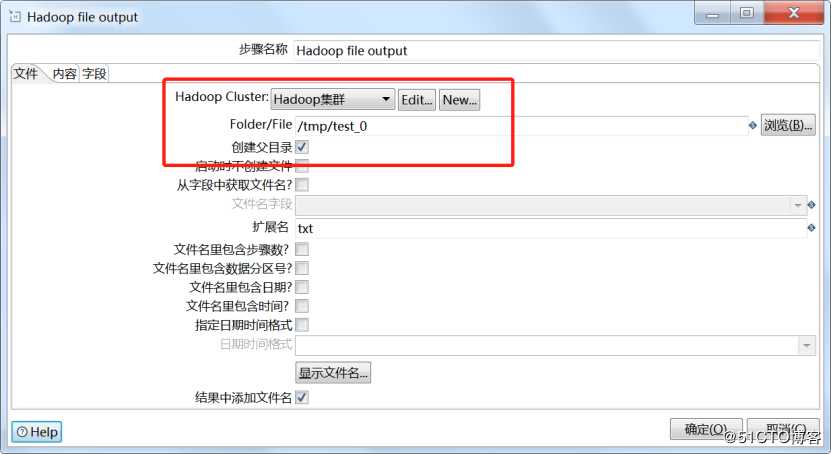
设置字段分隔符,设置编码格式为UTF-8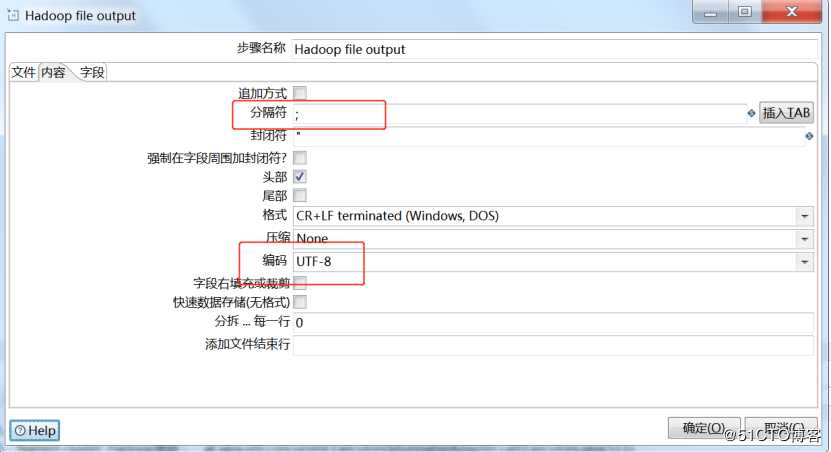
设置输出字段,可以通过“获取字段”完成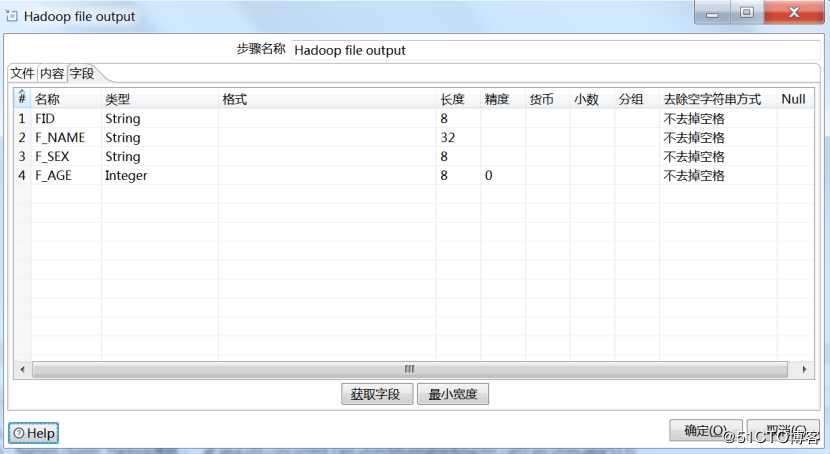
保存,点击运行,执行Hadoop查询命令,结果如下所示:
查看目录,hdfs dfs -ls /tmp
查看文件,hdfs dfs -cat /tmp/test_0.txt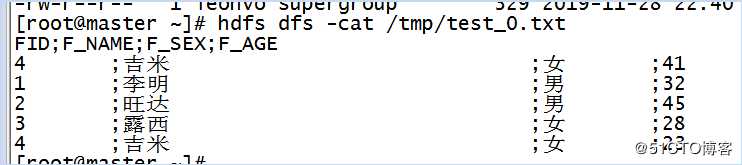
5.Hadoop文件抽取配置
新建一个转换,拖入Hadoop文件输入(Big Data->Hadoop File input),然后拖入一个文本文件输出,如下所示:
双击Hadoop文件输入进行配置,选择Hadoop集群链接,选择文件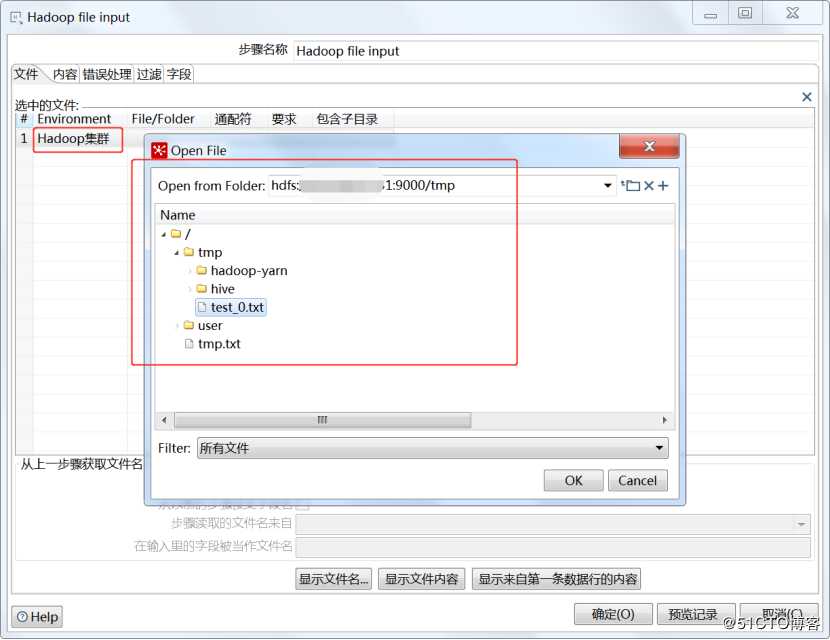
设置分隔符和编码方式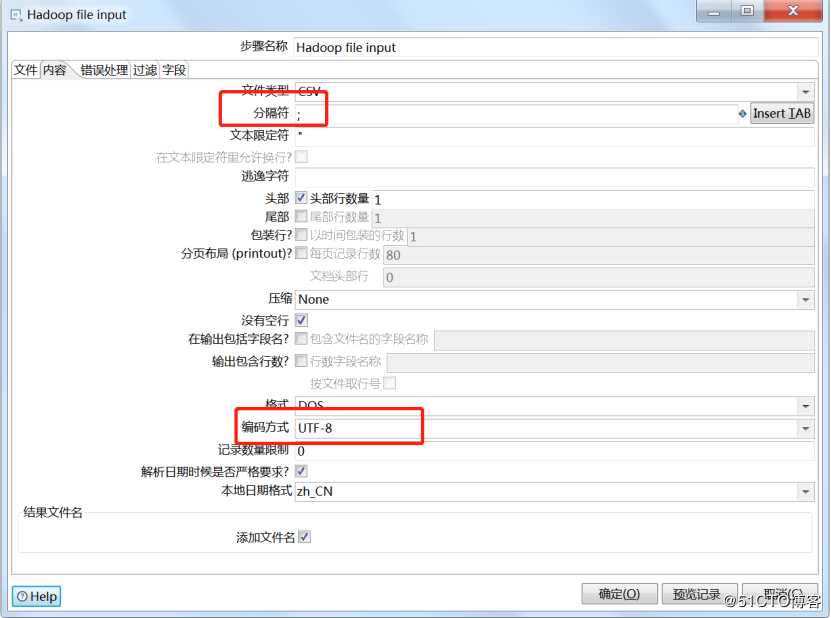
设置输入字段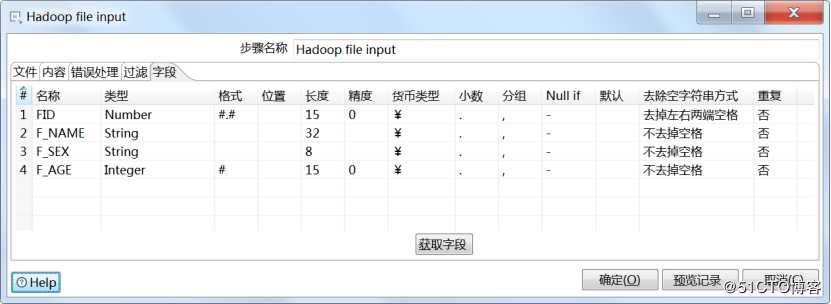
输出到文本文件不做说明,请参考之前课程。执行转换,查看结果。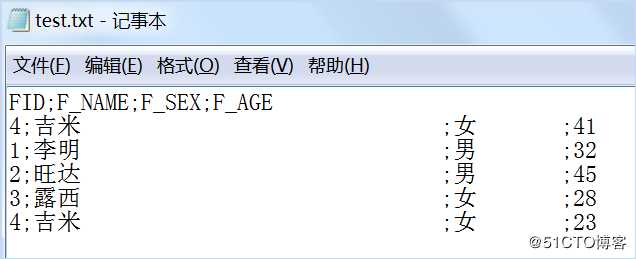
注意:想要学习通过kettle工具实现hive、hbase数据库抽取输出,和其他更多关于kettle的知识,请扫描以下二维码或者链接获取学习资料。
链接地址:
https://edu.51cto.com/sd/e80d0
二维码地址:
标签:设置 cdh 文本文件 inpu 配置说明 prope 查看 保存 tput
原文地址:https://blog.51cto.com/8985332/2497559