标签:find 修复 网络 round 分布 ISE 属性 约束 吸引
代码:https://github.com/genforce/interfacegan
Abstract
尽管最近生成对抗网络(GANs)在高保真图像合成方面取得了进展,但对于GANs如何能够将随机分布的潜在编码映射成逼真的图像仍缺乏足够的理解。以往的研究假设GANs学习的潜在空间遵循分布表示,但观察到矢量运算现象。在这项工作中,我们提出了一个新的框架,称为InterFaceGAN,通过解释GANs学习到的潜在语义来进行语义人脸编辑。在此框架中,我们详细研究了如何将不同的语义编码到GANs的潜在空间中用于人脸合成。我们发现,经过良好训练的生成模型的潜在代码实际上在线性变换后学习了一个解纠缠(disentangled)表征。我们研究了各种语义之间的解纠缠(disentanglement),并设法用子空间投影解耦一些纠缠(entangled)语义,从而实现更精确的面部属性控制。除了操纵性别、年龄、表情和眼镜的存在,我们甚至可以改变面部姿势,以及修复GAN模型意外产生的伪影。该方法与GAN inversion方法或一些涉及编码器的模型相结合,进一步实现了真实图像的处理。大量的研究结果表明,学会自发地合成人脸可以生成解纠缠且可控的人脸属性表征 1. Introduction生成对抗网络(GANs)[15]是近年来图像合成技术的一个重要进展。GANs背后的基本原理是通过对抗训练来学习从潜在分布到真实数据的映射。在学习了这种非线性映射之后,GAN能够从随机采样的潜在编码中生成逼真的图像。然而,语义是如何在潜在空间中产生和组织的,尚不清楚。以人脸合成为例,在对一个潜在编码进行采样生成一幅图像时,编码如何能够确定输出的人脸的各种语义属性(如性别、年龄),以及这些属性之间是如何相互纠缠的?现有的工作通常侧重于提高GANs[40,28,21,8,22]的合成质量,然而,很少有人研究GANs在潜在空间方面的实际学习情况。Radford等人[31]首先观察了潜在空间中的向量算术特性。最近的一项工作[4]进一步表明,GAN发生器中间层的一些单元专门用于合成特定的视觉概念,如客厅生成结果中的沙发和电视。尽管如此,对于GAN如何连接潜在空间和图像语义空间,以及如何使用潜在编码进行图像编辑,仍然缺乏足够的理解。
本文提出了一个框架InterFaceGAN, Interpreting Face GANs的简称,用于识别在经过良好训练的人脸合成模型的潜在空间中编码的语义,并利用这些语义对人脸进行语义编辑。该框架除了具有矢量运算的特性外,还提供了理论分析和实验结果去验证线性子空间与潜在空间中出现的不同真假语义的匹配。我们进一步研究了不同语义之间的解纠缠,并证明了我们可以通过线性子空间投影解纠缠 纠缠属性(例如老年人比年轻人更容易戴眼镜)。这些解纠缠语义使任何给定的GAN模型都可以精确地控制面部属性,而无需重新训练。
我们的贡献总结如下:

1.1. Related Work
Generative Adversarial Networks. 近年来,GAN[15]因其在生成逼真图像方面的巨大潜力而受到广泛关注[1,17,6,40,28,21,8,22]。它通常以采样的潜在编码作为输入和输出合成的图像。为了使GANs适用于真实图像处理,现有的方法提出将映射从潜在空间反向到图像空间[30,42,27,5,16]或学习与GAN训练相关的额外编码器encoder[13,12,41]。尽管取得了巨大的成功,但在理解GANs如何在真实的视觉世界中将输入的潜在空间与语义联系起来方面,人们做的工作还很少。
Study on Latent Space of GANs. GANs的潜在空间一般被视为黎曼流形(Riemannian manifold)[9,2,23]。之前的工作侧重于探索如何通过在潜在空间内插值,使输出图像在不同的合成中平滑变化,而不管图像在语义上是否可控[24,32]。GLO[7]同时对生成器和潜在编码进行了优化,以学习更好的潜在空间。然而,关于训练有素的GAN如何能够在潜在空间中编码不同语义的研究仍然缺失。一些工作已经观察到向量算术性质[31,36]。除此之外,本文从单一语义的性质和多重语义的解纠缠两方面,对潜在空间中编码的语义进行了详细的分析。一些并发工作还探究了GANs学习的潜在语义。Jahanian等人[20]研究了GANs关于摄像机运动和图像色调的可操纵性。Goetschalckx等人的[14]提高了输出图像的可记忆性。Yang等人[38]探讨了用于场景合成的深层生成表示中的层次语义。与它们不同的是,我们专注于GANs中出现的用于人脸合成的人脸属性,并将我们的方法扩展到真实的图像处理。
Semantic Face Editing with GANs. 语义人脸编辑旨在处理给定图像的面部属性。与可以任意生成图像的无条件GANs相比,语义编辑希望模型只改变目标属性而保留输入人脸的其他信息。为了实现这一目标,目前的方法需要精心设计损失函数[29,10,35],引入额外的属性标签或特征[25,39,3,37,34],或特殊的架构[11,33]来训练新的模型。然而,这些模型的合成分辨率和质量都远远落后于原生GANs,如PGGAN[21]和StyleGAN[22]。与以往基于学习的方法不同,本研究探索了固定GAN模型潜在空间内的可解释语义,通过改变潜在编码将无约束的GAN转化为可控制的GAN
2. Framework of InterFaceGAN
在本节中,我们将介绍InterFaceGAN的框架,该框架首先对在经过良好训练的GAN模型的潜在空间中出现的语义属性进行严格分析,然后构建一个操作管道来利用隐藏编码中的语义进行面部属性编辑。
2.1. Semantics in the Latent Space
给定一个良好训练的GAN模型[28, 21, 8, 22],生成器可以被定义为一个决策函数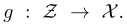 其中
其中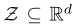 表示一个d维的潜在空间,一般使用高斯分布
表示一个d维的潜在空间,一般使用高斯分布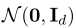 。
。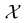 表示图像空间,其中的每个样本x拥有某语义信息,如用于人脸模型的性别和年龄。假设我们有一个语义打分函数
表示图像空间,其中的每个样本x拥有某语义信息,如用于人脸模型的性别和年龄。假设我们有一个语义打分函数![]() 表示带有m维语义分数(每一维对应一个语义属性)的语义空间。我们可以使用
表示带有m维语义分数(每一维对应一个语义属性)的语义空间。我们可以使用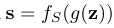 来连接潜在空间
来连接潜在空间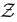 和语义空间
和语义空间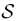 ,其中s和z分别表示语义分数和采样的潜在编码
,其中s和z分别表示语义分数和采样的潜在编码
Single Semantic. 当线性插值两个潜在编码z1和z2时,一般能能够观察到对应合成结果外观的连续变化[31, 8, 22]。该结果暗示了图像中包含的语义也能逐渐变化。根据 Property 1,z1和z2的线性插值形成了一个在中的方向,其进一步定义了一个超平面(hyperplane)。因此,我们做出一个假设,对任意二元语义(如男性 vs 女性),在潜在空间中存在一个超平面作为分离边界。当潜在编码在超平面的同一边运动时,语义保持一致(即原来男性,现在仍男性);如果跨过了边界,则会转换到相反的方向(即从男性变成女性)。
给定一个带有单位法向量(表面上某一点的法向量(Normal Vector)指的是在该点处与表面垂直的方向)的超平面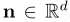 ,我们定义从样本z到该超平面的“distance”为:
,我们定义从样本z到该超平面的“distance”为:

其中,d(.,.)不是一个严格定义的距离,因为其值能为负。当z临近边界,并朝着边界移动并越过边界,“距离”和语义分数都会相应变化。只有在“distance”改变其数值符号时(即如由正数变负数),语义属性会反转(如男性变女性)。因此我们希望语义分数和“距离”之间的关系可以线性表示为:
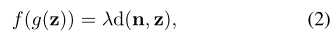
其中f(.,.)是用于特定语义的评分函数,其中λ>0是一个用来测量语义随着距离的变化而相应变化的速度的标量。
根据Property 2,由绘制的随机样本非常可能坐落在给定超平面的足够近的地方。因此,相应的语义可以通过由n定义的线性子空间建模

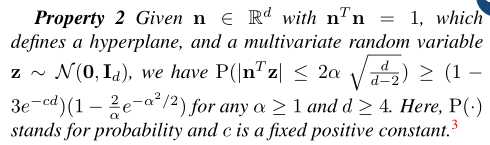
Multiple Semantics.当例子有m个不同的语义时,有:
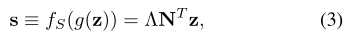
其中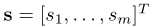 表示语义分数,
表示语义分数,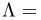
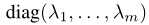 是一个包含线性系数的对角矩阵,其中
是一个包含线性系数的对角矩阵,其中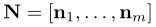 表示分离边界。意识到随机样本z的分布是,我们能够简单地计算语义分数s的均值和协方差为:
表示分离边界。意识到随机样本z的分布是,我们能够简单地计算语义分数s的均值和协方差为:
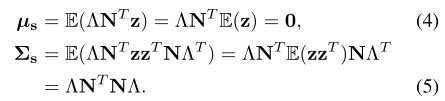
因此有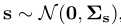 ,其是一个多元正态分布。s中的不同实体当且仅当
,其是一个多元正态分布。s中的不同实体当且仅当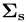 是一个对角矩阵时才是解纠缠的,其需要
是一个对角矩阵时才是解纠缠的,其需要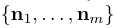 相互之间是正交的。如果条件不满足,一个语义将互相关联,且
相互之间是正交的。如果条件不满足,一个语义将互相关联,且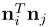 能够使用去测量第i个和第j个语义的纠缠程度(如性别和年龄之间的相关程度)
能够使用去测量第i个和第j个语义的纠缠程度(如性别和年龄之间的相关程度)
2.2. Manipulation in the Latent Space
在这个部分,将介绍如何使用在潜在空间中找到的语义来图像编辑
Single Attribute Manipulation. 根据等式(2),为了操纵合成图像的属性,我们能够使用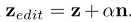 简单地编辑原始的潜在编码z。
简单地编辑原始的潜在编码z。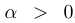 时,它将会使得合成结果在该语义上更正值化(如老人更老),同时分数在编辑后变为
时,它将会使得合成结果在该语义上更正值化(如老人更老),同时分数在编辑后变为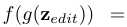
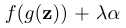 。同样地,
。同样地, 将使合成结果更负值化(老人变年轻)
将使合成结果更负值化(老人变年轻)
Conditional Manipulation. 当这里有超过一个的属性时,编辑其中的一个属性可能会影响其他的属性,因为一些属性可能互相耦合在一起。为了获得更加精准的控制,我们提出了通过手动强制等式(5)中的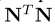 为对角矩阵的conditional manipulation方法。尤其是,我们使用投影去正交化不同的向量。如图2所示:
为对角矩阵的conditional manipulation方法。尤其是,我们使用投影去正交化不同的向量。如图2所示:
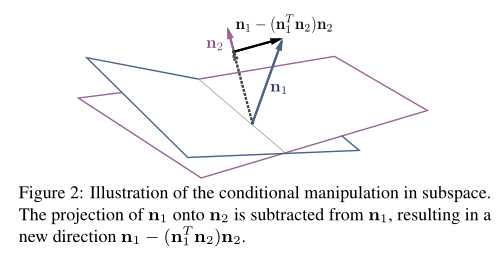
给定两个带有法向量n1和n2的超平面,我们找到投影方向 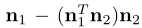 ,这样沿着这个新方向去移动样本就只会改变“属性1”, 而不会改变“属性2”了。(因为属性1减去了属性2在属性1的方向上的投影)我们称该操作为conditional manipulation。如果有一个以上的属性需要被限定,我们只需减去从原始方向到由所有限定方向构成的平面上的投影
,这样沿着这个新方向去移动样本就只会改变“属性1”, 而不会改变“属性2”了。(因为属性1减去了属性2在属性1的方向上的投影)我们称该操作为conditional manipulation。如果有一个以上的属性需要被限定,我们只需减去从原始方向到由所有限定方向构成的平面上的投影
Real Image Manipulation. 当我们的方法能够实现从固定GAN模型的潜在空间进行的语义编辑时,我们首先需要在实现操作前将真实图片映射成一个潜在编码。为了该目的,现有的方法提出直接优化潜在编码去减少重构损失的方法[27],或者学习一个额外的encoder将目标图像转换回潜在空间[42,5]。这里有很多模型已经将encoder包含在了GANs的训练过程中[13,12,41],可以直接使用他们来推论
3. Experiments
在本节中,我们使用最先进的GAN模型(PGGAN[21]和StyleGAN[22])来评估InterFaceGAN。具体来说,在PGGAN上进行了3.1、3.2、3.3节的实验来解释传统生成器的潜在空间。在第3.4章的实验中,我们研究了基于style的生成器,并比较了两组潜在表征在styleGAN中的不同之处。在第3.5节中,我们还将我们的方法应用于真实图像,以了解如何将GANs隐式学到的语义应用于真实的人脸编辑。实现细节可以在附录中找到
3.1. Latent Space Separation
如第2.1节所述,我们的框架是基于这样一个假设:对于任何二元属性,在潜在空间中都存在一个超平面,使得来自同一侧的所有样本都具有相同的属性。因此,我们想首先评估这一假设的正确性,以使剩余的分析变得可信。
我们对姿势、微笑、年龄、性别、眼镜等属性训练5个独立的线性支持向量机进行训练,然后在验证集(在属性得分上有着高置信度的6K个样本)和整个集合(480K个随机样本)上对它们进行评估。结果如表1所示:
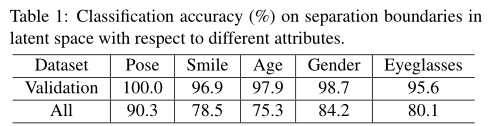
我们发现所有的线性边界在验证集上的准确率都在95%以上,在整个数据集上的准确率都在75%以上,这说明对于一个二元属性,潜在空间中存在一个线性超平面,可以很好地将数据分成两组。
我们还将图3中的一些样本按照到决策边界的距离进行排序,从而实现可视化:

注意,那些极端情况(图3中的第一行和最后一行)不太可能直接采样,而是通过将潜在代码移向法线的“无限”方向来构造。从图3可以看出,正样本和负样本在对应的属性上是可以区分的。
3.2. Latent Space Manipulation
在这一部分中,我们验证了InterFaceGAN发现的语义是否可操作。
Manipulating Single Attribute. 图4绘制了5个不同属性上的操作结果:

这表明,我们的操作方法在所有属性上都表现良好,无论是正方向还是负方向。特别是姿势属性,我们观察到即使通过解决双分类问题来搜索边界,移动潜在编码也会产生连续的变化。此外,尽管在训练集中缺乏足够的极端姿势的数据,GAN也能够想象侧面脸应该是什么样子。同样的情况也发生在眼镜属性上。虽然训练集的数据不充分,但是我们可以手动创建很多戴着眼镜的人脸。这两个观察结果有力地证明了GAN并不是随机生成图像的,而是从潜在空间中学习了一些可解释的语义。
Distance Effect of Semantic Subspace. 在对潜在编码进行操作时,我们观察到一个有趣的距离效应,即如果离边界太远,样本的外观会发生剧烈的变化,最终会变成如图3所示的极端情况。图5以性别编辑为例说明了这一现象:

可见靠近边界的操作效果很好。然而,当样本超过一定的区域(选择5为阈值)时,编辑结果就不再像原来的面孔了。但这种效应并不影响我们对潜空间中解纠缠语义的理解。这是因为这种极端样本不太可能直接从标准正态分布中提取,这一点在2.1节的Property 2中指出。相反,它们是通过沿着一定的方向不断移动正常采样的潜在编码来手工构造的。这样可以更好地解释GANs的潜在语义。
Artifacts Correction. 我们进一步应用我们的方法来修复有时在合成输出中出现的伪影。我们手动标记4K个糟糕的合成结果,然后和其他属性一样训练一个线性SVM来寻找分离超平面。我们惊奇地发现,GANs也在潜在空间中编码这些信息。基于这个发现,我们可以修正GAN在生成过程中所犯的一些错误,如图6所示:

3.3. Conditional Manipulation
在本节中,我们将研究不同属性之间的分离,并评估条件操作(conditional manipulation)方法。
Correlation between Attributes. 与[22]引入感知路径长度和线性可分性来度量潜在空间的解纠缠性不同,我们更多地关注不同隐语义之间的关系,研究它们之间是如何耦合的。这里,使用两个不同的度量标准来度量两个属性之间的相关性。(I)计算两个方向的cosine相似度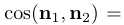
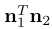 ,其中n1和n2表示单位向量。(ii)将每个属性分数看作一个随机变量,并使用从500K个合成数据中观察得到的属性分布去计算相关系数ρ。
,其中n1和n2表示单位向量。(ii)将每个属性分数看作一个随机变量,并使用从500K个合成数据中观察得到的属性分布去计算相关系数ρ。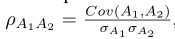 ,其中A1和A2表示关于两个属性的两个随机变量。Conv(.,.)表示协方差,σ表示标准差。
,其中A1和A2表示关于两个属性的两个随机变量。Conv(.,.)表示协方差,σ表示标准差。
表2和表3报告了结果:
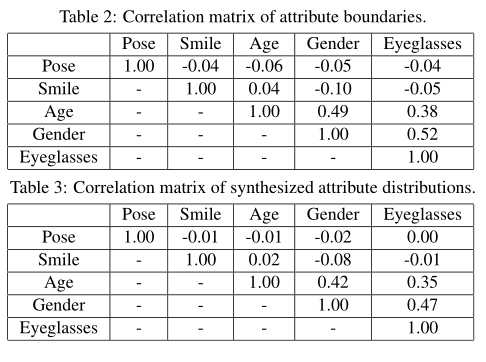
我们可以看出属性在这两个度量下的表现相似,这表明我们的InterFaceGAN能够准确地识别隐藏在潜在空间中的语义。我们还发现Smile和Pose几乎与其他属性正交。然而,性别、年龄和眼镜是高度相关的。这个观察结果反映了训练数据集中的属性相关性。在某种程度上,这里的男性老年人更有可能戴眼镜。GAN在学习产生真实观察结果时也捕捉到了这一特点。
Conditional Manipulation. 为了在独立的面部属性编辑中 去关联 不同的语义,我们在第2.2节中提出了条件操作方法。图7显示了将一个属性作为条件操作另一个属性的一些结果:

以图7中左侧样本为例,在编辑变老(第一行)时,结果趋于男性化。我们通过从年龄方向减去性别方向(第二行)的投影来解决这个问题,从而得到一个新的方向。这样,我们可以确保当样本沿着投影方向(第三行)移动时,性别成分几乎没有受到影响。图8显示了多个约束条件下的条件操作,其中我们通过有条件地保留年龄和性别来添加眼镜:
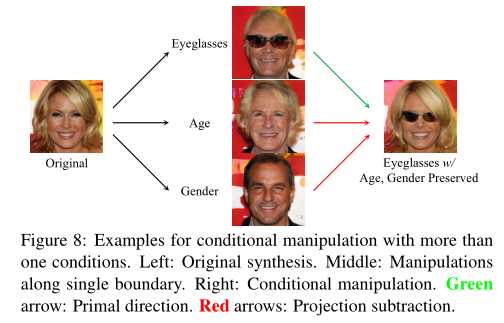
在一开始,增加眼镜与改变年龄和性别是纠缠在一起的。但通过投影操作,我们在不影响年龄和性别的情况下,成功地增加了眼镜。这两个实验表明,我们提出的条件控制方法有助于实现独立和精确的属性控制。
3.4. Results on StyleGAN
与传统的GANs不同,StyleGAN[22]提出了基于风格的生成器。基本上,StyleGAN把潜在编码输入到生成器之前,将其从空间Z映射到另一个高维空间W。正如[22]中指出的,W比Z表现出更强的解纠缠性,因为W不受任何特定分布的限制,可以更好地模拟真实数据的底层特征。
我们对StyleGAN的Z和W空间进行了类似的分析,就像对PGGAN所做的那样,我们发现W空间确实学习了一种更不纠缠的表示,正如[22]所指出的那样。这种分离使得W空间在属性编辑方面比Z空间有更强的优势。如图9所示:

在StyleGAN模型中,年龄和眼镜也是纠缠的。与Z空间(第二行)相比,W空间(第一行)性能更好,特别是在long-distance操作中。不过,我们可以使用第2.2节中描述的条件操作技巧 去关联 Z空间(第三行)中的这两个属性,从而得到更吸引人的结果。然而,这个技巧不能应用于W空间。我们发现W空间有时捕获了训练数据中发生的属性相关性,并将它们编码为耦合的“style”。以图9为例,“age”和“eyeglasses”被支持为两个独立的语义,但StyleGAN实际上学习了包含眼镜的年龄方向,使得这个新的方向与眼镜方向本身正交。这样,减去几乎为零的投影,几乎不会影响最终结果。
3.5. Real Image Manipulation
在这一部分中,我们利用提出的InterFaceGAN对真实人脸进行操作,以验证GAN学到的语义属性是否可以应用于真实人脸。回想一下,InterFaceGAN通过沿着某个方向移动潜在代码来实现语义人脸编辑。因此,我们首先需要将给定的真实图像转换回潜在编码。这是一个重要的任务,因为GANs不能完全捕捉所有的模式以及真实分布的多样性。对于一个预先训练好的GAN模型,有两种典型的方法。一种是基于优化的方法,使用固定生成器直接优化潜在代码,以最小化pixel-wise的重建误差[27]。另一种是基于编码器的,其中额外的编码器网络被训练来学习逆映射[42]。我们在PGGAN和StyleGAN上测试了两种基线方法。
结果如图10所示:

我们可以看出,在反转PGGAN时,基于优化(第一行)和基于编码器(第二行)的方法的性能都很差。这可以归因于训练数据和测试数据分布之间的强烈差异。例如,即使输入是东方人,模型也倾向于生成西方人(如图10所示)。然而,与输入不同的是,反向图像仍然可以通过InterFaceGAN进行语义编辑。与PGGAN相比,StyleGAN(第三行)的结果要好得多。在这里,我们处理layer-wise styles(即每一层的w)作为优化目标。在编辑实例时,我们将所有样式编码推向相同的方向。如图10所示,我们成功地改变了真实人脸图像的属性,无需再训练StyleGAN,而是利用了潜在空间的解释语义。
我们也测试了InterFaceGAN的编码器-解码器生成模型,它训练一个带着生成器和鉴别器的编码器。当模型收敛后,可以直接使用编码器进行推理,将给定图像映射到潜在空间。我们用我们的方法来解释最近的 encoder-decoder模型LIA[41]的潜在空间。操作结果如图11所示:

其中我们成功编辑了输入的带有不同属性的人脸,比如年龄和人脸姿势。这说明基于encoder-decoder的生成模型中的潜在编码也支持语义操作。另外,与图10 (b)中在GAN模型准备好后再单独学习encoder相比,与生成器一起训练的编码器得到了更好的重构和操作结果。
4. Conclusion
我们提出InterFaceGAN来解释在GANs的潜在空间中编码的语义。通过利用解释语义和提出的条件操作技术,我们可以用任何固定的GAN模型精确地控制面部属性,甚至将无条件的GAN转换为可控制的GAN。大量的实验表明,InterFaceGAN也可以应用于真实的图像编辑。
变老 - 4 - Interpreting the Latent Space of GANs for Semantic Face Editing- 1 - 论文学习(人脸编辑)
标签:find 修复 网络 round 分布 ISE 属性 约束 吸引
原文地址:https://www.cnblogs.com/wanghui-garcia/p/13163007.html