标签:有序表 search 大型数据库 存储 区间 有一个 学习 image 程序
思维导图
算法小结
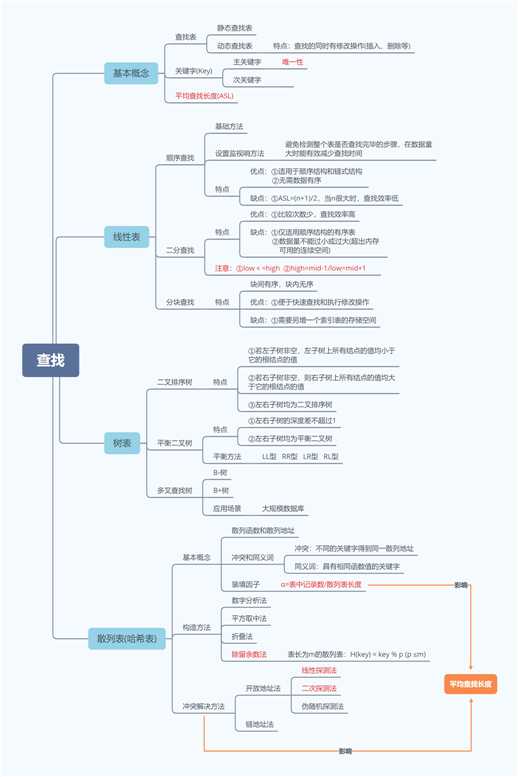
1.顺序查找
①基础方法

1 int Search(SSTable ST, KeyType key) 2 { 3 for(i=1;i<=ST.length;i++) 4 { 5 if(key==ST.R[i].key) return i; 6 } 7 return 0;//若未查找到则返回0 8 }
②设置监视哨方法
1 //避免查找过程中每次检测整个表是否查找完毕的步骤 2 //在数据量大能有效减少查找时间 3 int Search(SSTable ST, KeyType key) 4 { 5 ST.R[0].key = key; //把待查关键字key存入表头,起监视哨作用 6 for(i=ST.length; ST.R[i].key!=key; --i ); 7 return i; //若查找到则返回其下标,若未查找到则返回0 8 }
2.二分查找
①递归方法
1 int Search(SSTable ST, KeyType key, int low, int high) 2 { 3 if(low <= high){ 4 mid = (low+high) / 2; 5 if(key == ST.R[mid].key) 6 return mid; 7 else if(key < ST.R[mid].key) 8 return Search(ST,key,low,mid-1);//递归查找左区间 9 else 10 return Search(ST,key,mid+1,high);//递归查找右区间 11 } 12 return 0;//若未查找到则返回0 13 }
②非递归方法
1 int Search(SSTable ST, KeyType key) 2 { 3 int low = 1, high = ST.length;//置查找区间初值 4 while(low <= high) 5 { 6 mid = (low+high) / 2; 7 if(key == ST.R[mid].key) 8 return mid;//找到待查元素 9 else if(key < ST.R[mid].key) 10 high = mid-1; //继续在前一子表进行查找 11 else 12 low = mid + 1; //继续在后一子表进行查找 13 } 14 return 0; //表中不存在待查元素则返回0 15 }
③分析:设存在有序表a,key为所要查找的元素值,根据mid=(low+high)/2,可得出查找区间为[low, mid-1]或者[mid+1,high]。ⅰ 若存在key,找到a[mid]=key退出即可。ⅱ 若不存在key在查找过程中,low和high将逐渐靠拢、缩小区间,直至low=high=mid,由于循环条件为low<=high(若为low=high,此处将直接结束程序,无法判断当前元素是否等于key),因此程序将继续进行,low>high,最终退出循环。
3.二叉排序树
①查找算法(利用递归实现)
1 Tree Search(Tree T, KeyType key) 2 { 3 if((T==NULL) || key==T->data.key)//若树空或查找到,返回当前结点 4 return T; 5 else if(key < T->data.key) //在左子树中继续查找 6 return SearchBST(T->lchild, key); 7 else //在右子树中继续查找 8 return SearchBST(T->rchild, key); 9 }
②插入算法
若要在树中插入一个关键字值为key的结点*S,根据查找的思路,在树中自根结点往下查找,如果树中不存在值为key的结点则查找失败,在当前位置插入结点,如果存在则查找成功,退出程序。
1 void Insert(Tree &T, ElemType key ) 2 { 3 if (T == NULL) 4 {//树为空则作为根结点 5 s = new Node; 6 s->data = key; 7 s->lchild = s->rchild = NULL; 8 T = s; 9 } 10 11 if (key == T.data) return; //查找成功则退出 12 else if (key < T.data) //小于当前结点值,递归左子树 13 Insert(T -> lchild, key); 14 else if (key > T.data) //大于当前结点值,递归右子树 15 Insert(T -> rchild, key); 16 }
③创建算法(相当于插入n个结点)
4.散列表
设散列表表长为m。
①创造方法:
常用的创造方法为除留余数法,一般被除数可选择小于表长的最大质数。
②冲突处理:
ⅰ 线性探测法:Hi=(H(key)+i)%m 0≤i≤m-1
从H0开始,若H0已被占用,则检索下一个位置H1是否被占用,以此类推,直至找到空位或散列表已满。但该方法易造成”二次聚集”现象,导致非同义词之间可能彼此冲突。
ⅱ 平方探查法:Hi=(H(key)+i*i)%m 0≤i≤m,(此处列举的是正向平方探查法)
此方法能减少堆积的发生,但可能无法探查整个散列表,即不能保证找到不发生冲突的地址。
ⅲ 链地址法:将同义词放在同一个单链表中,再用数组存储每个单链表的头指针。
相较于开放地址法,该方法避免开放地址法的各种缺陷,并且适用于表长不确定的情况,但同时查找效率可能相对有所影响,查找某一数值可能需遍历完单链表。
其他知识点小结
1.召回率和准确率
召回率 = 系统检索到的相关文件 / 系统所有相关的文件总数
准确率 = 系统检索到的相关文件 / 系统所有检索到的文件总数
假设有一个大型数据库,需要根据关键字从中查找相关文件。假设该数据库共有1000个文档,现给出关键字,与之相关的文件共有100个,系统检索出75个文档,其中50个与关键字相关。
根据上述公式,召回率 = 50 / 100 = 50% 准确率 = 50 / 75 = 67%
心得体会
在本章学习了各种查找算法,二分查找算法由于慕课上的讨论,对这类算法相对更加了解,但是对于树表查找比较生疏,对B+树、B-树这些知识点感到比较陌生,接下来会着重复习一下这方面的内容。
标签:有序表 search 大型数据库 存储 区间 有一个 学习 image 程序
原文地址:https://www.cnblogs.com/Function-F/p/13198117.html
