标签:网页 search 操作符 pdf 描述符 %x 提交 测试 prope
内容参考网上的教程,仅方便自己查看
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。
为用户提供按关键字查询的全文搜索功能。
实现企业海量数据的处理分析的解决方案。大数据领域的重要一份子,如著名的ELK框架(ElasticSearch,Logstash,Kibana)。
| 比较项\框架名称 | redis | mysql | elasticsearch | hbase | hadoop/hive |
|---|---|---|---|---|---|
| 容量 | 低 | 中 | 较大 | 海量 | 海量 |
| 查询时效性 | 极高 | 中等 | 较高 | 中等 | 低 |
| 查询灵活性 | 较差 k-v模式 | 非常好,支持sql | 较好,关联查询较弱,但是可以全文检索,DSL语言可以处理过滤、匹配、排序、聚合等各种操作 | 较差,主要靠rowkey, scan的话性能不行,或者建立二级索引 | 非常好,支持sql |
| 写入速度 | 极快 | 中等 | 较快 | 较快 | 慢 |
| 一致性、事务 | 弱 | 强 | 弱 | 弱 | 弱 |
CLuster/Node
Shard
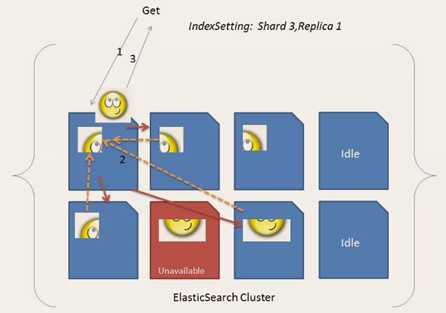
数据分为较小的分片。每个分片放到不同的服务器上。 当你查询的索引分布在多个分片上时,ES会把查询发送给每个相关的分片,并将结果组合在一起,而应用程序并不知道分片的存在。
Replication
为提高查询吞吐量或实现高可用性,可以使用分片副本。 副本是一个分片的精确复制,每个分片可以有零个或多个副本。ES中可以有许多相同的分片,其中之一被选择更改索引操作,这种特殊的分片称为主分片。
当主分片丢失时,如:该分片所在的数据不可用时,集群将副本提升为新的主分片。
es 把数据分成多个shard,下图中的P0-P2,多个shard可以组成一份完整的数据,这些shard可以分布在集群中的各个机器节点中。随着数据的不断增加,集群可以增加多个分片,把多个分片放到多个机子上,已达到负载均衡,横向扩展。
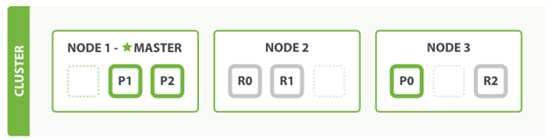
在实际运算过程中,每个查询任务提交到某一个节点,该节点必须负责将数据进行整理汇聚,再返回给客户端,也就是一个简单的节点上进行Map计算,在一个固定的节点上进行Reduces得到最终结果向客户端返回。
这种集群分片的机制造就了elasticsearch强大的数据容量及运算扩展性。
? ES 所有数据都是默认进行索引的,这点和mysql正好相反,mysql是默认不加索引,要加索引必须特别说明,ES只有不加索引才需要说明。
? 而ES使用的是倒排索引和Mysql的B+Tree索引不同。
传统关系型数据库
select * from tb like ‘%xx%‘传统的关系性数据库对于关键词的查询,只能逐字逐行的匹配,性能非常差。
倒排索引
全文搜索引擎目前主流的索引技术就是倒排索引的方式。
? 全文检索是指计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。
全文检索主流工具:
? Elasticsearch 数据管理的顶层单位就叫做 Index(索引),相当于关系型数据库里的数据库的概念。另外,每个Index的名字必须是小写。
Index里面单条的记录称为 Document(文档)。许多条 Document 构成了一个 Index。Document 使用 JSON 格式表示。同一个 Index 里面的 Document,不要求有相同的结构(scheme),但是最好保持相同,这样有利于提高搜索效率。
? Es6之后,一个index中只能有一个type
在一个索引中,你可以定义一种或多种类型。一个类型是你的索引的一个逻辑上的分类/分区,其语义完全由你来定。通常,会为具有一组共同字段的文档定义一个类型。比如说,我们假设你运营一个博客平台并且将你所有的数据存储到一个索引中。在这个索引中,你可以为用户数据定义一个类型,为博客数据定义另一个类型,当然,也可以为评论数据定义另一个类型。
? Document 可以分组,比如employee这个 Index 里面,可以按部门分组,也可以按职级分组。这种分组就叫做 Type,它是虚拟的逻辑分组,用来过滤 Document,类似关系型数据库中的数据表。
? 在 6.0 的时候,已经默认只能支持一个索引一个 type 了,7.0 版本新增了一个参数 include_type_name ,即让所有的 API 是 type 相关的,这个参数在 7.0 默认是 true,不过在 8.0 的时候,会默认改成 false,也就是不包含 type 信息了,这个是 type 用于移除的一个开关。
文档元数据为_index, _type, _id, 这三者可以唯一表示一个文档,_index表示文档在哪存放,_type表示文档的对象类别,_id为文档的唯一标识。
每个Document都类似一个JSON结构,它包含了许多字段,每个字段都有其对应的值,多个字段组成了一个 Document,可以类比关系型数据库数据表中的字段。
关系数据库 ? 数据库 ? 表 ? 行 ? 列(Columns)
Elasticsearch ? 索引(Index) ? 类型(type) ? 文档(Docments) ? 字段(Fields)
略
略
参考文档: https://www.cnblogs.com/xi-jie/articles/10531532.html
简单描述倒排索引
我们要查询的是出现关键词的文档。在倒排列表(PostingList)中存储了出现某个单词的文档列表以及在文档的位置信息
倒排列表记载了出现过某个单词的所有文档的文档列表及单词在该文档中出现的位置信息,每条记录称为一个倒排项(Posting)。根据倒排列表,即可获知哪些文档包含某个单词。
? 一般搜索引擎的处理对象是互联网网页,而文档这个概念要更宽泛些,代表以文本形式存在的存储对象,相比网页来说,涵盖更多种形式,比如Word,PDF,html,XML等不同格式的文件都可以称之为文档。再比如一封邮件,一条短信,一条微博也可以称之为文档。在本系列后续内容,很多情况下会使用文档来表征文本信息。
? 由若干文档构成的集合称之为文档集合。比如海量的互联网网页或者说大量的电子邮件都是文档集合的具体例子。
? 在搜索引擎内部,会将文档集合内每个文档赋予一个唯一的内部编号,以此编号来作为这个文档的唯一标识,这样方便内部处理,每个文档的内部编号即称之为“文档编号”,后文有时会用DocID来便捷地代表文档编号。
? 与文档编号类似,搜索引擎内部以唯一的编号来表征某个单词,单词编号可以作为某个单词的唯一表征。
? 倒排索引是实现“单词-文档矩阵”的一种具体存储形式,通过倒排索引,可以根据单词快速获取包含这个单词的文档列表。倒排索引主要由两个部分组成:“单词词典”和“倒排文件”。
? 搜索引擎的通常索引单位是单词,单词词典是由文档集合中出现过的所有单词构成的字符串集合,单词词典内每条索引项记载单词本身的一些信息以及指向“倒排列表”的指针。
? 倒排列表记载了出现过某个单词的所有文档的文档列表及单词在该文档中出现的位置信息,每条记录称为一个倒排项(Posting)。根据倒排列表,即可获知哪些文档包含某个单词。
? 所有单词的倒排列表往往顺序地存储在磁盘的某个文件里,这个文件即被称之为倒排文件,倒排文件是存储倒排索引的物理文件。
下载解压
$ wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.6.0.tar.gz
$ tar -zxf elasticsearch-6.6.0.tar.gz -C /opt/modules/
修改elasticsearch jvm配置
$ vi config/jvm.options
修改
-Xms512m
-Xmx512m
修改elasticsearch 配置
$ vi config/elasticsearch.yml
修改(0.0.0.0 任意主机访问)
network.host: 0.0.0.0
http.port: 9200
修改系统参数
$ sudo vi /etc/security/limits.conf
添加
* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 4096
soft nproc: 可打开的文件描述符的最大数(软限制)
hard nproc: 可打开的文件描述符的最大数(硬限制)
soft nofile:单个用户可用的最大进程数量(软限制)
hard nofile:单个用户可用的最大进程数量(硬限制)
修改
$ sudo vi /etc/sysctl.conf
添加
vm.max_map_count=262144
$ sudo sysctl -p
重启linux
reboot
启动es
加-d后台启动
./bin/elasticsearch
web浏览
http://linux01:9200
查看命令
http://linux01:9200/_cat
解压
tar -zxf kibana-6.6.0-linux-x86_64.tar.gz -C /opt/modules
配置
$ vi config/kibana.yml
修改
server.port: 5601
server.host: "linux01"
elasticsearch.hosts: ["http://linux01:9200"]
kibana.index: ".kibana"
启动
$ ./bin/kibana
通过web访问
启动elasticsearch,kibana
web浏览 http://linux01:5601/
可以添加测试数据
查看es中的索引
GET /_cat/indices?v
| 表头 | 含义 |
|---|---|
| health | green 集群完整 yellow 单点正常、集群不完整 red 单点不正常 |
| status | 是否能使用 |
| index | 索引名 |
| uuid | 索引统一编号 |
| pri | 主节点几个 |
| rep | 从节点几个 |
| docs.count | 文档数 |
| docs.deleted | 文档被删了多少 |
| store.size | 整体占空间大小 |
| pri.store.size | 主节点占 |
增加一个索引
PUT /movie_index
删除索引
DELETE /movie_index
新增文档
PUT /movie_index/movie/1
{
"id":1,
"name":"operation red sea",
"doubanScore":8.5,
"actorList":[
{"id":1,"name":"zhang yi"},
{"id":2,"name":"hai qing"},
{"id":3,"name":"zhang han yu"}
]
}
PUT /movie_index/movie/2
{
"id":2,
"name":"operation meigong river",
"doubanScore":8.0,
"actorList":[
{"id":3,"name":"zhang han yu"}
]
}
PUT /movie_index/movie/3
{
"id":3,
"name":"incident red sea",
"doubanScore":5.0,
"actorList":[
{"id":4,"name":"zhang chen"}
]
}
直接用id查找
GET /movie_index/movie/1
修改(整体替换)
PUT /movie_index/movie/3
{
"id":"3",
"name":"incident red sea",
"doubanScore":"5.0",
"actorList":[
{"id":"1","name":"zhang chen"}
]
}
修改某一个字段
POST movie_index/movie/3/_update
{
"doc": {
"doubanScore":"10.0"
}
}
删除document
DELETE movie_index/movie/3
搜索type全部数据
GET movie_index/movie/_search
返回信息解释
{
"took": 10, //耗费时间 毫秒
"timed_out" : false //是否超时
"_shards": {
"total": 5, //发送给全部5个分片
},
"hits": {
"total": 3, //命中3条数据
"max_score": 1, //最大评分
"hits": [...] // 结果
}
按条件查找
GET movie_index/movie/_search
{
"query":{
"match_all": {}
}
}
按分词查询
GET movie_index/movie/_search
{
"query":{
"match": {"name":"red"}
}
}
按分词子属性查询
GET movie_index/movie/_search
{
"query":{
"match": {"actorList.name":"zhang"}
}
}
match phrase
按短语查询,不再利用分词技术,直接用短语在原始数据中匹配
GET movie_index/movie/_search
{
"query":{
"match_phrase": {"name":"operation red"}
}
}
fuzzy查询
GET movie_index/movie/_search
{
"query":{
"fuzzy": {"name":"rad"}
}
}
过滤-查询后过滤
GET movie_index/movie/_search
{
"query":{
"match": {"name":"red"}
},
"post_filter":{
"term": {
"actorList.id": 1
}
}
}
过滤 查询前过滤(推荐)
GET movie_index/movie/_search
{
"query":{
"bool":{
"filter":[
{
"term": { "actorList.id": "1" }
},
{
"term": { "actorList.name": "zhang" }
}
],
"must": {
"match": { "name":"red"}
}
}
}
}
过滤--按范围过滤
GET movie_index/movie/_search
{
"query": {
"bool": {
"filter": {
"range": {
"doubanScore": {"gte": 8.5}
}
}
}
}
}
关于范围操作符:
| 代码 | 解释 |
|---|---|
| gt | 大于 |
| lt | 小于 |
| gte | 大于等于 great than or equals |
| lte | 小于等于 less than or equals |
排序
GET movie_index/movie/_search
{
"query":{
"match": {"name":"red sea"}
},
"sort": [
{
"doubanScore": { "order": "desc" }
}
]
}
分页查询
GET movie_index/movie/_search
{
"query": { "match_all": {} },
"from": 1,
"size": 1
}
指定查询字段
GET movie_index/movie/_search
{
"query": { "match_all": {} },
"_source": ["name", "doubanScore"]
}
高亮显示
GET movie_index/movie/_search
{
"query":{
"match": {"name":"red sea"}
},
"highlight": {
"fields": {"name":{} }
}
}
聚合
取出每个演员共参与了多少部电影
GET movie_index/movie/_search
{
"aggs": {
"groupby_actor": {
"terms": {
"field": "actorList.name.keyword"
}
}
}
}
每个演员参演电影的平均分是多少,并按评分排序
GET movie_index/movie/_search
{
"aggs": {
"groupby_actor_id": {
"terms": {
"field": "actorList.name.keyword" ,
"order": {
"avg_score": "desc"
}
},
"aggs": {
"avg_score":{
"avg": {
"field": "doubanScore"
}
}
}
}
}
}
字符串型:text、keyword
数值型:long、integer、short、byte、double、float、half_float、scaled_float
日期类型:date
布尔类型:boolean
二进制类型:binary
范围类型:integer_range、float_range、long_range、double_range、date_range
数组类型:array
对象类型:object
嵌套类型:nested object
geo_point(点)、geo_shape(形状)
记录IP地址ip
实现自动补全completion
记录分词数:token_count
记录字符串hash值母乳murmur3
允许对同一个字段采用不同的配置,比如分词,例如对人名实现拼音搜索,只需要在人名中新增一个子字段为pinyin
elasticsearch本身自带的中文分词,就是单纯把中文一个字一个字的分开,根本没有词汇的概念。但是实际应用中,用户都是以词汇为条件,进行查询匹配的,如果能够把文章以词汇为单位切分开,那么与用户的查询条件能够更贴切的匹配上,查询速度也更加快速。
分词器下载网址:https://github.com/medcl/elasticsearch-analysis-ik
$ mkdir plugins/ik
解压ik分词插件 到ik目录
$ unzip xx/xx/elasticsearch-analysis-ik-6.6.0.zip -d plugins/ik/
重启es
$ bin/elasticsearch -d
使用默认分词器 (每个汉字是一个词)
GET movie_index/_analyze
{
"text": "我是中国人"
}
使用ik分词器( “中国人”是一个词语)
GET movie_index/_analyze
{
"analyzer": "ik_smart",
"text": "我是中国人"
}
使用ik max word分词器 (中国、国人、中国人都是词语)
GET movie_index/_analyze
{
"analyzer": "ik_max_word",
"text": "我是中国人"
}
略
GET movie_index/_mapping/movie
实际上每个type中的字段是什么数据类型,由mapping定义。
如果没有设定mapping系统会自动,根据一条数据的格式推断出对应类型。
true/false boolean
120 long
2.5 double
"2018-12-01" date
"hello ab" text+keyword
可以自定义mapping,一旦有数据就无法在做修改了;虽然每个Field的数据放在不同的type下,但是同一个名字的field在一个index下只能有一种定义。
创建movie_chn索引,并定义mapping,指定text分词器
PUT movie_chn
{
"mappings": {
"movie":{
"properties": {
"id":{
"type": "long"
},
"name":{
"type": "text"
, "analyzer": "ik_smart"
},
"doubanScore":{
"type": "double"
},
"actorList":{
"properties": {
"id":{
"type":"long"
},
"name":{
"type":"keyword"
}
}
}
}
}
}
}
添加数据
PUT /movie_chn/movie/1
{ "id":1,
"name":"红海行动",
"doubanScore":8.5,
"actorList":[
{"id":1,"name":"张译"},
{"id":2,"name":"海清"},
{"id":3,"name":"张涵予"}
]
}
PUT /movie_chn/movie/2
{
"id":2,
"name":"湄公河行动",
"doubanScore":8.0,
"actorList":[
{"id":3,"name":"张涵予"}
]
}
PUT /movie_chn/movie/3
{
"id":3,
"name":"红海事件",
"doubanScore":5.0,
"actorList":[
{"id":4,"name":"张晨"}
]
}
测试
GET /movie_chn/movie/_search
{
"query": {
"match": {
"name": "红海战役"
}
}
}
GET /movie_chn/movie/_search
{
"query": {
"term": {
"actorList.name": "张译"
}
}
}
标签:网页 search 操作符 pdf 描述符 %x 提交 测试 prope
原文地址:https://www.cnblogs.com/xiefeichn/p/13192906.html