标签:页面 访问 通过 流程 清理 nes url 提取 数据
简述:爬取整个网站级别等需求复杂的爬虫,可以使用Scrapy框架。并发性好,速度快。
构成:
5+2结构
1. Engine模块
作用:1. 控制所有模块(2,3,4,5,a,b)之间的数据流 2. 根据条件来触发事件
a. Downloader Middleware(Downloader模块和engine模块之间的中间键)
作用:1. 可以通过此中间键,对spiders发来的请求进行修改,丢弃,新增等操作
2. 对Downloader下载到的数据进行修改,丢弃,新增等操作
2. Downloader模块
作用: 根据 (4--1--3--1--2) ,下载请求的页面数据
3. Scheduler模块
作用:对所有爬取请求进行调度 (4--1--3) ,管理
4. Spiders 模块
作用: 1. 提供最初始访问链接 2. 解析Downloader返回的响应 3. 提取响应中的:数据 + 新的url 4. 产生新的爬取请求
5. Item Pipelines模块
作用: 处理Spiders提取的数据(清理、检验、查重、保存)
流程图: 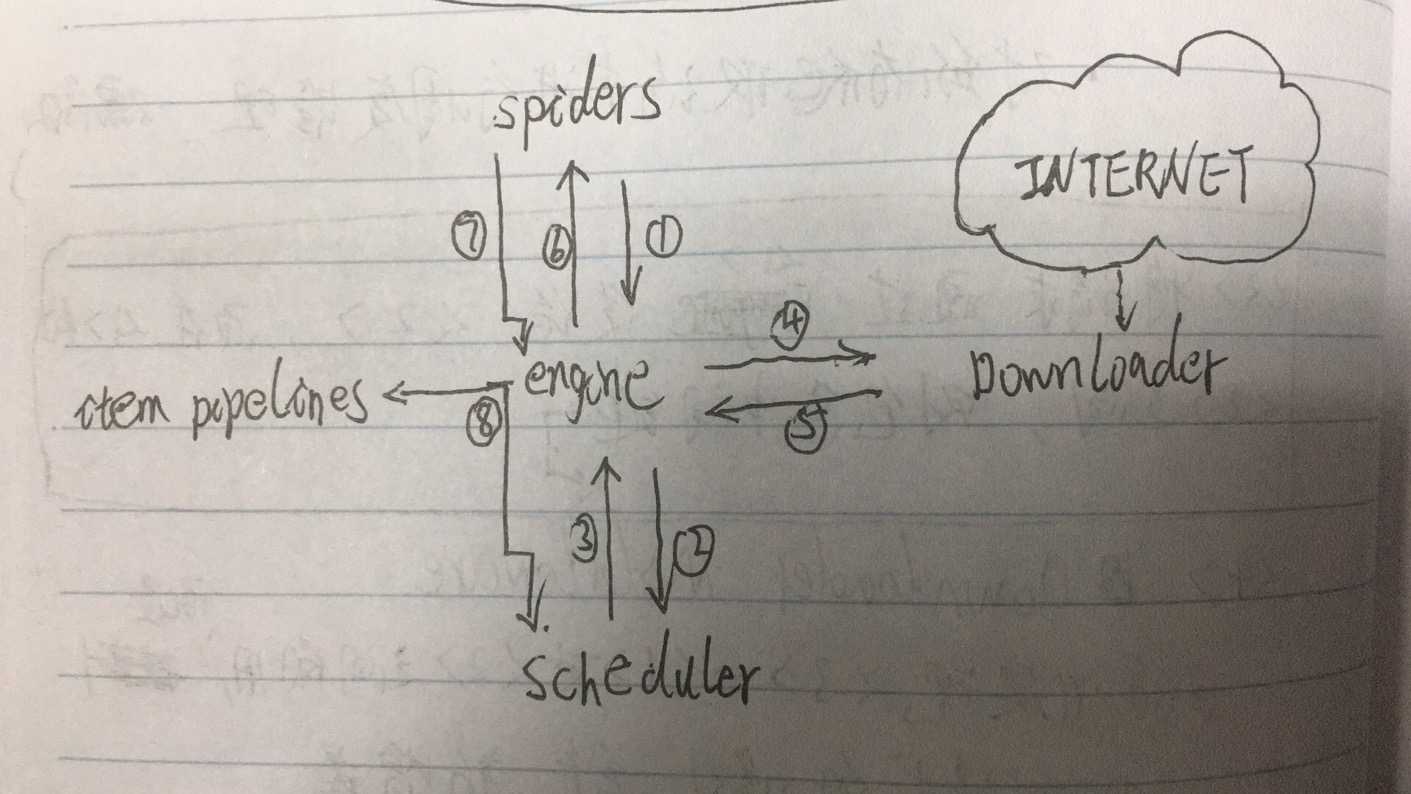
标签:页面 访问 通过 流程 清理 nes url 提取 数据
原文地址:https://www.cnblogs.com/leafchen/p/13143698.html