标签:http 直接 超过 bsp src inf 分代 方式 框架
Caffe框架GPU与MLU计算结果不一致请问如何调试?
某一检测模型移植到Cambricon Caffe上时,发现无法检测出结果,于是将GPU和MLU的运行结果输出并保存后进行对比,发现二者计算结果不一致,如下图所示:
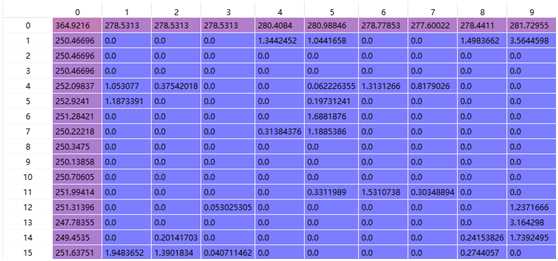
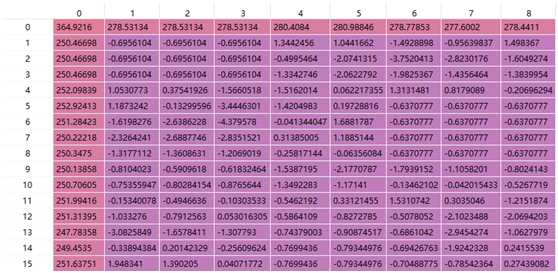
第一张为GPU模式下,第二张为GPU模式,二者使用的输入和数据预处理方式均完全一样,该输出为网络第一层卷积的部分输出。
用Cambricon Caffe提供的test_forward工具验证该模型在CPU和MLU模式下的输入,结果仍不一致,如下图所示:
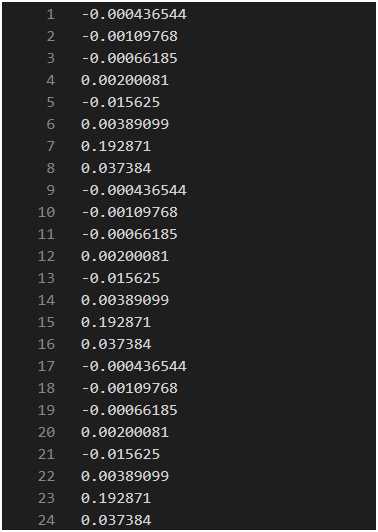
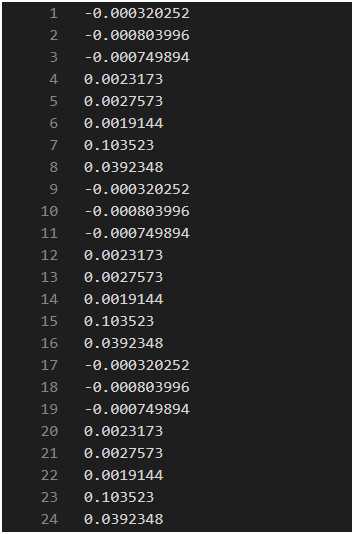
第一张为MLU模式下的输出,第二张CPU模式下的输出。
请问这种情况下如何调试具体哪里出现了问题?
在GPU模式下ROIPooling层的输出结果为:
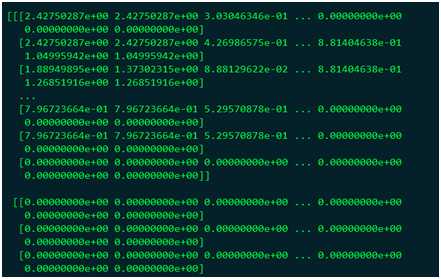
在MLU模式下运行,结果为:
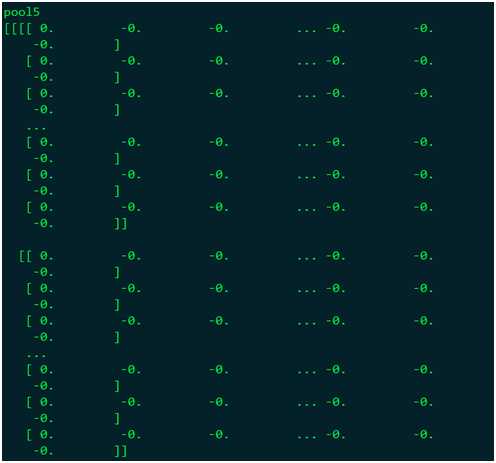
最后在CPU模式下使用ROIPooling算子,计算结果为:
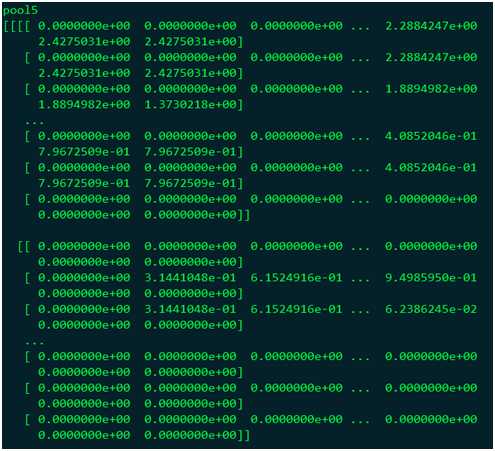
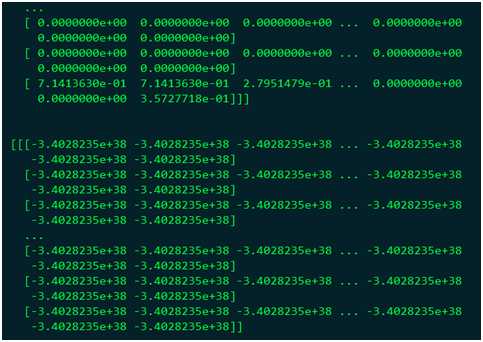
对比CPU和GPU的运算结果可知,仅处理了第一个ROI,修改了ROIPooling层部分代码才能得到正确结果。而MLU模式下的ROIPooling层的结果是完全错误的。
首先在GPU上使网络输出Proposal层的运算结果,如下:
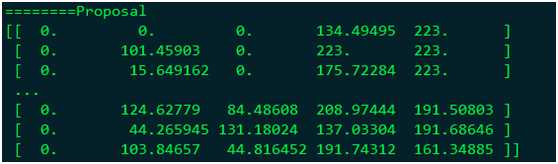
使用Proposal算子在CPU模式下运行的结果为:
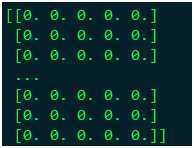
MLU模式下的结果为:
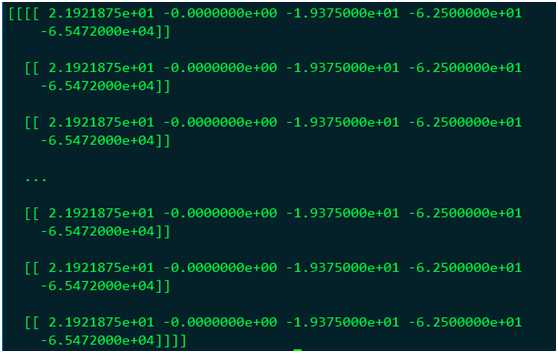
将Proposal层替换为Python的Proposal层,在CPU模式下的运算结果为:
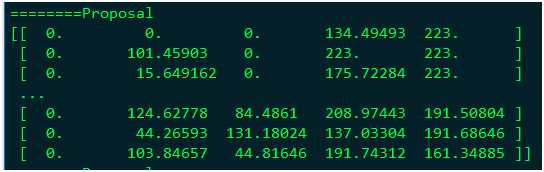
与GPU计算结果是一致的,所以认为Proposal算子有问题。
MLU100上的数据格式为FP16/INT8, 运算结果不一致是合理的,具体正确性要看误差,可以用MAPE度量一下误差,一般FP16不会超过%1。另外如果是faster-rcnn网络,不要直接比较proposal层之后的结果,只能直接比较proposal层前的结果。proposal层之后的结果因为涉及到bbox,无法直接比较,可以用IOU之类的方法比较。最后MLUfaster-rcnn的输出结果layout和CPU的输出结果layout不同,因此两者的后处理方式是不一致的,具体可以参考我司提供的后处理示例。
重新对比了一下GPU与MLU的输出结果,Proposal层之前的处理结果是正确的,但是MLU的Proposal和ROIPooling层有问题。在输入特征相同的情况下,使用FasterRCNN的Proposal层和MLU的Proposal层得到的结果是不一致的;使用FasterRCNN的Proposal层得到正确的ROI后,输入到ROIPooling层只处理了第一个ROI,我修改了CPU版本的ROIPooling层才可以得到正确的结果。
MLU100上的数据格式为FP16/INT8, 运算结果不一致是合理的,具体正确性要看误差,可以用MAPE度量一下误差,一般FP16不会超过%1。另外如果是faster-rcnn网络,不要直接比较proposal层之后的结果,只能直接比较proposal层前的结果。proposal层之后的结果因为涉及到bbox,无法直接比较,可以用IOU之类的方法比较。最后MLUfaster-rcnn的输出结果layout和CPU的输出结果layout不同,因此两者的后处理方式是不一致的,具体可以参考我司提供的后处理示例。
标签:http 直接 超过 bsp src inf 分代 方式 框架
原文地址:https://www.cnblogs.com/wujianming-110117/p/12994732.html