标签:enc 分布式计算 示例 指定 演示 运行时 最新版本 重要 orm
如何运行具有奇点的NGC深度学习容器
How to Run NGC Deep Learning Containers with Singularity
高性能计算机和人工智能的融合使新的科学突破成为可能。现在需要在同一个系统上同时部署HPC和AI工作负载。
支持HPC和AI工作负载所需的软件环境的复杂性是巨大的。应用软件依赖于许多相互依赖的软件包。仅仅获得一个成功的构建是一个挑战,更不用说确保构建得到优化,以利用最新的硬件和软件功能。
容器是一种广泛采用的降低HPC和AI软件部署复杂性的方法。整个软件环境,从深度学习框架本身,到性能所必需的数学和通信库,都打包成一个包。由于容器中的工作负载总是使用相同的环境,因此性能是可复制和可移植的。
NGC是一个GPU优化软件的注册中心,通过提供定期更新和验证的HPC和AI应用程序容器,使科学家和研究人员受益匪浅。NGC最近宣布从19.11版开始,支持在Singularity容器运行时使用deep learning容器。这大大简化了使用奇点的HPC站点采用人工智能方法的过程。
这文说明了NGC和Singularity是如何极大地简化在HPC系统上部署深度学习工作负载的。
ResNet首次用于赢得2015年ImageNet比赛,至今仍是一种流行的图像分类模型,被广泛用作深度学习训练的基准。在几个简单的步骤中,将演示如何使用TensorFlow和ImageNet数据库中的图像训练ResNet-50v1.5模型。尽管目前ResNet模型的训练几乎是微不足道的,但这里所示的相同方法可以用于扩展更大模型的训练,也可以用于其深度学习框架。
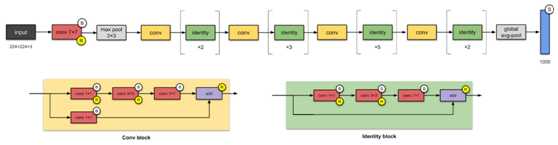
Figure 1: ResNet-50 architecture (source)
除了作为一个容器注册表,NGC还提供完整的人工智能工作流,包括预先训练的模型和脚本。一个例子是TensorFlow的ResNet-50v1.5模型;对于这个例子,严格遵循快速入门指南。 该示例使用Singularity版本3,并假设已经从集群资源管理器中获得了交互式节点分配。
1. 下载并提取ImageNet数据集,如《快速入门指南》的步骤2“下载数据”所述。请注意,ResNet-50的总体性能对用于存储映像的文件系统的性能敏感,因此总体性能将有所不同。在运行中,使用了一个本地SSD。
2.NGC TensorFlow 19.11容器映像已经包含ResNet-50模型脚本,位于/workspace/nvidia examples/resnet50v1.5中,所以使用了。或者,可以从NGC模型脚本页面下载模型脚本。 3. 使用奇点拉动NGC TensorFlow容器。这是一个简单的命令,可以作为非特权用户运行。(注意:如果IT管理员已经设置了NGC容器复制器,则TensorFlow容器可能已经位于系统中。)
$ singularity pull tensorflow-19.11-tf1-py3.sif docker://nvcr.io/nvidia/tensorflow:19.11-tf1-py3
4. 容器下载完成后,第四步也是最后一步是训练模型。让从使用一个GPU和FP16开始。NGC模型脚本页的Performance选项卡上的相应Python命令行需要包装在命令中,以启动在上一步中下载的Singularity容器图像。
$ singularity run --nv -B /local/imagenet:/data/imagenet pytorch-19.11-tf1-py3.sif python /workspace/nvidia-examples/resnet50v1.5/main.py --mode=training_benchmark --use_tf_amp --warmup_steps=200 --batch_size=256 --data_dir=/data/imagenet --results_dir=/tmp/resnet
使用了两个具有奇点的选项,-nv和-B。第一个选项,-nv在奇点中启用NVIDIA GPU支持。第二个,-B,bind将/local/imagenet目录挂载到提取imagenet数据库的主机上,挂载到容器中的/data/imagenet位置。修改此项以使用提取ImageNet数据库的位置。python命令取自1gpu/FP16案例的NGC模型脚本页面,只需稍作修改即可使用NGC容器中包含的模型脚本。
在运行中,使用Singularity获得了大约每秒980张图像,Docker的结果几乎相同,都使用了一个NVIDIA V100 GPU和19.11 TensorFlow NGC容器图像。
分布式计算是高性能计算的重要组成部分。像Horovod这样的框架支持分布式深度学习。TensorFlow NGC容器包括Horovod,以实现多节点的开箱即用训练。在本节中,将展示Singularity作为HPC容器运行时的起源如何使执行多节点训练变得容易。在这里,从集群资源管理器中分配了两个集群节点,每个节点都有4xV100 gpu。
使用Singularity扩展MPI工作负载的通常方法是使用容器外部的MPI运行时在容器实例内部启动分布式任务(也称为“outside in”或“hybrid”)。与运行本机MPI工作负载相比,此方法所需的更改最少,但确实需要主机上的MPI运行时与容器中的MPI库兼容。19.11 NGC TensorFlow映像捆绑了OpenMPI版本3.1.4,因此任何大于3.0的主机OpenMPI版本都应该可以工作,但是版本越接近匹配越好。
启动一个两节点的训练运行,每个节点使用4xgpu的奇点和NGC容器是很简单的。像往常一样使用mpirun并使用命令从上面启动Singularity容器。实际上,与上一个示例中的单个GPU命令行相比,唯一的区别是使用mpirun启动。
$ mpirun singularity run --nv -B /local/imagenet:/data/imagenet tensorflow-19.11-tf1-py3.sif python /workspace/nvidia-examples/resnet50v1.5/main.py --mode=training_benchmark --use_tf_amp --warmup_steps=200 --batch_size=256 --data_dir=/data/imagenet --results_dir=/tmp/resnet
注意:在这种情况下,主机上的MPI运行时可以识别资源管理器,因此不需要手动指定要启动多少MPI列组或如何放置。MPI运行时能够从交互式SLURM作业分配(srun--nodes 2--ntasks 8--pty--time=15:00bash-i)中推断出此信息。如果MPI运行时不是这样设置的,或者集群使用不同的资源管理器,则需要手动告诉MPI运行时使用两个节点,每个节点具有4个列组/GPU,例如mpirun-n 8--n per node 4--hostfile hostfile其中hostfile包含已分配的节点的名称,每行一个,或者mpirun-n 8-H node1:4,node2:4,用分配给节点的名称替换node1和node2。
应该注意到,在两个节点上已使用总共8个GPU(每个节点4个GPU)启动了8个训练任务。在使用的特定系统上,分布式训练性能大约为每秒6800个图像,相对于单个GPU,大约加速6.9倍。使用XLA(-use-XLA)和/或DALI(-use-DALI)可以进一步提高性能,这两个都包含在NGC容器图像中。
使用Singularity扩展MPI工作负载的另一种方法是在容器中使用MPI运行时(也称为“inside out”或“self-contained”)。这消除了对兼容主机MPI运行时的依赖,但需要额外的配置来手动指定作业的大小和形状,以及在容器中启动所有任务。这两种方法,以及优缺点,在网络研讨会“用奇点扩展NGC工作负载”中有更详细的描述。
前面的示例假设有一个交互式会话,但是也可以通过一个可以提交给资源管理器的作业脚本(例如,使用SLURM的sbatch)来部署训练。
#!/bin/bash
#SBATCH -J resnet50
#SBATCH -t 15:00
#SBATCH -N 2
#SBATCH -n 8
# site specific
module load singularity openmpi/3.1.0
# dataset staging, if necessary
# ...
mpirun singularity run --nv -B /local/imagenet:/data/imagenet tensorflow-19.11-tf1-py3.sif python /workspace/nvidia-examples/resnet50v1.5/main.py --mode=training_benchmark --use_tf_amp --warmup_steps=200 --batch_size=256 --data_dir=/data/imagenet --results_dir=/tmp/resnet
立即快速部署人工智能工作负载
NGC提供的容器图像经过验证、优化,并定期更新为所有流行的深度学习框架的最新版本。随着奇点支持的增加,NGC容器现在可以更广泛地部署,包括HPC中心,个人GPU支持的工作站,以及喜欢的云。
下载一个NGC容器并运行
标签:enc 分布式计算 示例 指定 演示 运行时 最新版本 重要 orm
原文地址:https://www.cnblogs.com/wujianming-110117/p/13168876.html