标签:目标 标签 次数 family 不同的 style model 也有 RKE
目录
一句话简介:doc2vec(又叫Paragraph Vector)是google的两位大牛Quoc Le和Tomas Mikolov在2014年提出的,是一种非监督式算法,可以获得 sentences/paragraphs/documents 的向量表达,是 word2vec 的拓展。类似有PV-DM和PV-DBOW两种方式。
? ?
一、Doc2vec简介
(阅读本文前,建议读NLP系列的另一篇:Word2vec)学出来的向量可以通过计算距离来找 sentences/paragraphs/documents 之间的相似性,可以用于文本聚类,对于有标签的数据,还可以用监督学习的方法进行文本分类,例如经典的情感分析问题。和word2vec一样,Doc2vec也有两种训练方式,一种是PV-DM(Distributed Memory Model of paragraph vectors段落向量的分布式记忆的版本)类似于word2vec中的CBOW模型,另一种是PV-DBOW(Distributed Bag of Words of paragraph vector 段落向量的分布式词袋版本)类似于word2vec中的skip-gram模型
二、Doc2vec模型
2.1 PV-DM
类似于word2vec中的CBOW模型。
doc2vec的目标是创建文档的向量化表示,而不管其长度如何。 但与单词不同的是,文档并没有单词之间的逻辑结构,因此必须找到另一种方法。Mikilov和Le使用的概念很简单但很聪明:他们使用了word2vec模型,并添加了另一个向量(下面的段落ID),如下所示(图的来源也是CBOW类似):
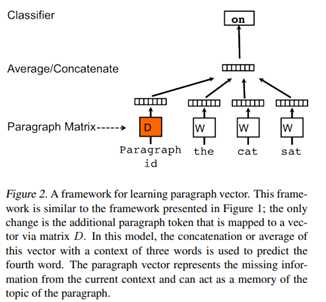
相比于word2vec的c-bow模型,区别点有:
? 训练过程中新增了paragraph id,即训练语料中每个句子都有一个唯一的id。paragraph id和普通的word一样,也是先映射成一个向量,即paragraph vector。paragraph vector与word vector的维数虽一样,但是来自于两个不同的向量空间。在之后的计算里,paragraph vector和word vector累加或者连接起来,作为输出层softmax的输入。在一个句子或者文档的训练过程中,paragraph id保持不变,共享着同一个paragraph vector,相当于每次在预测单词的概率时,都利用了整个句子的语义。
? 在预测阶段,给待预测的句子新分配一个paragraph id,词向量和输出层softmax的参数保持训练阶段得到的参数不变,重新利用梯度下降训练待预测的句子。待收敛后,即得到待预测句子的paragraph vector。
2.2 PV-DBOW
类似于word2vec中的skip-gram模型
还有一种训练方法是忽略输入的上下文,让模型去预测段落中的随机一个单词。就是在每次迭代的时候,从文本中采样得到一个窗口,再从这个窗口中随机采样一个单词作为预测任务,让模型去预测,输入就是段落向量。如下所示:
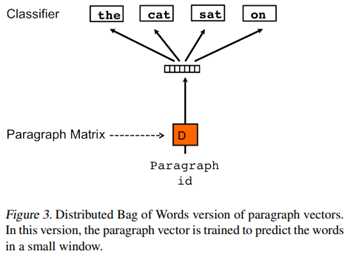
2.3 小结
在上述两种方法中,我们可以使用PV-DM或者PV-DBOW得到段落向量/句向量。对于大多数任务,PV-DM的方法表现很好,但我们也强烈推荐两种方法相结合。
在论文中,作者建议使用两种算法的组合,尽管PV-DM模型是优越的,并且通常会自己达到最优的结果。
doc2vec模型的使用方式:对于训练,它需要一组文档。 为每个单词生成词向量W,并为每个文档生成文档向量D. 该模型还训练softmax隐藏层的权重。 在推理阶段,可以呈现新文档,并且固定所有权重以计算文档向量。
注意:与word2Vec的名称和图片貌似有点区别。
三、Doc2Vec主要参数详解
D2V 的API:
model_dm = Doc2Vec(x_train,min_count=1, window = 3, size = size, sample=1e-3, negative=5, workers=4)
参数:
min_count:忽略所有单词中单词频率小于这个值的单词。
window:窗口的尺寸(句子中当前和预测单词之间的最大距离)
size:特征向量的维度
sample:高频词汇的随机降采样的配置阈值,默认为1e-3,范围是(0,1e-5)。
negative: 如果>0,则会采用negativesampling,用于设置多少个noise words(一般是5-20)。默认值是5。
workers:用于控制训练的并行数。
model_dm.train(x_train, total_examples=model_dm.corpus_count, epochs=70)
total_examples:统计句子数
epochs:在语料库上的迭代次数(epochs)。
三、总结
Doc2vec是基于Word2vec基础上构建的,相比于Word2vec,Doc2vec不仅能训练处词向量还能训练处句子向量并预测新的句子向量:在输入层上多增加了一个Paragraph vector句子向量,该向量在同一句下的不同的训练中是权值共享的,这样训练出来的Paragraph vector就会逐渐在每句子中的几次训练中不断稳定下来,形成该句子的主旨。这样就训练出来了我们需要的句子向量。
在预测新的句子向量时,是需要重新训练的,此时该模型的词向量和投影层到输出层的soft weights参数固定,只剩下Paragraph vector用梯度下降法求得,所以预测新句子时虽然也要放入模型中不断迭代求出,相比于训练时,速度会快得多。
优点:
缺点:
参考文献
【1】论文:https://cs.stanford.edu/~quocle/paragraph_vector.pdf https://arxiv.org/pdf/1405.4053.pdf
【2】原理及实践 https://blog.csdn.net/u010417185/article/details/80654558
标签:目标 标签 次数 family 不同的 style model 也有 RKE
原文地址:https://www.cnblogs.com/yifanrensheng/p/13143979.html