标签:odi 大量 ble check 吞吐量 wait keepaliv 阻塞队列 初始
线程池可以看做是线程的集合。在没有任务时线程处于空闲状态,当请求到来:线程池给这个请求分配一个空闲的线程,任务完成后回到线程池中等待下次任务(而不是销毁)。这样就实现了线程的重用。
我们来看看如果没有使用线程池的情况是这样的:
public class ThreadPerTaskWebServer {
public static void main(String[] args) throws IOException {
ServerSocket socket = new ServerSocket(80);
while (true) {
final Socket connection = socket.accept();
Runnable task = () -> handleRequest(connection);
new Thread(task).start();// 为每个请求都创建一个新的线程
}
}
private static void handleRequest(Socket connection) {
// request-handling logic here
}
}
为每个请求都开一个新的线程虽然理论上是可以的,但是会有缺点:所以说:我们的线程最好是交由线程池来管理,这样可以减少对线程生命周期的管理,一定程度上提高性能。
JDK给我们提供了Excutor框架来使用线程池,它是线程池的基础。
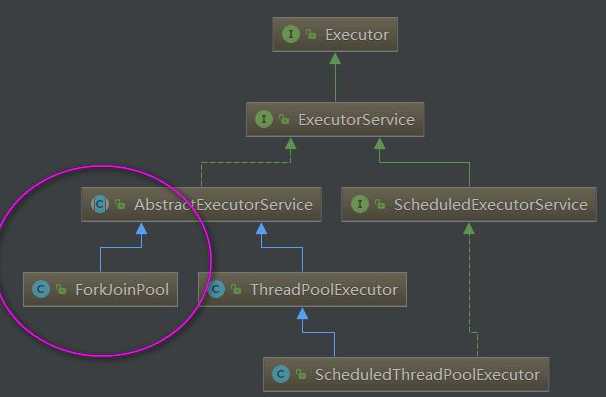
下面我们来看看JDK线程池的总体api架构:
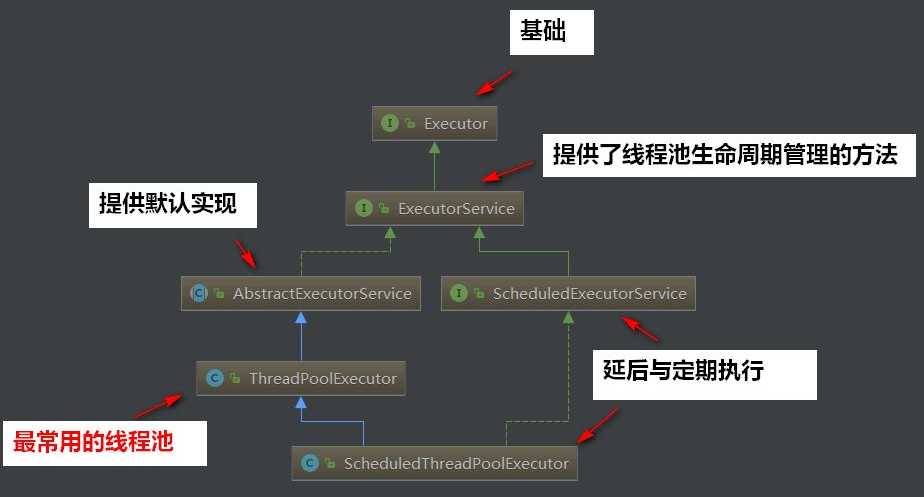
接下来我们把这些API都过一遍看看:
public interface Executor {
/**
* @param command the runnable task
* @throws RejectedExecutionException if this task cannot be accepted for execution
* @throws NullPointerException if command is null
*/
void execute(Runnable command);
}
//例如,相比较于使用如下代码
new Thread(new(RunnableTask())).start();
//对每个任务进行执行调用,我们可以使用Executor像下面的方案
Executor executor = getAnExecutor();
executor.execute(new RunnableTask1());
executor.execute(new RunnableTask2());class DirectExecutor implements Executor {
public void execute(Runnable r) {
r.run();
}
}class ThreadPerTaskExecutor implements Executor {
public void execute(Runnable r) {
new Thread(r).start();
}
}更多的Executor 实现对 任务如何以及何时执行 设定了一些限制。下面的executor将串行化任务提交到第二个executor,实现类复合executor。
class SerialExecutor implements Executor {
final Queue<Runnable> tasks = new ArrayDeque<Runnable>();
final Executor executor; //内部的第二个executor
Runnable active;
SerialExecutor(Executor executor) {
this.executor = executor;
}
public synchronized void execute(final Runnable r) {
tasks.offer(new Runnable() {
public void run() {
try {
r.run();
} finally {
scheduleNext(); //当前task执行完后,执行队列的下一个task
}
}
});
if (active == null) {
scheduleNext();
}
}
protected synchronized void scheduleNext() {
if ((active = tasks.poll()) != null) {
executor.execute(active);
}
}
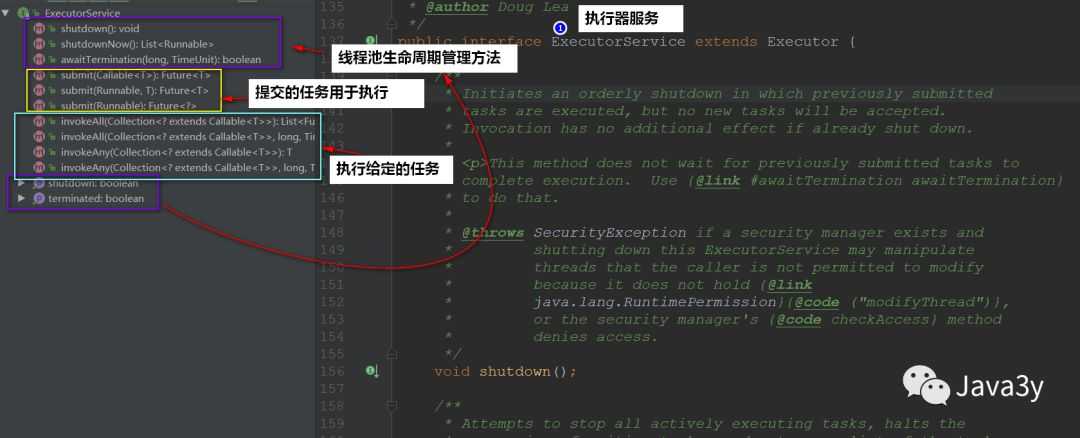
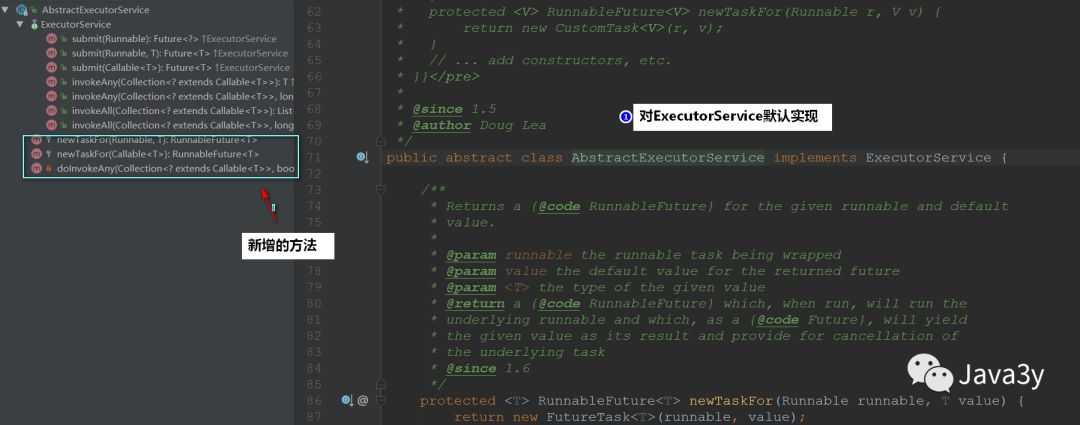
}ExecutorService ,这是一个更广泛的接口。 ThreadPoolExecutor类提供一个可扩展的线程池实现。 Executors工具类为这些Executor提供了便捷的工厂方法。
在线程T中提交task给executor, 在提交任务之前的action , happen-before 于task的执行,可能在其他的线程;
Actions in a thread prior to submitting a Runnable object to an Executor happen-before its execution begins, perhaps in another thread.
class NetworkService implements Runnable {
private final ServerSocket serverSocket;
private final ExecutorService pool;
public NetworkService(int port, int poolSize)
throws IOException {
serverSocket = new ServerSocket(port);
pool = Executors.newFixedThreadPool(poolSize);//使用Executors工具类的工厂方法获取到ExecutorService实例
}
public void run() { // run the service
try {
for (;;) { //循环等待请求进入
pool.execute(new Handler(serverSocket.accept()));
}
} catch (IOException ex) {
pool.shutdown();
}
}
}
class Handler implements Runnable {
private final Socket socket;
Handler(Socket socket) { this.socket = socket; }
public void run() {
// read and service request on socket
}
}
///////////////////////////////////////////////////////
//下面代码是停止所用任务的实现方案
void shutdownAndAwaitTermination(ExecutorService pool) {
pool.shutdown(); // Disable new tasks from being submitted
try {
// Wait a while for existing tasks to terminate
if (!pool.awaitTermination(60, TimeUnit.SECONDS)) {
pool.shutdownNow(); // Cancel currently executing tasks
// Wait a while for tasks to respond to being cancelled
if (!pool.awaitTermination(60, TimeUnit.SECONDS))
System.err.println("Pool did not terminate");
}
} catch (InterruptedException ie) {
// (Re-)Cancel if current thread also interrupted
pool.shutdownNow();
// Preserve interrupt status
Thread.currentThread().interrupt();
}
}
schedule(task, date.getTime() - System.currentTimeMillis(), TimeUnit.MILLISECONDS);import static java.util.concurrent.TimeUnit.*;
class BeeperControl {
private final ScheduledExecutorService scheduler = Executors.newScheduledThreadPool(1);
public void beepForAnHour() {
final Runnable beeper = new Runnable() {
public void run() { System.out.println("beep"); }
};
final ScheduledFuture<?> beeperHandle = scheduler.scheduleAtFixedRate(beeper, 10, 10, SECONDS);
scheduler.schedule(new Runnable() {
public void run() { beeperHandle.cancel(true); }
}, 60 * 60, SECONDS); //一个小时后取消
}
}
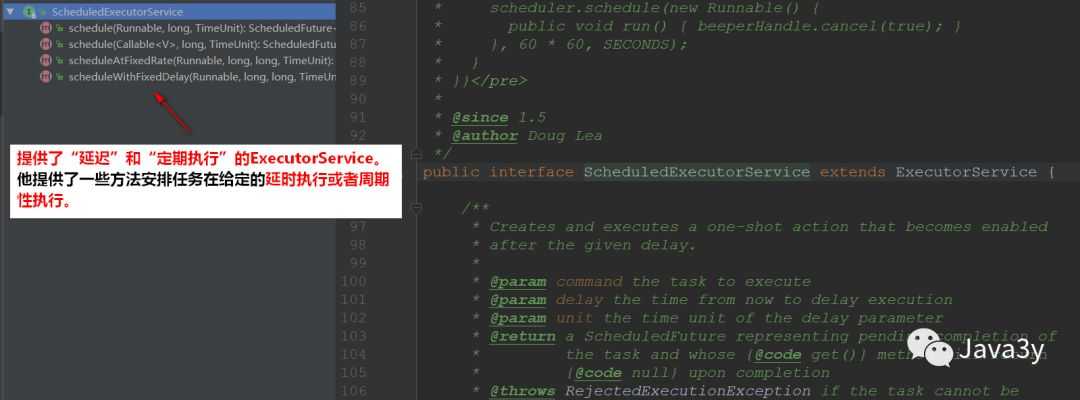
这个是用的最多的线程池类;详见本文第三部分
相当于 提供了 延迟执行 和 周期执行的 ThreadPoolExecutor类;
除了ScheduledThreadPoolExecutor和ThreadPoolExecutor类线程池以外,还有一个是JDK1.7新增的线程池:ForkJoinPool线程池
Callable就是Runnable的扩展。
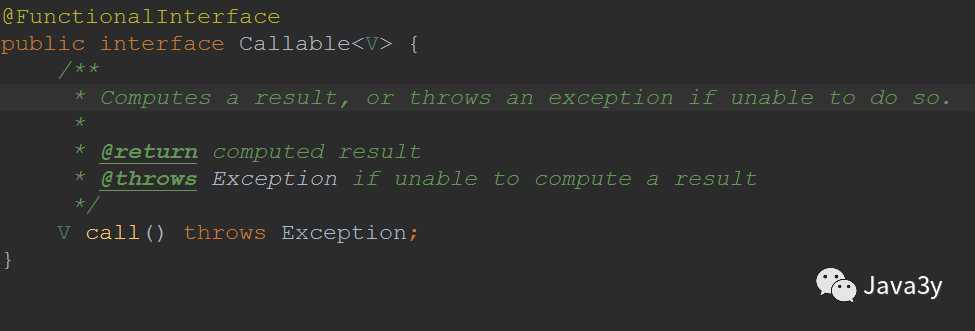
也就是说:当我们的任务需要返回值的时,我们就可以使用Callable!
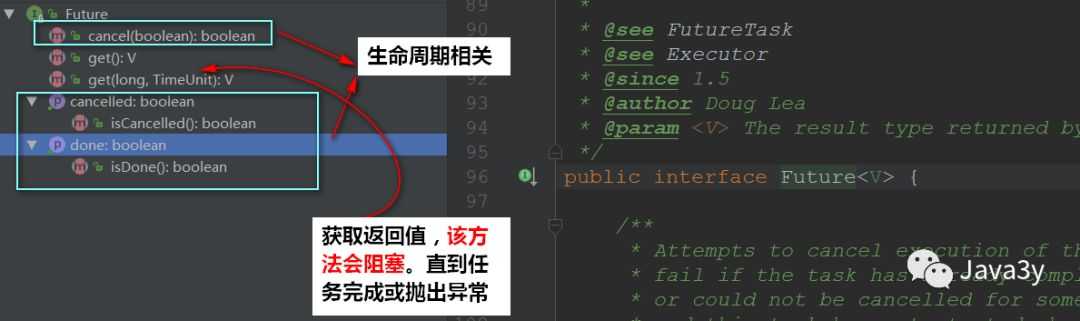
Future一般我们认为是Callable的返回值,但他其实代表的是任务的生命周期(当然了,它是能获取得到Callable的返回值的)
public class CallableDemo {
public static void main(String[] args) throws InterruptedException, ExecutionException {
// 创建线程池对象
ExecutorService pool = Executors.newFixedThreadPool(2);
// 可以执行Runnable对象或者Callable对象代表的线程
Future<Integer> f1 = pool.submit(new MyCallable(100));
Future<Integer> f2 = pool.submit(new MyCallable(200));
// V get()
Integer i1 = f1.get();
Integer i2 = f2.get();
System.out.println(i1 + " " + i2);
// 结束,关闭线程池
pool.shutdown();
}
}
//自定义的 task任务
public class MyCallable implements Callable<Integer> {
private int number;
public MyCallable(int number) {
this.number = number;
}
@Override
public Integer call() throws Exception {
int sum = 0;
for (int x = 1; x <= number; x++) {
sum += x;
}
return sum;
}
}

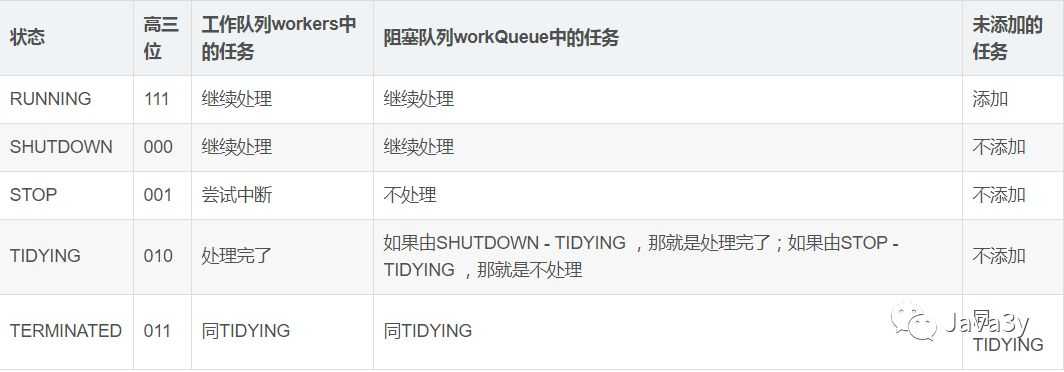
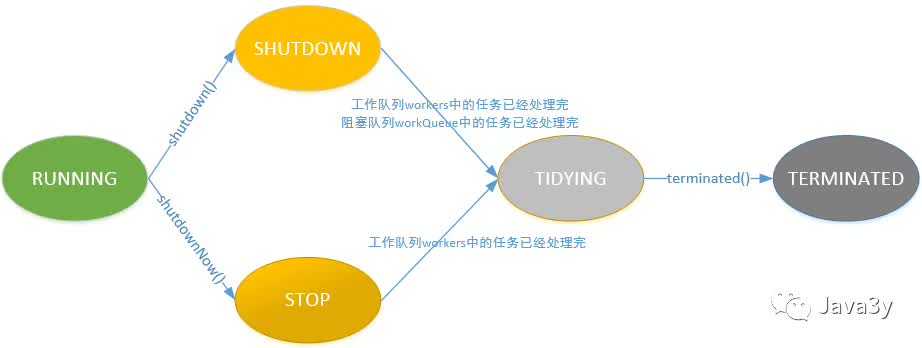
线程的状态:
/**
* @param corePoolSize :保留在池中的线程数,即使线程处于空闲状态也不回收,除非设置allowCoreThreadTimeOut属性为true
* @param maximumPoolSize:线程池中允许的最大线程数
* @param keepAliveTime:当线程数大于corePoolSize 时,这是多余的空闲线程 在终止之前 等待新任务的最长时间。
* @param unit : keepAliveTime参数的时间单位
* @param workQueue 在任务执行之前用于保留任务的队列。该队列仅保存由execute方法提交的Runnable任务。
* @param threadFactory: executor 创建新线程时要使用的线程工厂
* @param handler : 当线程数达到了线程上限,并且队列已经满了, 此时提交的execution被阻塞。handler就是发生该情况时要使用的处理程序。
*/
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException(); //参数不合法
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException(); //参数存在空指针异常
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}线程数量要点:
线程空闲时间要点:
排队策略要点:
当线程关闭或者线程数量满了和队列饱和了,就有拒绝任务的情况了:
拒绝任务策略:
下面我就列举三个比较常见的实现池:
如果读懂了上面对应的策略,线程数量这些,应该就不会太难看懂了。
使用Executors工具类中的newFixedThreadPool()方法,它将返回一个corePoolSize和maximumPoolSize相等的线程池。
//@param nThreads: the number of threads in the pool
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
} 非常有弹性的线程池,对于新的任务,如果此时线程池里没有空闲线程,线程池会毫不犹豫的创建一条新的线程去处理这个任务。
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}使用单个worker线程的Executor
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}execute执行方法分了三步,以注释的方式写在代码上了~
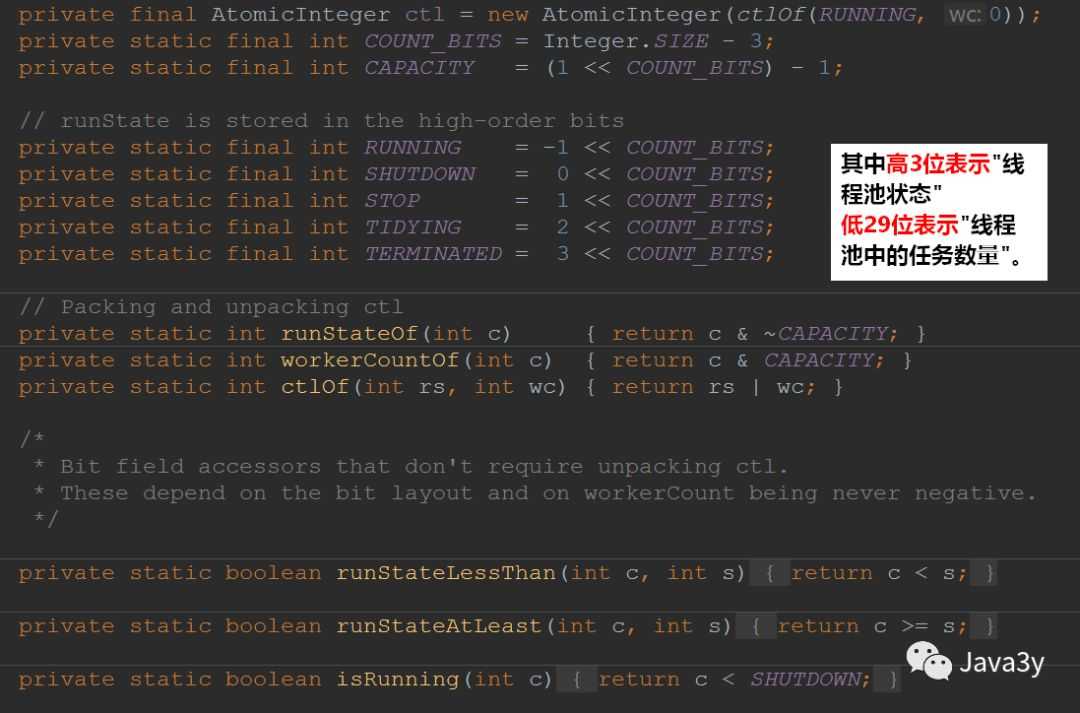
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
//如果线程池中运行的线程数量<corePoolSize,则创建新线程来处理请求,即使其他辅助线程是空闲的。
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true)) //创建新进程执行
return;
c = ctl.get();
}
//如果线程池中运行的线程数量>=corePoolSize,
if (isRunning(c) && workQueue.offer(command)) { //线程池处于RUNNING状态。把提交的任务成功放入阻塞队列中。
int recheck = ctl.get(); //就再次检查线程池的状态,因为现有的线程自上次检查后可能死亡
if (! isRunning(recheck) && remove(command)) //if线程池不是RUNNING状态,且成功从阻塞队列中删除任务,
reject(command); //则该任务由当前 RejectedExecutionHandler 处理。
else if (workerCountOf(recheck) == 0) //否则如果线程池中运行的线程数量为0,
addWorker(null, false); //通过addWorker(null, false)尝试新建一个线程,新建线程对应的任务为null。
}
// 如果以上两种case不成立,即没能将任务成功放入阻塞队列中,且addWoker新建线程失败,则该任务由当前 RejectedExecutionHandler 处理。
else if (!addWorker(command, false))
reject(command);
}ThreadPoolExecutor提供了shutdown()和shutdownNow()两个方法来关闭线程池
shutdown() :

shutdownNow():
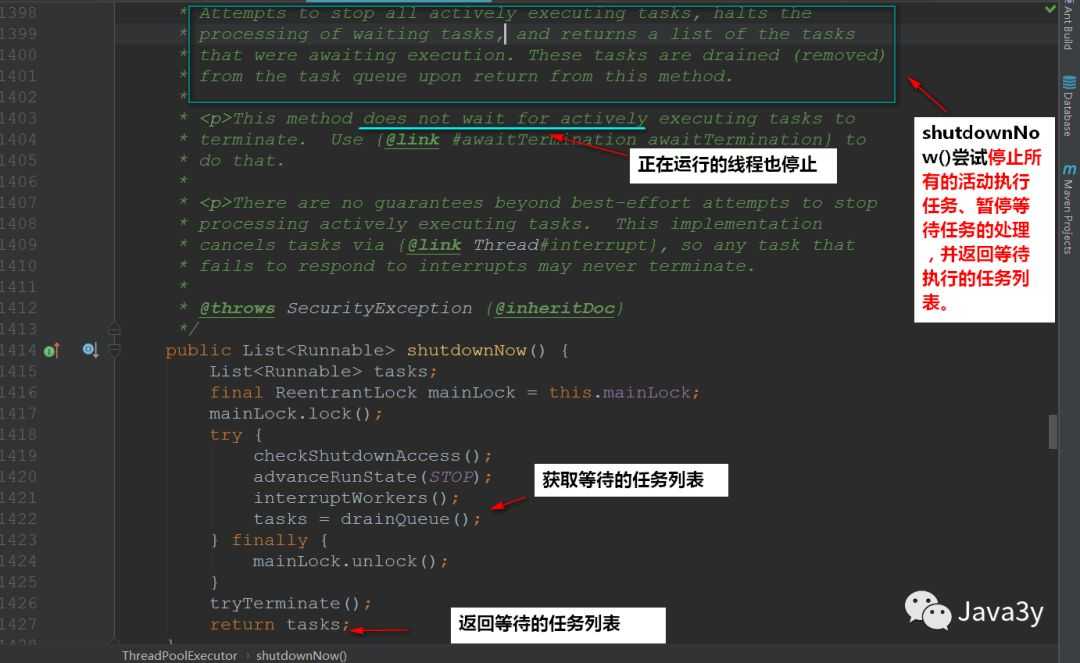
区别:
标签:odi 大量 ble check 吞吐量 wait keepaliv 阻塞队列 初始
原文地址:https://www.cnblogs.com/billxxx/p/13155417.html