标签:表达式 函数 括号 datetime 无法 表单 namespace end temp
一眨眼间我们就将前端内容的页面布局介绍完了,接下来我们就要来学习python中比较重要的一个后端框架Django,在介绍Django之前我们先通过自行操作来了解一些Django的基础,所以让我用双手成就你的梦想吧。
首先我们来手动的敲一个web框架
import socket
sever = socket.socket()
sever.bind(("127.0.0.1",8080))
sever.listen(5)
‘‘‘
首先是socket的框架
‘‘‘
while True:
conn,addr = sever.accept()
data = conn.recv(1024)
conn.send(b"HTTP/1.1 200 OK \r\n\r\n") #如果不在这个位置按照http协议的规定来传输数据就会无法访问的情况
# print(data)
data = data.decode("utf-8") #得到的是一个对象
data_send = data.split(" ")[1] #可以自行查看一下data里面都有什么
if data_send =="/index":
with open ("test5.html","rb") as f:
conn.send(f.read())
else:
conn.send(b"false")
conn.close()
‘‘‘
不足之处:
1.代码重复(所有人都要重复写)
2.手动处理http格式数据,只能拿到url后缀,其他数据只能通过重新定义索引才能完成(数据格式相同)
3.并发问题
‘‘‘
接下来我们来了解一下一个高端封装的模块wsgiref
from wsgiref.simple_server import make_server
def index(env):
return "index"
def login(env):
return "login"
def error():
return "404 error"
def xxx(env):
with open(r"test3.html","r",encoding="utf-8") as f:
return f.read()
urls = [
("/index",index),
("/login",login),
("/xxx",xxx)
]
def run(env,response):
‘‘‘
:param env: 请求相关数据(模块处理的http数据封装为字典)
:param response: 响应相关数据
:return: 返回给浏览器的数据
‘‘‘
response("200 OK",[])#响应首行 响应头
path_info = env.get("PATH_INFO")
# path_info_byt = bytes(path_info.encode("utf-8"))
# return [b"hello",path_info_byt]
for url in urls:
if path_info == url[0]:
res = url[1](env)
break
else:
res = error()
return [res.encode("utf-8")]
if __name__ == ‘__main__‘:
res = make_server("127.0.0.1",8080,run)
#会实时监听ip+port 只要有客户端访问都会交给run函数处理
res.serve_forever()
‘‘‘
相较于之前我们自行操作的web服务端,通过模块锁封装的方法我们的使用更加简单了
因为我们的业务逻辑越来越复杂,所以代码量肯定会不断地增加,但在一个py文件中过多的不同功能
代码会显得特别累赘,所以我们根据每个部分的逻辑不同分为多个文件 urls.py views.py templates文件夹
这也是Django的简陋原型。
urls 路由与视图函数对应关系
views 视图函数
templates 模板文件夹存储HTML文件
‘‘‘
动、静态网页:
静态网页:直接写死数据的页面,万年不变
动态网页:数据是实时获取的,比如后端获取当前时间或者是后端数据来自于数据库
动态网页的制作:
动态时间的显示:
def use_time(env):
import datetime
time_time = datetime.datetime.now().strftime("%Y-%m-%d %X")
print(time_time)
with open(r"test3.html","r",encoding="utf-8") as f:
data = f.read()
data = data.replace("aaaa",time_time)
return data
动态获取一个字典:
def get_dictt(env):
from jinja2 import Template # 需要导入的模块
user_dic = {"username":"jiang","password":"123456"}
with open(r"test3.html", "r", encoding="utf-8") as f:
data = f.read()
tmp = Template(data)
res = tmp.render(user = user_dic)#给HTML页面传了一个值,页面通过{{user}}拿到这个值
return res
拿后端数据库数据:
后端:def get_user(env):
import pymysql
from jinja2 import Template
conn = pymysql.connect(
host = "127.0.0.1",
port = 3306,
user = "root",
password = "",
db = "django-base",
charset = "utf8",
autocommit = True
)
# print(conn)
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
sql = "select * from userinfo"
data_list = cursor.fetchall()
with open(r"test8.html", "r", encoding="utf-8") as f:
data = f.read()
tmp = Template(data)
res = tmp.render(user=data_list)
return res
HTML:<div class="container">
<div class = "row">
<table class="table">
<thead>
<tr>
<th>id</th>
<th>username</th>
<th>password</th>
</tr>
</thead>
<tbody>
{%for user_info in user%}
<tr>
<td>{{user_info.id}}</td>
<td>{{user_info.username}}</td>
<td>{{user_info.password}}</td>
</tr>
{%endfor%}
</tbody>
</table>
</div>
</div>
web响应流程图: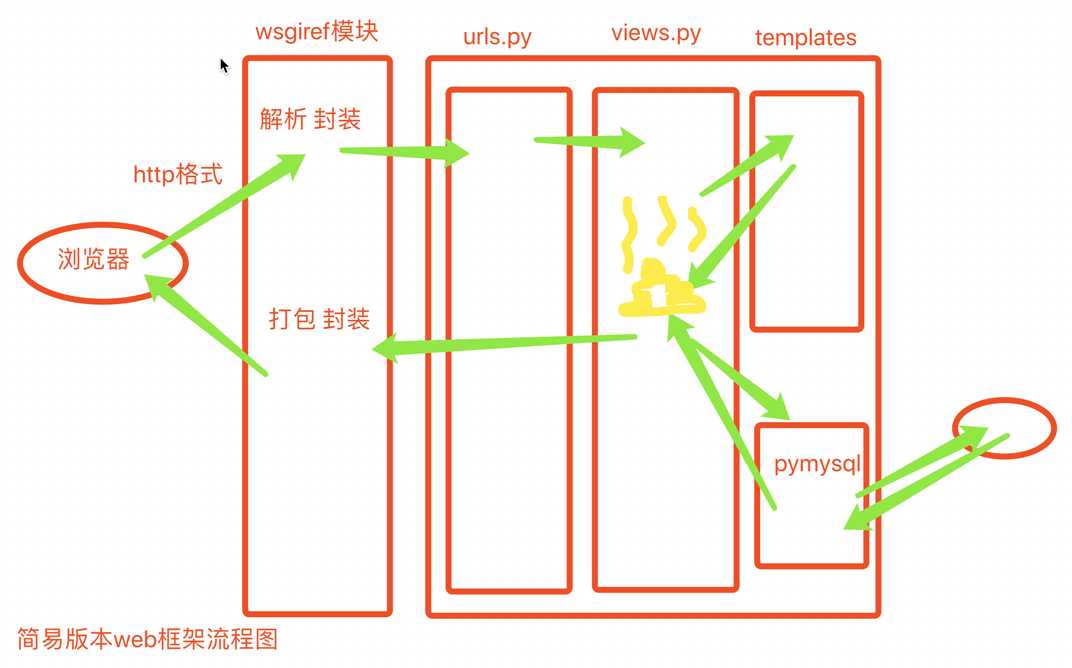
python主流三大web框架:
Django:
特点:大而全,自带功能多
不足:有时候过于笨重
flask:
特点:小而精 自带功能少但是第三方模块多,如果总的来算功能更多于Django而且越来越像
不足:非常依赖于第三方模块
tornado:
特点:异步非阻塞 支持高并发 甚至可以开发游戏服务器
启动Django需要注意的问题:
1.你的计算机不要有中文名称
2.Django的内部文件不要有中文名称
3.解释器最好是python3.4~3.6
4.一个窗口只能打开一个Django项目
创建一个django项目(命令行):
django-admin startproject 项目名 创建一个django项目
python3 manage.py runserver 启动服务 (已经位于项目文件夹下)
python3 manage.py startapp 应用名 创建应用
创建一个django项目(pycharm):
new project 选择django
上方绿色箭头 运行服务
python3 manage.py startapp 应用名 创建应用在创建过后要在settings中注册
ps:在用pycharm创建项目的时候会自动创建templates文件夹并且配置好settings
应用的概念:APP就是具体的应用模块 django就是一个大的框架,而真正实现功能的是APP应用
文件介绍:
-mysite项目文件夹
--mysite文件夹
---settings.py 配置文件
---urls.py 路由与视图函数对应关系(路由层)
---wsgi.py wsgiref模块(不考虑)
--manage.py django的入口文件
--db.sqlite3 django自带的sqlite3数据库(小型数据库 功能不是很多还有bug)
--app01文件夹
---admin.py django后台管理
---apps.py 注册使用
---migrations文件夹 数据库迁移记录
---models.py 数据库相关的 模型类(orm)
---tests.py 测试文件
---views.py 视图函数(视图层)
初始django三板斧:
HttpResponse
返回字符串类型的数据
render
返回html文件的
redirect
重定向
return redirect(‘https://www.mzitu.com/‘)
return redirect(‘/home/‘)
静态文件配置:我们在将HTML文件放在templates文件夹内,当我们使用css js img文件的时候应该去哪里取呢,我们接下来学习静态文件。
我们将静态文件放在static文件夹内,静态文件都包括那些呢?
静态文件:
前端已经写好了的 能够直接调用使用的文件
网站写好的js文件
网站写好的css文件
网站用到的图片文件
第三方前端框架
django是不会为我们创建static文件夹的,需要我们自己创建。我们在创建static文件并且引入后是无法直接应用的,因为我们没有创建相应端口,所以无法访问,于是我们需要向setting文件中配置相关端口
STATIC_URL = ‘/static/‘ 动态令牌,想要访问static中的配置文件必须由这个字符开头
STATICFILES_DIRS = [
os.path.join(BASE_DIR,"文件夹路径") 当你调用静态文件中的配置文件时会从这个列表中依次寻找到为止
]
html:
静态文件动态解析
{% load static %}
<link rel="stylesheet" href="{% static ‘bootstrap-3.3.7-dist/css/bootstrap.min.css‘ %}">
<script src="{% static ‘bootstrap-3.3.7-dist/js/bootstrap.min.js‘ %}"></script>
form表单的相关: form表单提交数据默认方式是get,当我们在使用post提交数据的时候需要注释掉django的一个中间键
(在setting文件中“‘django.middleware.csrf.CsrfViewMiddleware‘,”)
request方法初始:
request.method # 返回请求方式 并且是全大写的字符串形式 <class ‘str‘>
request.POST # 获取用户post请求提交的普通数据不包含文件
request.POST.get() # 只获取列表最后一个元素
request.POST.getlist() # 直接将列表取出
request.GET # 获取用户提交的get请求数据
request.GET.get() # 只获取列表最后一个元素
request.GET.getlist() # 直接将列表取出
get请求携带的数据是有大小限制的 大概好像只有4KB左右
而post请求则没有限制
pycharm连接数据库:要提前建好库才能导入
接下来是配置setting django默认是sqlite3数据库,而我们使用mysql
DATABASES = {
‘default‘: {
‘ENGINE‘: ‘django.db.backends.mysql‘,
‘NAME‘: ‘day60‘,
‘USER‘:‘root‘,
‘PASSWORD‘:‘admin123‘,
‘HOST‘:‘127.0.0.1‘,
‘PORT‘:3306,
‘CHARSET‘:‘utf8‘
}
}
最后你需要在你的init中声明你是用的是什么数据库
import pymysql
pymysql.install_as_MySQLdb()
django orm:在django中我们并不是直接使用mysql语句而是通过一种神奇的映射关系来为我们提供使用方式。
ORM. 对象关系映射
作用:能够让一个不用sql语句的小白也能够通过python 面向对象的代码简单快捷的操作数据库
不足之处:封装程度太高 有时候sql语句的效率偏低 需要你自己写SQL语句
通过orm映像数据库的时候我们首先要在我们的model.py中声明一个类
class Users(models.Model): (需要继承models.Model)
id = models.AutoField(primary_key="True")
username = models.CharField(max_length=32) 还有一个verbose参数 是用来对字段的解释
password = models.IntegerField()
类创建完成后我们发现我们的数据库没有更新,所以我们需要进行数据库迁移
python3 manage.py makemigrations 记录你的数据库操作
python3 manage.py migrate 同步数据库
字段的增删改可以直接在类的定义里完成,但是一定要记住每次在你更改完数据库的时候都要进行数据库的迁移。
数据库的增删改查:
在你的视图层导入你在models内定义的类
from app import models
使用你导入的模块:
查询:
第一种:user_obj = models.Users.objects.filter(筛选条件) 查询,返回值是一个列表套数据对象 支持索引切片不支持负数索引
也支持多个索引条件,默认是and关系
第二种:user_obj = models.Users.objects.all(筛选条件) 查询所有的数据
创建:
第一种:user_obj = models.Users.objects.create(键值对) 创建数据
第二种:user_obj = models.Users(键值对) user_obj.save() 创建数据
修改:
第一种:user_obj = models.Users.objects.filter(条件).update(键值对) 修改数据
第二种:edit_obj.username = username
edit_obj.password= password
edit_obj.save()
第二种方式相对于第一种方式效率要更低,因为第二种方式在字段更新的时候会从头到尾更新一遍
删除:
models.User.objects.filter(id=delete_id).delete()
删除数据库的时候我们并没有真正的删除这个数据,而是将数据中属性is_delete标识为0,
当数据库查询的时候会将这个值为0的数据过滤掉。
django orm创建表关系:
在学习数据库的时候我们接触了表关系,那么在django orm映射中我们是如何创建表关系的呢?
首先我们有哪些表关系? 一对一 一对多 多对多三种表关系。我们来举个例子,我们有如下几张表
图书表、出版社表、作者表、作者详情表
图书和出版社是一对多的关系 外键字段建在多的那一方 book
图书和作者是多对多的关系 需要创建第三张表来专门存储
作者与作者详情表是一对一
在知道了表的对应关系之后我们就该使用orm来创建表关系了,首先我们创建基表然后根据我们之前的学习来创建外键
外键名 = models.ForeignKey(to = "关系表") 默认就是关联了关系表的主键 orm会自动为你在字段后面+_id 一对多
外键名 = models.ManyToManyField(to = "关系表")多对多的关系会自动帮你创建一个第三张关系表
外键名 = models.OneToOneFiled(to = "关系表")一对一关系
django请求生命周期流程图: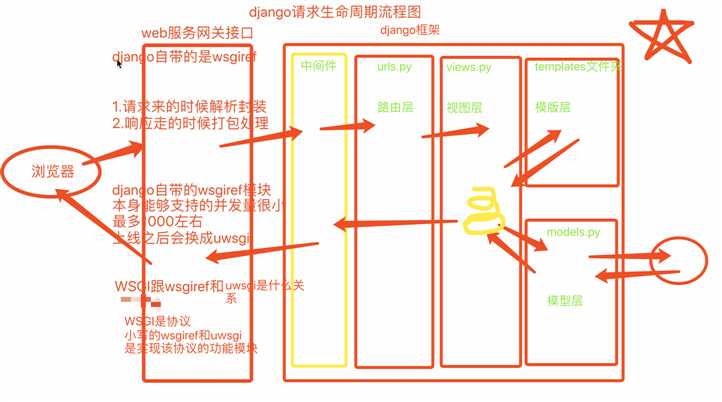
路由层:
路由匹配:url(r‘test‘,views.test),
第一个参数是正则用来匹配网址,只要正则表达式能够匹配到内容那么就会立刻停止往下匹配,直接执行函数,所以我们一般都在正则后加一个斜杠,而当你匹配失败的时候django会帮你加上一个斜杠再来一次匹配,如果你想取消自动加斜杠可以再settings加上如下配置
APPEND_SLASH = False
解决了斜杠的问题之后我们发现当我们在前面输入其他字符的时候会发生匹配成功的情况,所以我们要在开头加上^ 结尾加上$这样我们的路由就基本完善了。
无名分组:
分组:就是给某一段正则表达式用小括号扩起来
无名分组就是将括号内正则表达式匹配到的内容当作位置参数传递给后面的视图函数
url(r‘^test/(\d+)/‘,views.test)
有名分组:
有名分组就是将括号内正则表达式匹配到的内容当作关键字参数传递给后面的视图函数
url(r‘^testadd/(?P<year>\d+)‘,views.testadd)
ps:无名分组和有名分组不能混用,但是可以一种多次使用
反向解析:
通过一些方法得到一个结果 该结果可以直接访问对应的url触发视图函数
先给路由与视图函数起一个别名
url(r‘^func_kkk/‘,views.func,name=‘ooo‘)
反向解析
# 后端反向解析
from django.shortcuts import render,HttpResponse,redirect,reverse
reverse(‘ooo‘)
前端反向解析
<a href="{% url ‘ooo‘ %}">111</a>
无名分组的反向解析:
url(r‘^index/(\d+)/‘,views.index,name=‘xxx‘)
前端
{% url ‘xxx‘ 123 %}
后端
reverse(‘xxx‘, args=(1,))
有名分组反向解析:
url(r‘^func/(?P<year>\d+)/‘,views.func,name=‘ooo‘)
在前端和后端的书写上为了方便使用,django为我们简化了这一过程,所以我们书写也按照无名的规格书写即可
路由分发:
django可以拥有多个应用,这就意味着它可以有多套templates urls static,正是基于这些东西我们可以对一个大项目进行分组开发。当一个django的url特别多的时候代码冗余不易维护,这时可以通过路由分发来减轻路由带来的压力。
路由分发后总路由将不再直接与views视图层关联,而是通过解析左移个分发处理交给各个应用层的url去处理,而在总路由进行一个路由分组就需要我们引入新的方法 include
总路由:
from django.conf.urls import url,include
url(r‘^app01/‘,include(‘app01.urls‘)),
子路由:
from django.conf.urls import url
from app01 import views
urlpatterns = [
路由地址
]
名称空间:
多个应用出现了相同的别名,正常情况下反向解析是没办法识别前缀的,所以我们需要在总路由分组的时候为他们提供相应的名称空间,通过设置namespace属性来限制名称空间。
一般情况下有多个app的时候我们在起别名的时候会加上app的前缀这样的话就能够确保多个app之间名字不冲突的问题
伪静态:
一看就知道不是真正的静态。我们在浏览某些网页的时候发现https://www.cnblogs.com/Dominic-Ji/p/9234099.html是一个静态网页的形式,那么为什么要进行这种伪装呢?伪装的目的在于增大本网站的seo查询力度并且增加搜索引擎收藏本网上的概率,一旦你的网页是静态而不是动态的那么就证明你的网页信息基本不会发生变化,所以浏览器就会收藏你甚至是优先推荐。
但是大家可以看到现在浏览器的尿性程度,基本上第一页都是广告,所以钱是最好的优化方案。
虚拟环境:
在正常情况下,我们只给一个项目装上他独有的解释器环境,这个环境中只有有用的的模块,其他一概不装,因此我们需要一个环境来完成这一步骤
我们每次创建一个虚拟环境就类似于重新下载了一个纯净的python解释器,但是我们也不要创建太多,因为它还是消耗一定空间的
我们在开发中会配备一个requirements.txt文本,里面配备了所有我们项目所用的模块以及版本,只需要执行一句语句就可以自动安装模块
如果我们的项目含有一个venv文件夹,说明我们在使用的是虚拟环境
django版本的区别:
我们一直在使用的是django1.x版本,接下来我们就来了解一下他和后面版本的区别。
django1.x使用的是url方法,而在后续版本2.x 3.x都是用的是path方法。path方法不同于url方法的是不支持正则而是精准匹配,但是django为我们提供了re_path功能与url一样支持正则匹配。虽然path不支持正则,但是它内部支持五种转换器。
path(‘index/<int:id>/‘,index)将第二个路由里面的内容先转成整型然后以关键字的形式传递给后面的视图函数
str,匹配除了路径分隔符(/)之外的非空字符串,这是默认的形式
int,匹配正整数,包含0。
slug,匹配字母、数字以及横杠、下划线组成的字符串。
uuid,匹配格式化的uuid,如 075194d3-6885-417e-a8a8-6c931e272f00。
path,匹配任何非空字符串,包含了路径分隔符(/)(不能用?)
除了五种自带转换器我们还可以自定义转换器
class MonthConverter:
regex=‘\d{2}‘ # 属性名必须为regex
def to_python(self, value):
return int(value)
def to_url(self, value):
return value # 匹配的regex是两个数字,返回的结果也必须是两个数字
from django.urls import path,register_converter
from app01.path_converts import MonthConverter
# 先注册转换器
register_converter(MonthConverter,‘mon‘)
from app01 import views
urlpatterns = [
path(‘articles/<int:year>/<mon:month>/<slug:other>/‘, views.article_detail, name=‘aaa‘)
模型层里面1.X外键默认都是级联更新删除的
但是到了2.X和3.X中需要你自己手动配置参数
models.ForeignKey(to=‘Publish‘)
models.ForeignKey(to=‘Publish‘,on_delete=models.CASCADE...)
视图层:
最为必会的三板斧HttpResponse,render,redirect他们本质又都是什么呢?大家发现我们没有给视图层的函数方法设置返回值的时候,会报一个没有返回HttpResponse对象,所以三板斧本质上都是HTTPResponse类的对象。
JsonResponse对象:
json格式的数据用于前后端数据交互的时候,完成跨语言数据传输。在进行转换的时候可以添加ensure_ascii = False来进行不转码的操作。
前端序列化
JSON.stringify() json.dumps()
JSON.parse() json.loads()
后端使用JsonResponse。
文件上传:
在文件上传的时候我们必须使用post方法提交,但是我们在后端进行取得时候发现request.post并不能取到文件,所以request为我们提供了FILES方法
request.FILES.get() 获取文件对象
然后通过我们写文件的形式进行保存
with open(file_obj.name,‘wb‘) as f:
for line in file_obj.chunks(): # 推荐加上chunks方法 其实跟不加是一样的都是一行行的读取
f.write(line)
request方法补充:都是获取用户输入的路径
request.path
request.path_info
request.get_full_path() 能过获取完整的url及问号后面的参数
request.body()原生的浏览器发的二进制数据
标签:表达式 函数 括号 datetime 无法 表单 namespace end temp
原文地址:https://www.cnblogs.com/Jicc-J/p/13019842.html