标签:arc format iostream 课程 最小 splay style -- 邻接
(Vi,Vj)来表示。<Vi, Vj> 来表示,其中 Vi 称为弧尾,Vj 称为弧头。首先从图中某个顶点v0出发,访问此顶点,然后依次从v相邻的顶点出发深度优先遍历,直至图中所有与v路径相通的顶点都被访问了;若此时尚有顶点未被访问,则从中选一个顶点作为起始点,重复上述过程,直到所有的顶点都被访问完。

//DFS算法大概思想 void dfs()//参数用来表示点的状态 { if(到达终点状态) { ...//添加未访问的点 return; } if(越界或者是不合法) return; if(特殊状态)//剪枝 return ; for(扩展方式) { if(扩展方式所达到状态合法) { 修改操作;//添加 标记; dfs(); (还原标记); //是否还原标记根据题意 //如果加上(还原标记)就是 回溯法 } } }
首先,从图的某个顶点v0出发,访问了v0之后,依次访问与v0相邻的未被访问的顶点,然后分别从这些顶点出发,广度优先遍历,直至所有的顶点都被访问完。
https://blog.csdn.net/weixin_40953222/article/details/80544928(关于DFS和BFS两种算法的入门解析)
(1)邻接矩阵
用一个一维数组存放顶点的元素信息
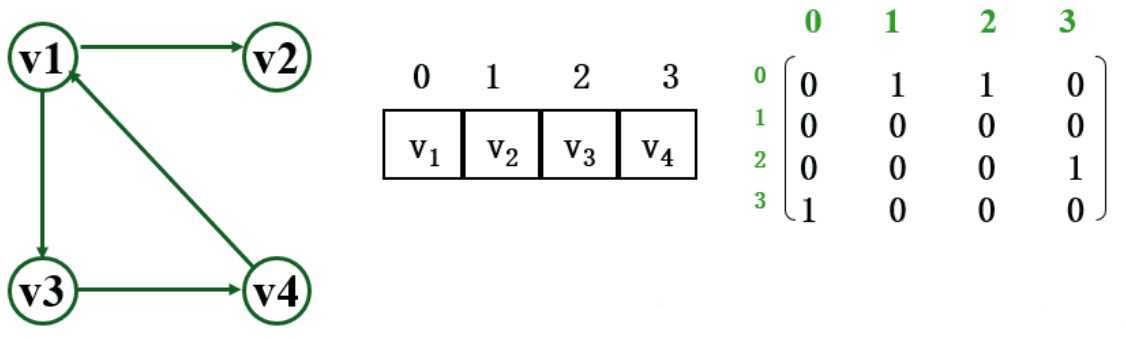
用一个二维数组存储顶点之间的关系,其中的数据元素A[i][j] = 1,i到j有弧且i≠j,否则A[i][j]= 0
struct VerType{ int no;//顶点的编号 char info;//顶点的其他信息 }; struct MGraph{ int n,e;//结点数目与边数 int edges[maxn][maxn];//邻接矩阵的定义 int VerType[maxn]; //存放结点的信息 };
有向图
无向图
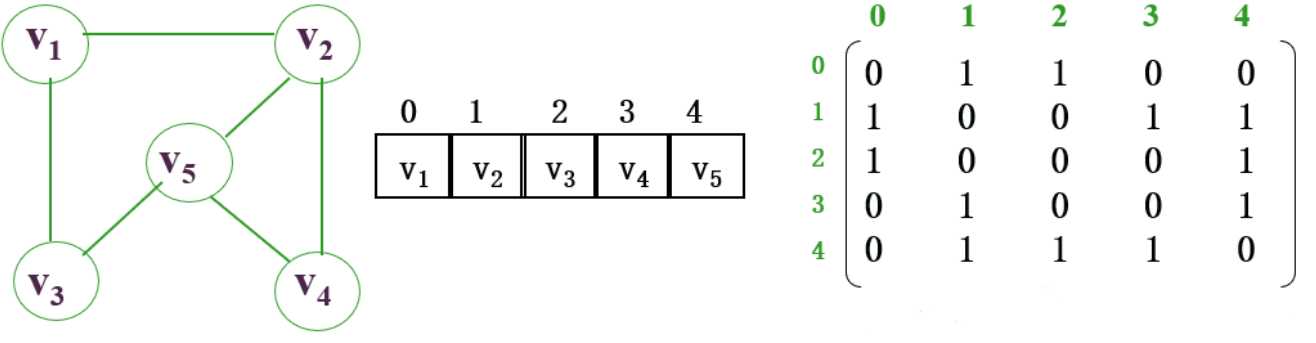
无向图的邻接矩阵是对称矩阵
网的邻接矩阵:
A[i][j] = w[i][j] 若<vi,vj>或(vi,vj)∈E ,否则为∞
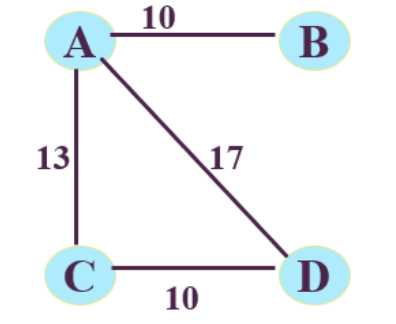
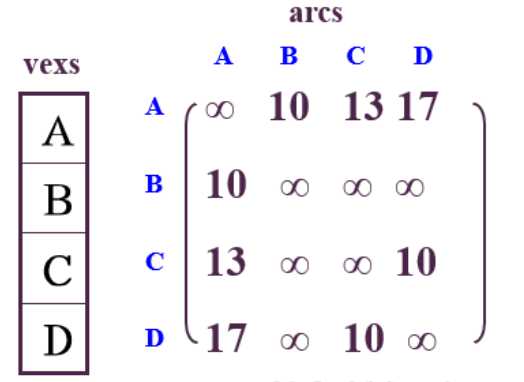
优点: 易判定任两个顶点之间是否有边或弧存在,适合存储有向图,无向图,有向网,无向网
缺点: 在边稀疏时,浪费存储空间
(2)邻接表
1 struct ArcNode{ 2 int adjvex;//这条边所指向的结点信息 3 struct ArcNode *nextarc;//该顶点指向下一条边的指针 4 int info;//这条边的相关信息如权值 5 }; 6 struct VNode { 7 char data;//顶点信息 8 ArcNode *firstarc;//指向第一条边的指针 9 }; 10 struct Agraph{ 11 12 VNode adjlist[maxn];//邻接表 13 int n,e;//顶点数目和边数 14 }; 15

adjvex:指示与vi邻接的顶点在图中的位置
nextarc:指示下一条边或弧的结点
info:存储和边或弧有关的信息(如权值)

data:存储顶点名称和其他相关信息
firstarc:指向链表中第一个结点
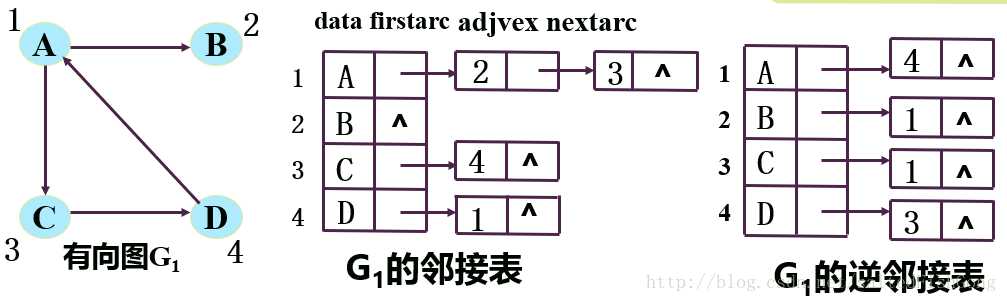
若无向图有v个顶点,w条边,则它的邻接表需要v个头结点和2w个表结点(边稀疏时比邻接矩阵省空间)

https://blog.csdn.net/zhembrace/article/details/72625413 (图的几种存储方式的代码描述)
https://blog.csdn.net/saltedFishGong/article/details/78764901(基本两种存储结构的理解)
https://blog.csdn.net/JYL1159131237/article/details/78504961 (两种存储结构的转换)
普里姆算法(Prim)
从顶点0开始,首先将顶点0加入到树中(标记),顶点0和其它点的横切边(这里即为顶点0的邻接边)加入优先队列,将权值最小的横切边出队,加入生成树中。此时相当于也向树中添加了一个顶点2,接着将集合(顶点1,2组成)和另一个集合(除1,2的顶点组成)间的横切边加入到优先队列中,如此这般,直到队列为空。
1 //进行prim算法实现,使用的邻接矩阵的方法实现。 2 void Prim(Graph g,int begin) { 3 //close_edge这个数组记录到达某个顶点的各个边中的权重最大的那个边 4 Assis_array *close_edge=new Assis_array[g.vexnum]; 5 6 int j; 7 8 //进行close_edge的初始化,更加开始起点进行初始化 9 for (j = 0; j < g.vexnum; j++) { 10 if (j != begin - 1) { 11 close_edge[j].start = begin-1; 12 close_edge[j].end = j; 13 close_edge[j].weight = g.arc[begin - 1][j]; 14 } 15 } 16 //把起点的close_edge中的值设置为-1,代表已经加入到集合U了 17 close_edge[begin - 1].weight = -1; 18 //访问剩下的顶点,并加入依次加入到集合U 19 for (j = 1; j < g.vexnum; j++) { 20 21 int min = INT_MAX; 22 int k; 23 int index; 24 //寻找数组close_edge中权重最小的那个边 25 for (k = 0; k < g.vexnum; k++) { 26 if (close_edge[k].weight != -1) { 27 if (close_edge[k].weight < min) { 28 min = close_edge[k].weight; 29 index = k; 30 } 31 } 32 } 33 //将权重最小的那条边的终点也加入到集合U 34 close_edge[index].weight = -1; 35 //输出对应的边的信息 36 cout << g.information[close_edge[index].start] 37 <<" " 38 << g.information[close_edge[index].end] 39 << " " 40 <<g.arc[close_edge[index].start][close_edge[index].end] 41 <<endl; 42 43 //更新我们的close_edge数组。 44 for (k = 0; k < g.vexnum; k++) { 45 if (g.arc[close_edge[index].end][k] <close_edge[k].weight) { 46 close_edge[k].weight = g.arc[close_edge[index].end][k]; 47 close_edge[k].start = close_edge[index].end; 48 close_edge[k].end = k; 49 } 50 } 51 } 52 }
克鲁斯卡尔算法(Kruskal)
按照边的权重顺序来生成最小生成树,首先将图中所有边加入优先队列,将权重最小的边出队加入最小生成树,保证加入的边不与已经加入的边形成环,直到树中有V-1到边为止。
1 //克鲁斯卡算法的实现 2 void Kruskal() { 3 int Vexnum = 0; 4 int edge = 0; 5 while (!check(Vexnum, edge)) { 6 cout << "图的顶点数和边数不合法,重新输入:" << endl; 7 cin >> Vexnum >> edge; 8 } 9 10 //声明一个边集数组 11 Edge * edge_tag; 12 //输入每条边的信息 13 createGraph(edge_tag, Vexnum, edge); 14 15 int * parent = new int[Vexnum]; //记录每个顶点所在子树的根节点下标 16 int * child = new int[Vexnum]; //记录每个顶点为根节点时,其有的孩子节点的个数 17 int i; 18 for (i = 0; i < Vexnum; i++) { 19 parent[i] = i; 20 child[i] = 0; 21 } 22 //对边集数组进行排序,按照权重从小到达排序 23 qsort(edge_tag, edge, sizeof(Edge), cmp); 24 int count_vex; //记录输出的边的条数 25 26 count_vex = i = 0; 27 while (i != edge) { 28 //如果两颗树可以组合在一起,说明该边是生成树的一条边 29 if (union_tree(edge_tag[i], parent, child)) { 30 cout << ("v" + std::to_string(edge_tag[i].start)) 31 << "-----" 32 << ("v" + std::to_string(edge_tag[i].end)) 33 <<"=" 34 << edge_tag[i].weight 35 << endl; 36 edge_tag[i].visit = true; 37 ++count_vex; //生成树的边加1 38 } 39 //这里表示所有的边都已经加入成功 40 if (count_vex == Vexnum - 1) { 41 break; 42 } 43 ++i; 44 } 45 46 if (count_vex != Vexnum - 1) { 47 cout << "非连通图,无法构成最小生成树。" << endl; 48 } 49 delete [] edge_tag; 50 delete [] parent; 51 delete [] child; 52 }
作业的一些关于最小生成树算法的小题,要对两种算法的实现逻辑和原理都要理解到位,以及得到最小生成树的过程要熟练。
因为第六章的内容很多,还有一些要点课程上没有安排,所以还要课下自己找时间去了解消化一下。
关于作业代码题:列出连通集
1 /*给定一个有N个顶点和E条边的无向图,请用DFS和BFS分别列出其所有的连通集。假设顶点从0到N−1编号。进行搜索时,假设我们总是从编号最小的顶点出发,按编号递增的顺序访问邻接点。 */ 2 #include <cstdio> 3 #include <queue> 4 #include <iostream> 5 using namespace std; 6 #define MAX 10 7 int a[MAX][MAX], dfs_visited[MAX], bfs_visited[MAX], N, E; //dfs_visited数组表示dfs 8 queue<int> q; 9 void dfs(int c) 10 { 11 dfs_visited[c] = 1; //1表示访问过了 12 cin >> c; 13 for(int i = 0; i < N; i++) 14 if(a[c][i] && !dfs_visited[i]) //利用二维数组的一行就是该节点的邻接点,如果那个邻接点还没没访问过则递归访问 15 dfs(i); 16 } 17 void bfs(int c) 18 { 19 bfs_visited[c] = 1; //1表示访问过了 20 q.push(c); 21 cout << c; 22 while(!q.empty()) 23 { 24 //如果队列不空则每次从队列中取出一个节点找出该节点的第一层bfs节点,并加入队列中 25 int temp = q.front(); 26 q.pop(); 27 for(int i = 0; i < N; i++) 28 {//找出第一层bfs的节点,依次输出并加入队列,跟树的层次遍历很像 29 if(a[temp][i] && !bfs_visited[i]){ 30 cout << i; 31 bfs_visited[i] = 1; 32 q.push(i); 33 } 34 } 35 } 36 } 37 int main() 38 { 39 int temp1, temp2; 40 cin >> N >> E; 41 for(int i = 0; i < E; i++) 42 { 43 cin >> temp1 << temp2; 44 a[temp1][temp2] = 1; //因为是无向图所有邻接矩阵是关于主对角线对称的 45 a[temp2][temp1] = 1; 46 } 47 for(int i = 0; i < N; i++) 48 { 49 if(!dfs_visited[i]) 50 { 51 cout << "{" ; 52 dfs(i); 53 cout << "{" ; 54 } 55 } 56 57 for(int i = 0; i < N; i++) 58 { 59 if(!bfs_visited[i]) 60 { 61 cout << "{" ; 62 bfs(i); 63 cout << "{" ; 64 } 65 } 66 return 0; 67 }
实践题代码稍有一点坑,还在修改,大概的思路就是对于每个点,用struct去定义存储结构,存x、y坐标、能到的点的编号、能到达点的数目、能否为起点、能否为终点。输入x、y坐标点后,扫描所有的点,选择能起跳的点,判断能否作为起点,以及能否作为终点。最特殊情况下,判断可跳距离大于最大42.5时,可直接跳出矩形。
1 #include <iostream> 2 #include <cstdio> 3 #include <cmath> 4 #define max 102 5 using namespace std; 6 7 struct danger 8 { 9 int x,y; 10 };//定义一个结构体存放每个顶点的坐标 11 12 danger p[max]; //定义一个结构体数组来存放所有的点 13 bool visit[max]={false}; 14 //定义一个全局变量来记录每个点是否已经去过 15 int n,l; 16 17 double dis(danger a,danger b) 18 {//计算两个点之间的距离,注意添加头文件 19 return sqrt(pow((a.x-b.x),2)+pow((a.y-b.y),2)); 20 } 21 void DFS(int v) 22 {//就是dfs遍历 23 visit[v]=true;//已经走过这个点就标记一下 24 if(abs(50-p[v].x)<=l || abs(50-p[v].y)<=l) 25 { 26 //如果这个点到边缘的距离是可以跳过去的(往上下左右方向,不是点到点的距离哦) 27 cout<<"Yes"; 28 exit(0) ;//程序结束输出yes 29 } 30 else 31 {//否则就找下一个能跳的点 32 for(int i=0;i<n;i++) 33 {//所有的点都遍历一遍 34 if(!visit[i] && (dis(p[i],p[v])<=l)) 35 DFS(i); 36 //如果有顶点没去过而且还可以跳过去的话就从那个点开始重新找下一个点 37 } 38 } 39 } 40 int main() 41 { 42 int num=0; 43 int first[max]; 44 danger ori; 45 cin>>n>>l; 46 for(int i=0;i<n;i++) 47 {//接收输入数据 48 cin>>p[i].x>>p[i].y; 49 } 50 ori.x=ori.y=0; 51 for(int i=0;i<n;i++) 52 {//首先先算一下第一次能跳的点有多少个 53 if(dis(p[i],ori)<=l+7.5) 54 { 55 first[num++]=i; 56 } 57 } 58 if(num==0) 59 {//如果第一次都没有可以跳的点就直接是no了 60 cout<<"No"; 61 return 0; 62 } 63 for(int i=0;i<num;i++) 64 {//否则就从这么点开始试试每一条路径 65 DFS(first[i]); 66 } 67 cout<<"No"; 68 }
参考链接:http://www.cnblogs.com/jingjing1234/p/10885498.html
其实现在老师安排的小测可以提高对课程要点的掌握,找到自己知识点的错漏,及时理解,以及加深理解一些知识点的区别和应用。第六章的内容真的很多,要总结起来的话还有好多需要列出来,所以还要另找时间好好的追究一下课本的内容。快到期末了,也要开始对之前内容的复习以及将前面的内容和新的知识充分融合运用起来。总感觉好像开学没多久,现在就一个学期的网课也快结束了,是一个安静的毕业季啊。
翻译 朗读 复制 正在查询,请稍候…… 重试 朗读 复制 复制 朗读 复制 via 谷歌翻译(国内)译
标签:arc format iostream 课程 最小 splay style -- 邻接
原文地址:https://www.cnblogs.com/apiao127/p/13114748.html
