标签:image 字段 数据仓库 hive 数据校验 扩展 不可 show ring
为了将数据仓库设计过程中excel中设计的物理模型高效转换成标准的Hive建表语句,我用 python开发了如下的工具
createDdlSql.py:
功能:实现将excel中的物理模型转换成建表语句文件
输入:当前目录文件名为“数据模型.xls”或“数据模型.xlsx”的excel,模型结尾必须要有数据检验两行
输出:当前目录建表语句文件
python

1 ‘‘‘ 2 --*************************************************************** 3 --*脚本名称: createSqlDdl 4 --*功能: excel模型-》Ddl_表名.sql 5 --*输入数据:数据模型.xls or 数据模型.xlsx 6 --*输出数据:Ddl_表名.sql 7 --*作者: guominghuang 8 --*更新时间: 2020-5-15 15:00 9 --*************************************************************** 10 11 --*版本控制:版本号 提交人 提交日期 提交内容 12 -- V1.0 guominghuang 2020-5-15 新增上线 13 ‘‘‘ 14 import os 15 import numpy as np 16 import pandas as pd 17 from pandas import DataFrame 18 #HDFS数据仓库路径 19 HDFS_DIR = "‘hdfs://dse.host.hz.io:8020/jkd_dw/" 20 21 22 ‘‘‘ 23 转换函数 24 ‘‘‘ 25 def transform(file): 26 excel = pd.read_excel(file,None) 27 sheetNames = excel.keys() 28 for sheetName in sheetNames: 29 if sheetName.startswith("ods") or sheetName.startswith("dwd") or sheetName.startswith("dws") or sheetName.startswith("dws") or sheetName.startswith("ads") or sheetName.startswith("dim"): 30 #if sheetName.startswith("ods_tg_edu_b"): 31 df= DataFrame(pd.read_excel(file,sheetName)) 32 #获取表名和表注释 33 tableName = df.columns.values[1] 34 tableComment = df.iloc[0][1] 35 #删除第一行和第二行无用数据 36 df.drop([0,1],inplace=True) 37 #删除空行 38 df.dropna(axis=‘index‘, how=‘all‘,inplace=True) 39 #取出分区字段行 40 partitionRow = np.array(df[-3:-2]).tolist()[0] 41 42 43 # 获取分区字段名 44 partitionFieldName = partitionRow[0] 45 # 获取分区字段类型 46 partitionFieldType = partitionRow[1] 47 # 获取分区字段注释 48 #partitionFieldComment = partitionRow[columns[2]] 49 50 #判断是否存在分区字段"partition_date" 51 if partitionFieldName != "partition_date": 52 # 删除无用数据校验2行,获得所有字段 53 dfSub3row = df[:-2] 54 else: 55 # 删除无用数据校验2行和分区字段1行,获得所有字段 56 dfSub3row = df[:-3] 57 58 #获取列名 59 columns = df.columns.values 60 #获取字段名 61 fieldName = dfSub3row[columns[0]] 62 #获取字段类型 63 fieldType = dfSub3row[columns[1]] 64 #获取字段注释 65 fieldComment = dfSub3row[columns[2]] 66 67 sql = "CREATE EXTERNAL TABLE "+ tableName + " (\n" 68 #计数保证‘,‘格式 69 count = 0 70 # fieldName是Series类型,需要按key取值 71 #遍历所有字段 72 for i in fieldName.keys(): 73 if count == 0: 74 sql += " " + fieldName[i] + " " 75 + fieldType[i] + " COMMENT \‘" + fieldComment[i] + "\‘" + "\n" 76 else: 77 sql += " " + ‘,‘+ fieldName[i] + " " 78 + fieldType[i] + " COMMENT \‘" + fieldComment[i] + "\‘" + "\n" 79 80 count += 1 81 82 #判断是否存在分区字段"partition_date" 83 if partitionFieldName != "partition_date": 84 sql = sql + ")" + "\n" + "COMMENT ‘" + tableComment + "‘" + "\n" + "STORED AS PARQUET" + "\n" + "LOCATION" + ‘\n‘ 85 + HDFS_DIR + tableName[0:3] + "/" + tableName + "‘\n" + ";" 86 else: 87 sql = sql + ")" + "\n" + "COMMENT ‘" + tableComment + "‘" + " PARTITIONED BY(" + "\n" + partitionFieldName 88 + " " + partitionFieldType + ")" + "\n" + "STORED AS PARQUET" + "\n" + "LOCATION" + ‘\n‘ 89 + HDFS_DIR + tableName[0:3] + "/" + tableName + "‘\n" + ";" 90 91 # print(sql) 92 93 #创建Ddl文件 94 95 fileName = "Ddl_" + sheetName + ".sql" 96 #创建文件对象,覆盖写方式 97 fileObject = open(fileName,‘w‘) 98 try: 99 #创建文件 100 fileObject.write(sql) 101 finally: 102 #关闭文件对象 103 fileObject.close() 104 105 106 107 #主函数 108 if __name__ == ‘__main__‘: 109 #获取当前目录下数据模型文件 110 file_list = os.listdir(‘.‘) 111 for file in file_list: 112 if(file == ‘数据模型.xls‘) or (file == ‘数据模型.xlsx‘): 113 #生成建表文件 114 transform(file)
输入模型excel范例
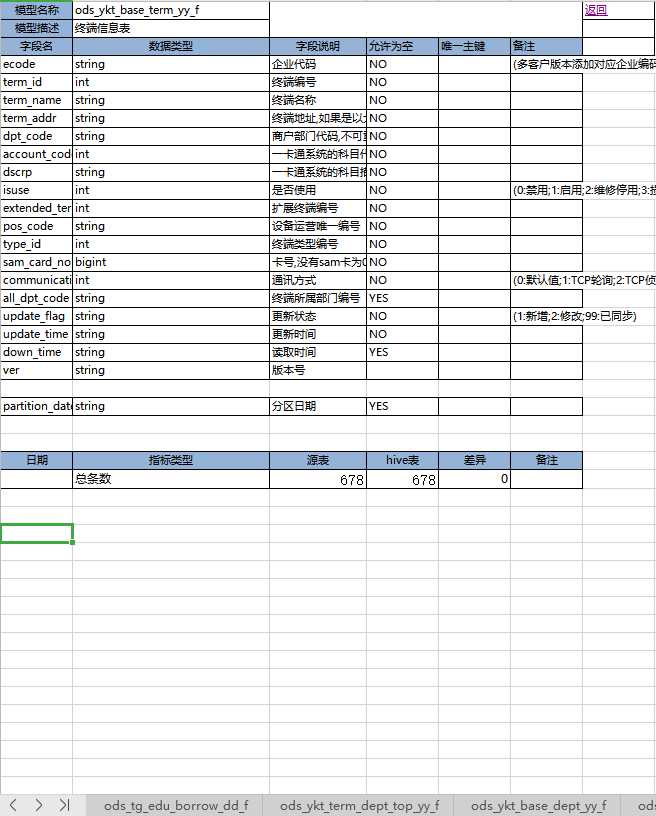
输出:
1 CREATE EXTERNAL TABLE ods_ykt_base_term_yy_f ( 2 ecode string COMMENT ‘企业代码‘ 3 ,term_id int COMMENT ‘终端编号‘ 4 ,term_name string COMMENT ‘终端名称‘ 5 ,term_addr string COMMENT ‘终端地址,如果是以太网设备就为实际的IP地址‘ 6 ,dpt_code string COMMENT ‘商户部门代码,不可重复‘ 7 ,account_code int COMMENT ‘一卡通系统的科目代码‘ 8 ,dscrp string COMMENT ‘一卡通系统的科目描述‘ 9 ,isuse int COMMENT ‘是否使用‘ 10 ,extended_term_addr int COMMENT ‘扩展终端编号‘ 11 ,pos_code string COMMENT ‘设备运营唯一编号‘ 12 ,type_id int COMMENT ‘终端类型编号‘ 13 ,sam_card_no bigint COMMENT ‘卡号,没有sam卡为0‘ 14 ,communication_mode int COMMENT ‘通讯方式‘ 15 ,all_dpt_code string COMMENT ‘终端所属部门编号‘ 16 ,update_flag string COMMENT ‘更新状态‘ 17 ,update_time string COMMENT ‘更新时间‘ 18 ,down_time string COMMENT ‘读取时间‘ 19 ,ver string COMMENT ‘版本号‘ 20 ) 21 COMMENT ‘终端信息表‘ PARTITIONED BY( 22 partition_date string) 23 STORED AS PARQUET 24 LOCATION 25 ‘hdfs://dse.host.hz.io:8020/jkd_dw/ods/ods_ykt_base_term_yy_f‘ 26 ;
标签:image 字段 数据仓库 hive 数据校验 扩展 不可 show ring
原文地址:https://www.cnblogs.com/huangguoming/p/12992373.html
