标签:参考文献 条件 embed 图片 相关 target 梯度下降 and 缺点
一句话简述:2013年Google发明,使用跳字节模型(skip-gram)或连续词袋模型(continuous bag of words ,CBOW)训练词向量(初始位one-hot),得到嵌入词向量。对比one-hot,大大压缩了词向量表示的维度,同时增加了语义表达。并采用负采样(negative sampling)和层次softmax(hierarchical softmax)优化计算速度。
? ?
在word2vec出现之前,自然语言处理经常把字词转为one-hot编码类型的词向量,这种方式虽然非常简单易懂,但是数据稀疏性非常高,维度很多,很容易造成维度灾难,尤其是在深度学习中;其次这种词向量中任意两个词之间都是孤立的,存在语义鸿沟(因为任何one-hot编码乘积为0,这样就不能体现词与词之间的关系,如下图所示)而有Hinton大神提出的Distributional Representation 很好的解决了one-hot编码的主要缺点。解决了语义之间的鸿沟,可以通过计算向量之间的距离来体现词与词之间的关系。Distributional Representation 词向量是密集的。word2vec是一个用来训练Distributional Representation 类型的词向量的一种工具。

说明:Distributed representation可以解决One hot representation的问题,它的思路是通过训练,将每个词都映射到一个较短的词向量上来。所有的这些词向量就构成了向量空间,进而可以用普通的统计学的方法来研究词与词之间的关系。这个较短的词向量维度是多大呢?这个一般需要我们在训练时自己来指定。


很明显,用上下文来表示中间向量,这种分布式表达方式比one-hot形式能更好反映出不同词但意思相近词的关系。可视化形式更加明显,如下图所示:

主要来源于Mikolov et al. 2013的一篇论文,例如,用中心词去表示周边词语:
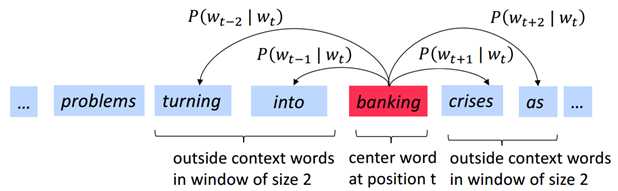
想法:使用概率来表示中心词出现时周边词出现的可能性,再用最大似然函数求出最大的可能性
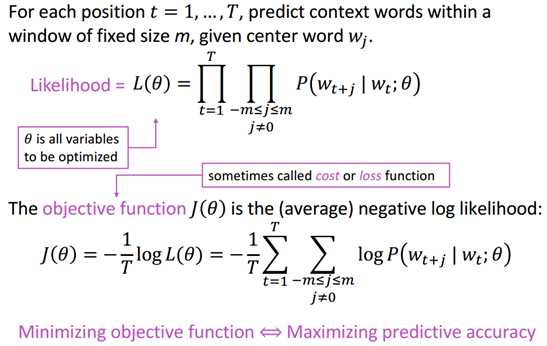
实际就是求参数θ的过程,那怎么去计算这个表达式呢:
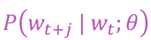
我们使用了向量相乘的方式来进行处理:

O(output)表示周边词,c(center)表示中心词,T表示所在位置,U和V都表示词向量。这种形式就是softmax的模型
(两个好处:1.所有的概率值都是正数了 ;2.概率之和为1)。
接下来我们用梯度下降的方式求解参数,注意每个单词有两个向量,一个输入一个输出:
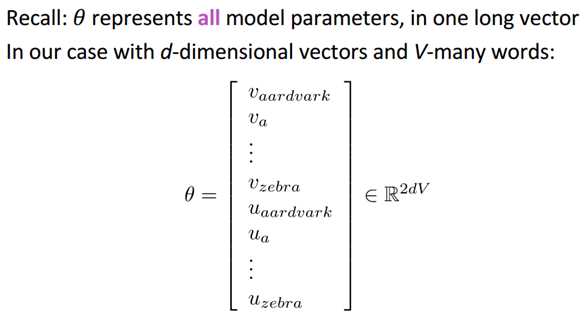
通过上述步骤,求出θ,再用θ表示出词向量,即得到所求。
word2vec模型其实就是简单化的神经网络,主要包含两种词训练模型:CBOW(Continuous Bag-of-Words)模型和Skip-gram模型。模型的结构图如下(注意:这里只是模型结构,并不是神经网络的结构)
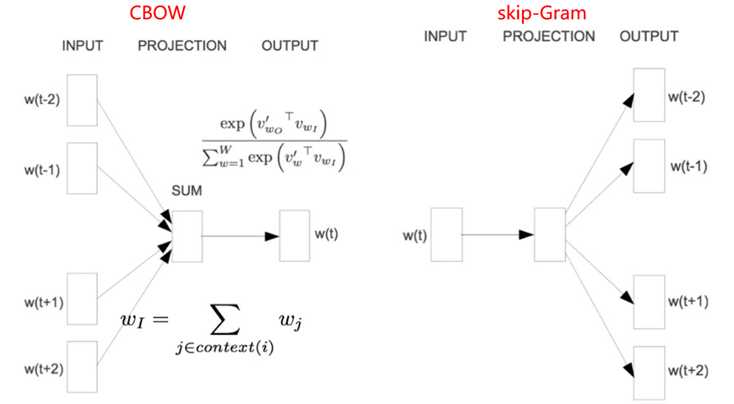
CBOW模型根据中心词W(t) 周围的词来预测中心词;Skip-gram模型则根据中心词W(t) 来预测周围的词。
1)输入层是上下文的词语的词向量,在训练CBOW模型,词向量只是个副产品,确切来说,是CBOW模型的一个参数。训练开始的时候,词向量是个随机值,随着训练的进行不断被更新) 。
投影层对其求和,所谓求和,就是简单的向量加法。
输出层输出最可能的w。由于语料库中词汇量是固定的|C|个,所以上述过程其实可以看做一个多分类问题。给定特
征,从|C|个分类中挑一个.输出值的维度和输入值的维度是一致的。
2)Skip-gram模型的第一层是输入层,输入值是中心词的one-hot编码形式,隐藏层只是做线性转换,输出的是输出值的softmax转换后的概率。
神经网络结构如下
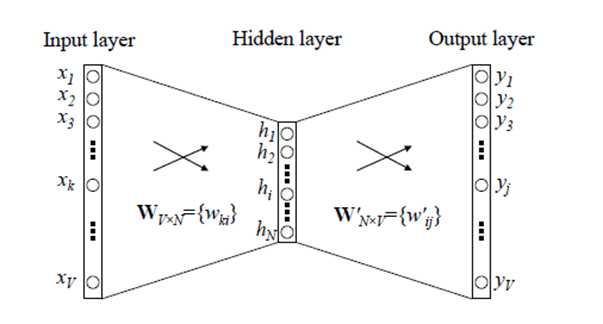
神经网络的训练是有监督的学习,因此要给定输入值和输出值来训练神经网络,而我们最终要获得的是隐藏层的权重矩阵。
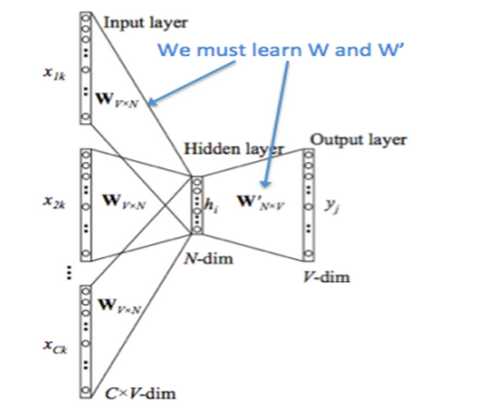
所以,需要定义loss function(一般为交叉熵代价函数),采用梯度下降算法更新W和W‘。训练完毕后,输入层的每个单词与矩阵W相乘得到的向量的就是我们想要的词向量(word embedding),这个矩阵(所有单词的word embedding)也叫做look up table(其实这个look up table就是矩阵W自身),也就是说,任何一个单词的onehot乘以这个矩阵都将得到自己的词向量。有了look up table就可以免去训练过程直接查表得到单词的词向量了,而且得到的还是一个稠密的词向量。
更细节地(涉及重要数学公式):
参数说明:U 和 V 最初为随机向量矩阵。

最小化目标函数:
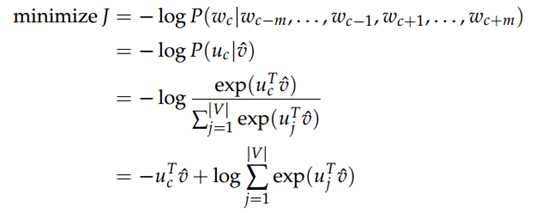
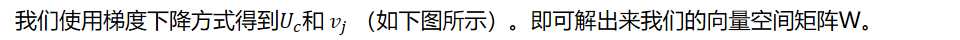
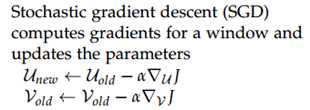
具体流程如下:

损失函数如下:
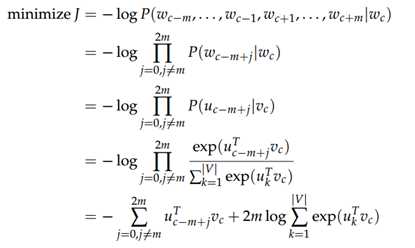
跳字模型的核心在于使用softmax运算得到给定中心词 wc 来生成背景词 wo 的条件概率
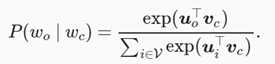
该条件概率相应的对数损失
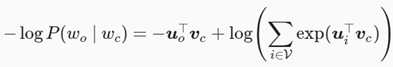
考虑到sofmax归一化需要遍历整个词汇表(上面式子也能看出,要遍历V),不论是跳字模型还是连续词袋模型,由于条件概率使用了softmax运算,每一步的梯度计算都包含词典大小数目的项的累加。对于含几十万或上百万词的较大词典,每次的梯度计算开销可能过大。为了降低该计算复杂度,本节将介绍两种近似训练方法,即负采样(negative sampling)或层序softmax(hierarchical softmax)。由于跳字模型和连续词袋模型类似,本节仅以跳字模型为例介绍这两种方法。

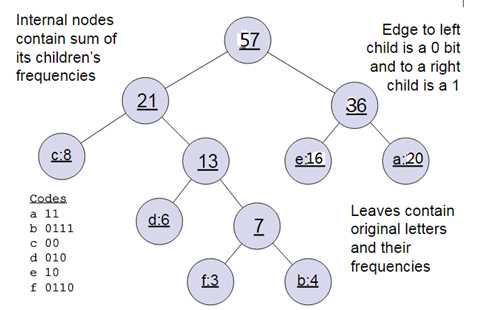
哈夫曼树说明:一般得到哈夫曼树后我们会对叶子节点进行哈夫曼编码,由于权重高的叶子节点越靠近根节点,而权重低的叶子节点会远离根节点,这样我们的高权重节点编码值较短,而低权重值编码值较长。这保证的树的带权路径最短,也符合我们的信息论,即我们希望越常用的词拥有更短的编码。如何编码呢?一般对于一个霍夫曼树的节点(根节点除外),可以约定左子树编码为0,右子树编码为1.如上图,则可以得到c的编码是00。
在源代码中,基于Hierarchical Softmax的CBOW模型算法在435-463行,基于Hierarchical Softmax的Skip-Gram的模型算法在495-519行。大家可以对着源代码再深入研究下算法。具体讲解如下:
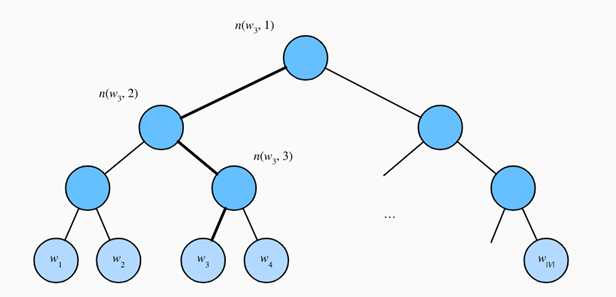
假设L(w)为从二叉树的根结点到词w的叶结点的路径(包括根结点和叶结点)上的结点数。设n(w,j)为该路径上第j个结点,并设该结点的背景词向量为un(w,j)。以图为例,L(w3)=4。层序softmax将跳字模型中的条件概率近似表示为
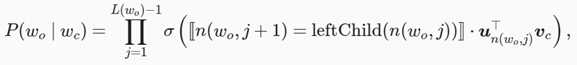
leftChild(n) 是结点 n 的左子结点:如果判断 x 为真, [[x]]=1 ;反之 [[x]]=?1 。 让我们计算图10.3中给定词 wc 生成词 w3 的条件概率。我们需要将 wc 的词向量 vc 和根结点到 w3 路径上的非叶结点向量一一求内积。由于在二叉树中由根结点到叶结点 w3 的路径上需要向左、向右再向左地遍历(图中加粗的路径),我们得到
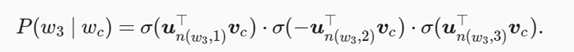
可以看出对应的开销为L(W),是V的对数级别。
在讲基于Negative Sampling的word2vec模型前,我们先看看Hierarchical Softmax的的缺点。的确,使用霍夫曼树来代替传统的神经网络,可以提高模型训练的效率。但其缺陷也很明显:
能不能不用搞这么复杂的一颗霍夫曼树,将模型变的更加简单呢?Negative Sampling就是这么一种求解word2vec模型的方法,Negative Sampling的求解思路(摒弃了霍夫曼树)。
负采样修改了原来的目标函数。给定中心词 wc 的一个背景窗口,我们把背景词 wo 出现在该背景窗口看作一个事件,并将该事件的概率计算为
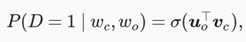
D=1表示同时出现,D=0表示不是同时出现。σ为sigmoid函数,我们先考虑最大化文本序列中所有该事件的联合概率来训练词向量。具体来说,给定一个长度为 T 的文本序列,设时间步 t 的词为 w(t) 且背景窗口大小为 m ,考虑最大化联合概率
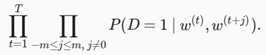
然而,以上模型中包含的事件仅考虑了正类样本。这导致当所有词向量相等且值为无穷大时,以上的联合概率才被最大化为1。很明显,这样的词向量毫无意义。负采样通过采样并添加负类样本使目标函数更有意义。设背景词 w_o 出现在中心词 wc 的一个背景窗口为事件 P ,我们根据分布 P(w) 采样 K 个未出现在该背景窗口中的词,即噪声词。设噪声词 w_k ( k=1,…,K )不出现在中心词 w_c 的该背景窗口为事件 N_k 。假设同时含有正类样本和负类样本的事件 P,N1,…,NK 相互独立,负采样将以上需要最大化的仅考虑正类样本的联合概率改写为:
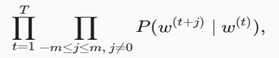
其中条件概率被近似表示为
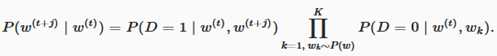
设文本序列中时间步 t 的词 w^(t) 在词典中的索引为 i_t ,噪声词 w_k 在词典中的索引为 h_k 。有关以上条件概率的对数损失为:
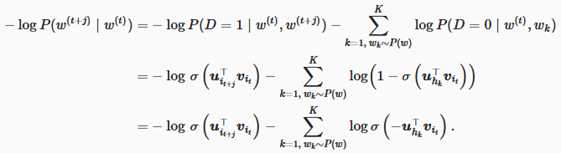
现在,训练中每一步的梯度计算开销不再与词典大小相关,而与 K 线性相关。当 K 取较小的常数时,负采样在每一步的梯度计算开销较小。
在源代码中,基于Negative Sampling的CBOW模型算法在464-494行,基于Negative Sampling的Skip-Gram的模型算法在520-542行。有空再对着源代码再深入研究下算法。
gensim的python版word2vec来使用word2vec解决实际问题。
1)降低输入的维度。词向量的维度一般取100-200,对于大样本时的one-hot向量甚至可能达到10000以上。
2)增加语义信息。两个语义相近的单词的词向量也是很相似的。
gensim是一个很好用的Python NLP的包,不光可以用于使用word2vec,还有很多其他的API可以用。它封装了google的C语言版的word2vec。当然我们可以可以直接使用C语言版的word2vec来学习,但是个人认为没有gensim的python版来的方便。
安装gensim是很容易的,使用"pip install gensim"即可。但是需要注意的是gensim对numpy的版本有要求,所以安装过程中可能会偷偷的升级你的numpy版本。而windows版的numpy直接装或者升级是有问题的。此时我们需要卸载numpy,并重新下载带mkl的符合gensim版本要求的numpy。
在gensim中,word2vec 相关的API都在包gensim.models.word2vec中。和算法有关的参数都在类gensim.models.word2vec.Word2Vec中。算法需要注意的参数有:
官方API介绍如下:
class gensim.models.word2vec.Word2Vec(sentences=None, corpus_file=None, size=100, alpha=0.025, window=5, min_count=5, max_vocab_size=None, sample=0.001, seed=1, workers=3, min_alpha=0.0001, sg=0, hs=0, negative=5, ns_exponent=0.75, cbow_mean=1, hashfxn=<built-in function hash>, iter=5, null_word=0, trim_rule=None, sorted_vocab=1, batch_words=10000, compute_loss=False, callbacks=(), max_final_vocab=None)
当训练完模型之后,我们就可以用模型来处理一些常见的问题了,主要包括以下三个方面:
model.wv.similar_by_word()
从这里可以衍生出去寻找相似的句子,比如"北京下雨了",可以先进行分词为{"北京","下雨了"},然后找出每个词的前5或者前10个相似的词,比如"北京"的前五个相似词是
{"上海", "天津","重庆","深圳","广州"}
"下雨了"的前五个相似词是
{"下雪了","刮风了","天晴了","阴天了","来台风了"}
然后将这两个集合随意组合,可以得到25组不同的组合,然后找到这25组中发生概率最大的句子输出。
model.wv.similarity()
比如查看"北京"和"上海"之间的相似度
model.wv.doesnt_match()
比如找出集合{"上海", "天津","重庆","深圳","北京"}中不同的类别,可能会输出"深圳",当然也可能输出其他的
【1】论文:
https://arxiv.org/pdf/1310.4546.pdf :
Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg S Corrado, and Jeff Dean. 2013. Distributed representations
of words and phrases and their compositionality.In NeurIPS, pages 3111–3119.
https://arxiv.org/pdf/1301.3781.pdf:
Mikolov T , Chen K , Corrado G , et al. Efficient Estimation of Word Representations in Vector Space[J]. Computer ence, 2013.
【2】详细的推导:
word2vec 中的数学原理详解 https://www.cnblogs.com/peghoty/p/3857839.html
word2vec原理(三) 基于Negative Sampling的模型 https://www.cnblogs.com/pinard/p/7249903.html
【3】CS224n课程
【4】动手学习深度学习 http://zh.d2l.ai/chapter_natural-language-processing/word2vec.html
标签:参考文献 条件 embed 图片 相关 target 梯度下降 and 缺点
原文地址:https://www.cnblogs.com/yifanrensheng/p/13143945.html