标签:作者 idf load 算法 word code mes 意思 参数
计算不同文档间的语义相似度(或距离),先用不同文档的所有单词(去除停用词)通过单词出现数量加权和标准化来向量化表示文档,再计算不同文档向量之间各个单词的映射关系,即找出文档1中所有单词分别映射到文档2中具体哪些单词(该步骤计算使用word embedding计算欧氏距离),最后对匹配好的所有单词距离进行计算并sum为文档距离。 该算法没有考虑文档中单词出现的顺序,考虑到了单词出现的数量,考虑了单词的语义相似性,也考虑了同一意思的不同句子可以用不同单词表示的情况。由于WMD算法时间复杂度较大,同时给出了2中优化算法。
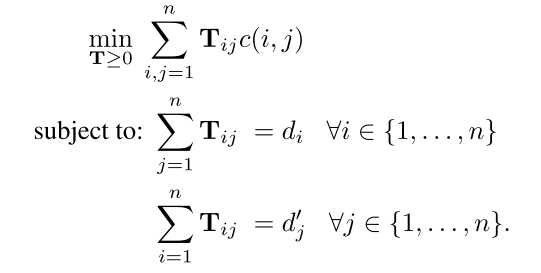
该算法使用了初中数学讲的基本不等式:\(\left | a \right | + \left | b \right | \geqslant \left | a+b \right |\),并
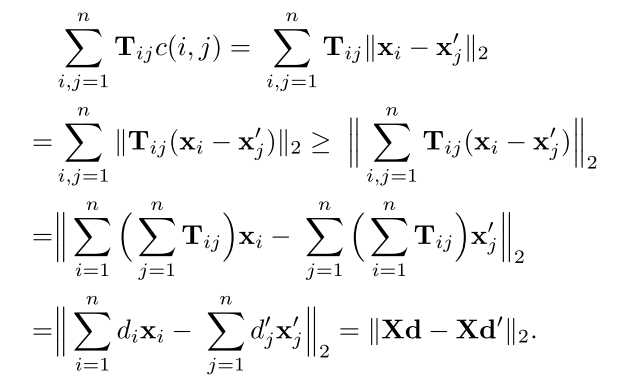

对【WMD: From Word Embedding to Document Distance】的理解
标签:作者 idf load 算法 word code mes 意思 参数
原文地址:https://www.cnblogs.com/andre-ma/p/13062018.html