标签:运行 数据库 logs redis awl auth crawl app mys
先来个工具操作
1、获取链接https://www.huya.com/g/xingxiu
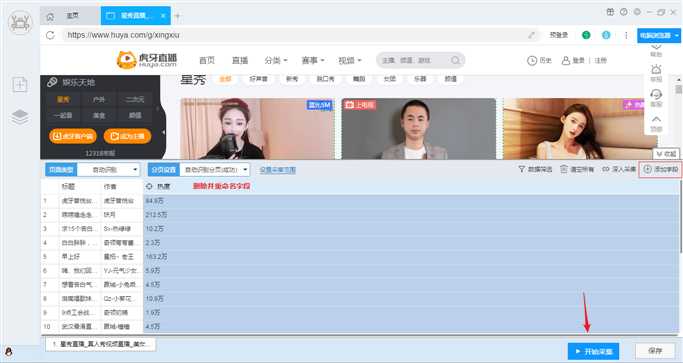
2、删除字段、增加字段、开始采集
3、启动
4、运行中
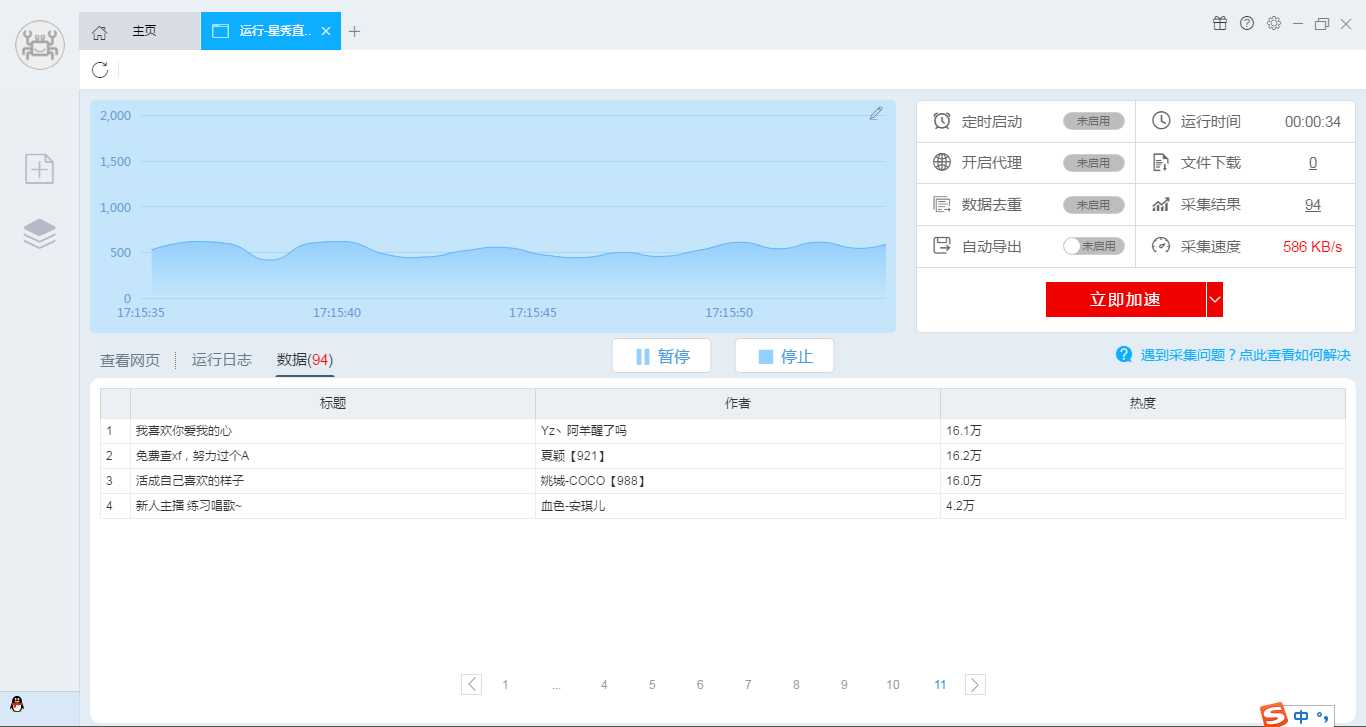
5、采的太多了我就停止了
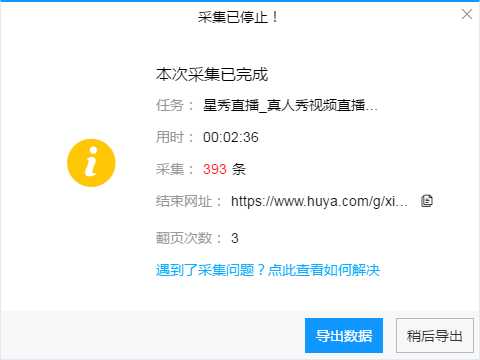
6、导出数据Excel格式
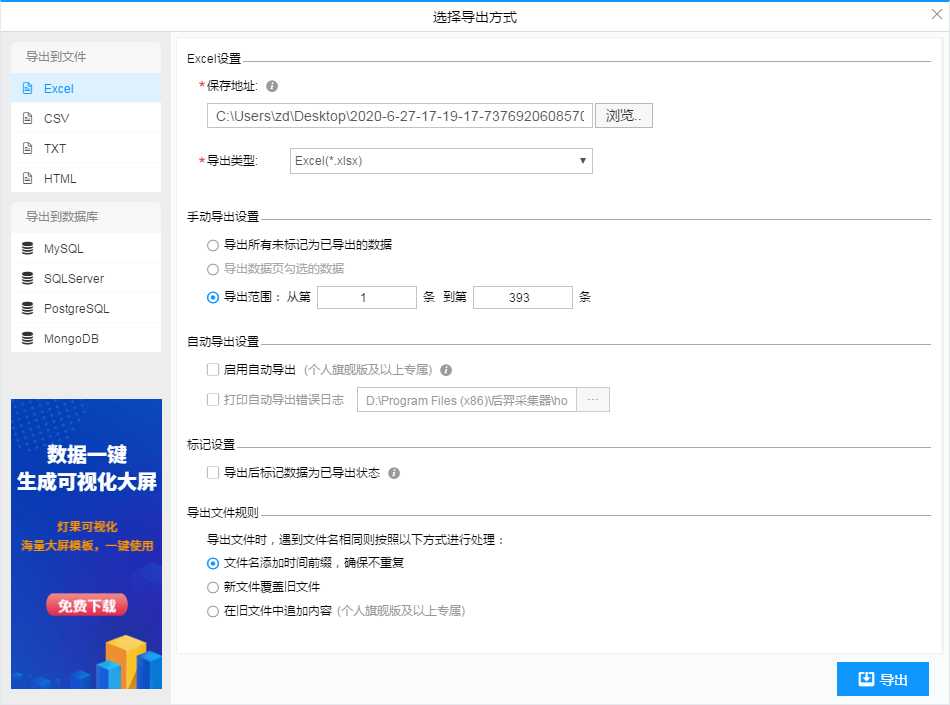
7、查看本地文件

8、导入到mysql数据库
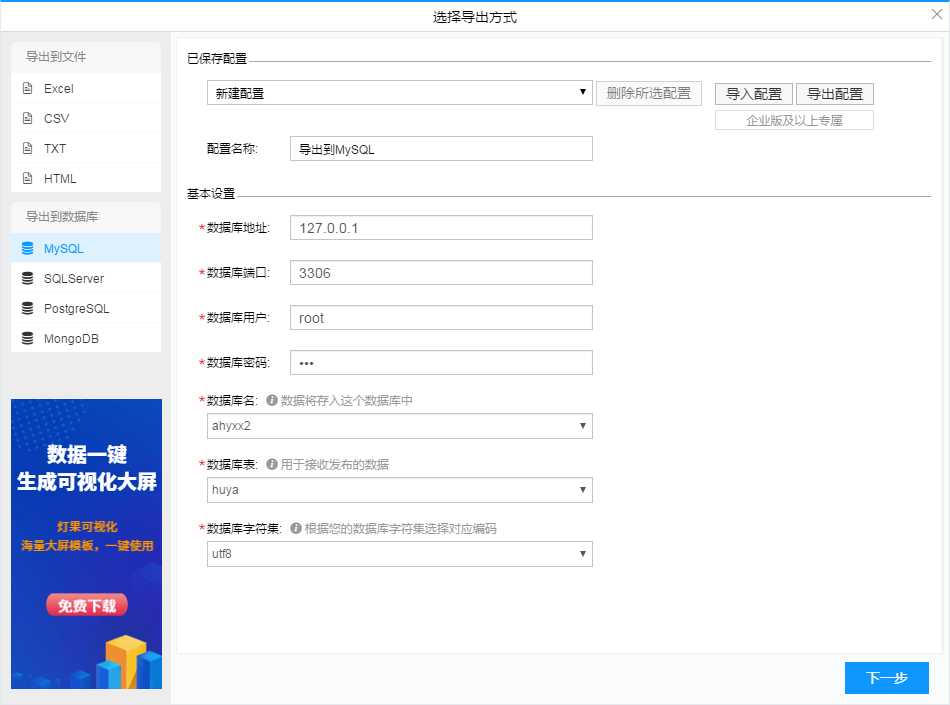
9、mysql配置
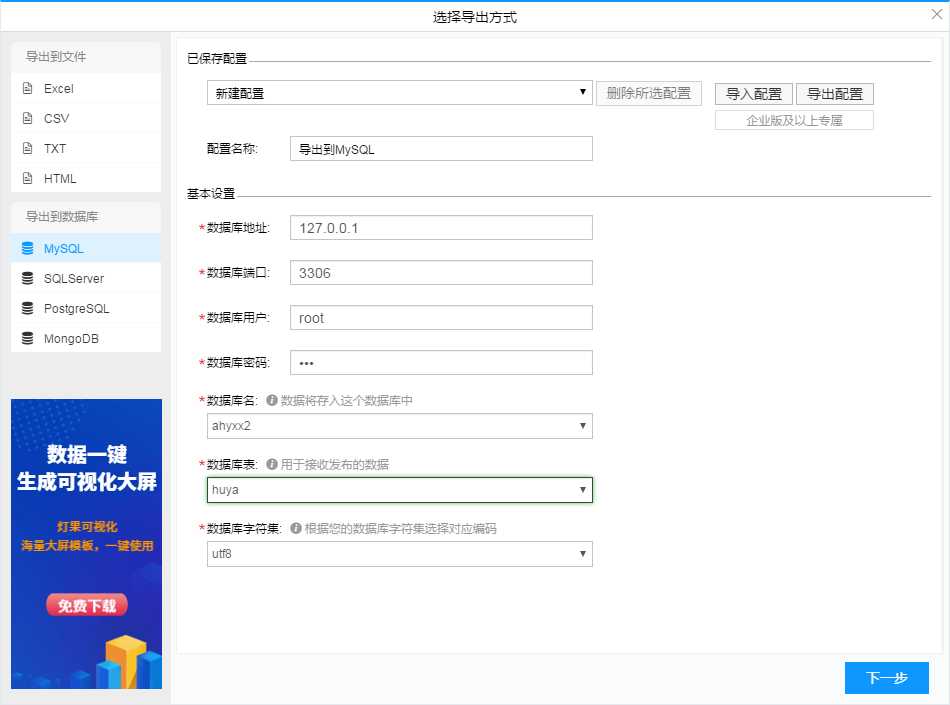
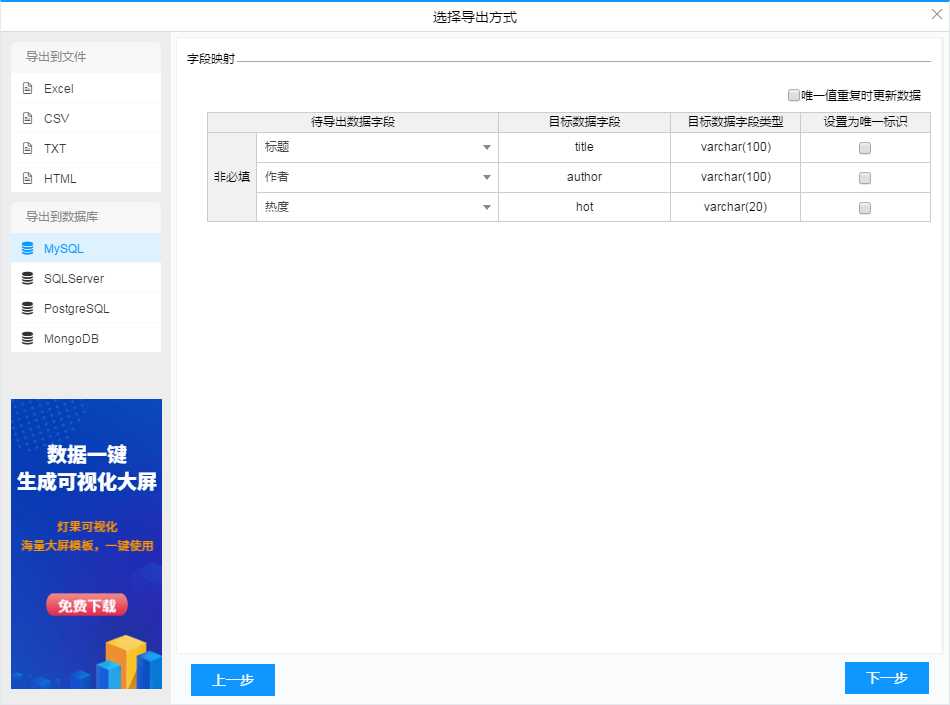
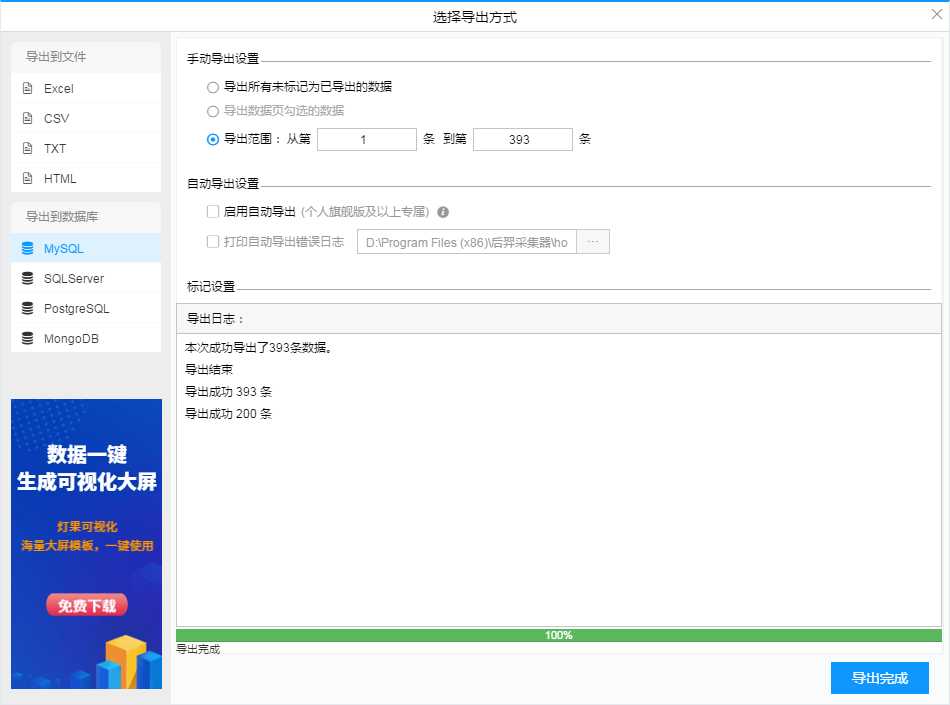
10、选择导出设置
11、查看mysql数据库里面的数据
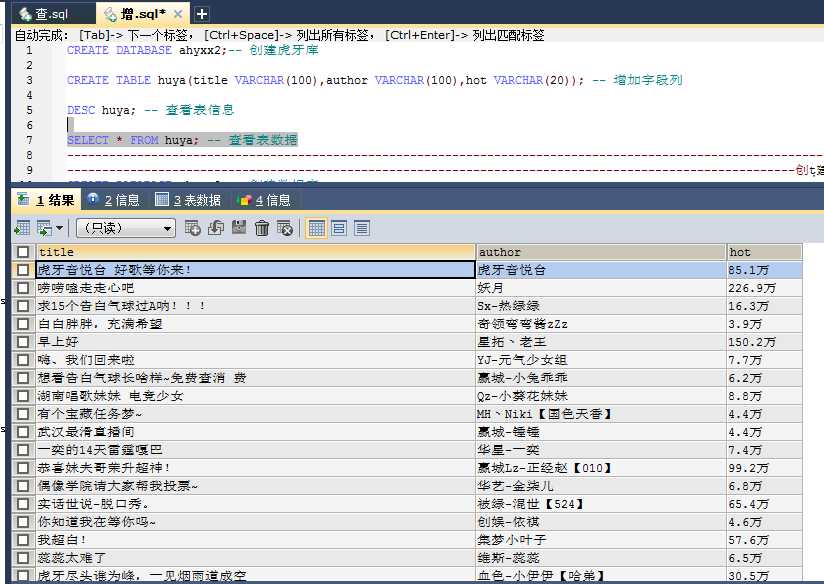
12、OK啦!好开心!!!
用代码开始操作
1、首先咱们创建个爬取的工程项目
scrapy startproject huyaPro
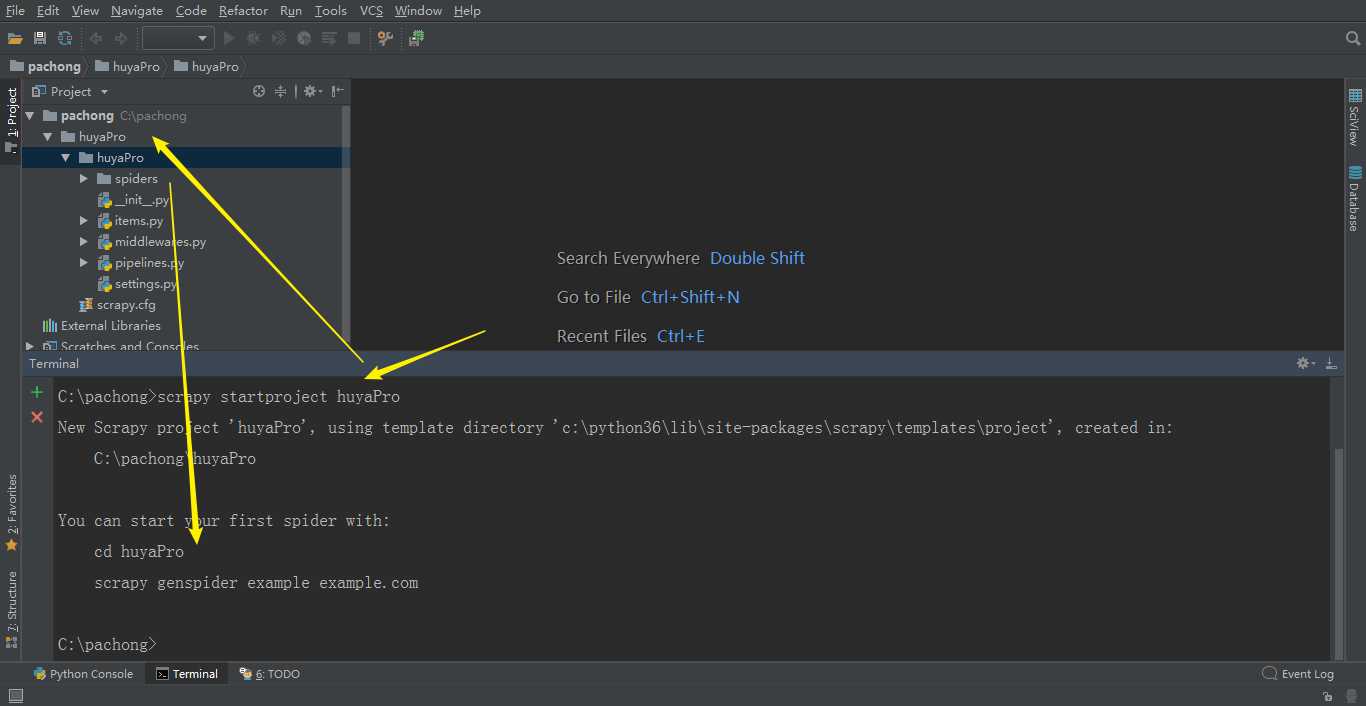
2、创建虫子
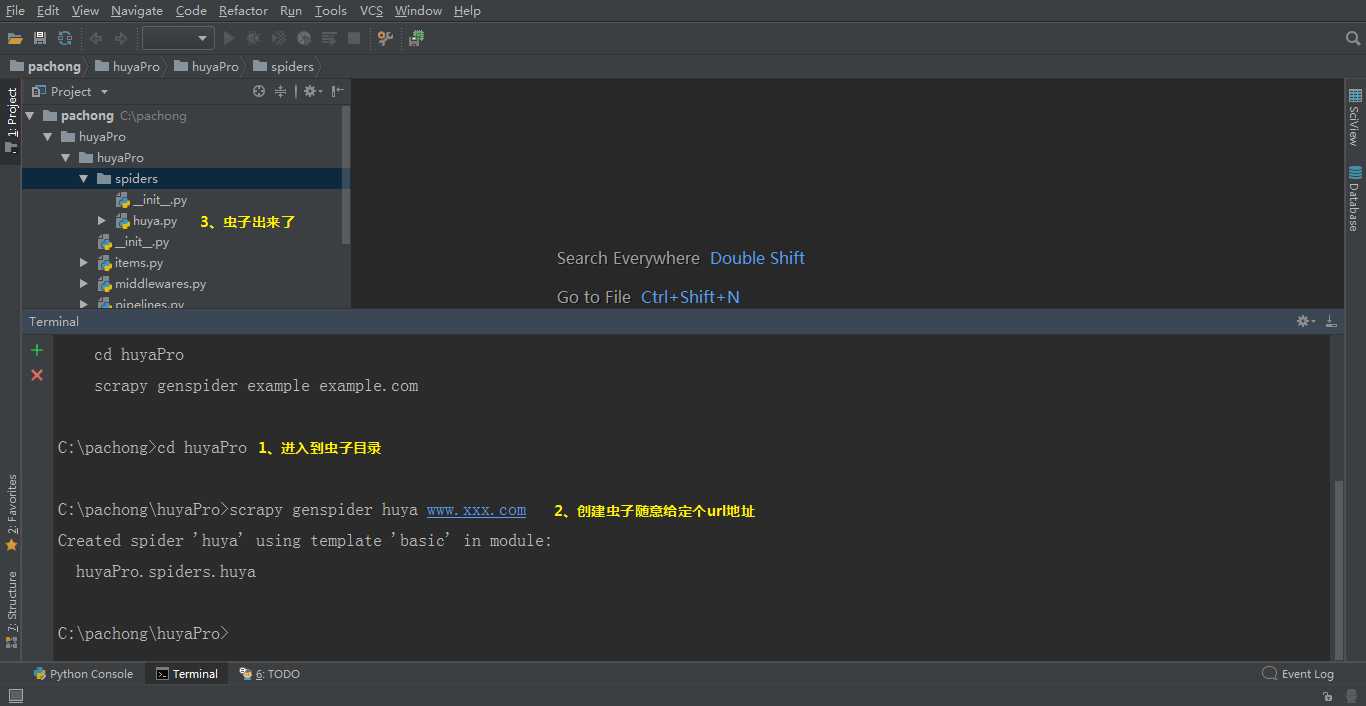
3、settings配置文件里面修改
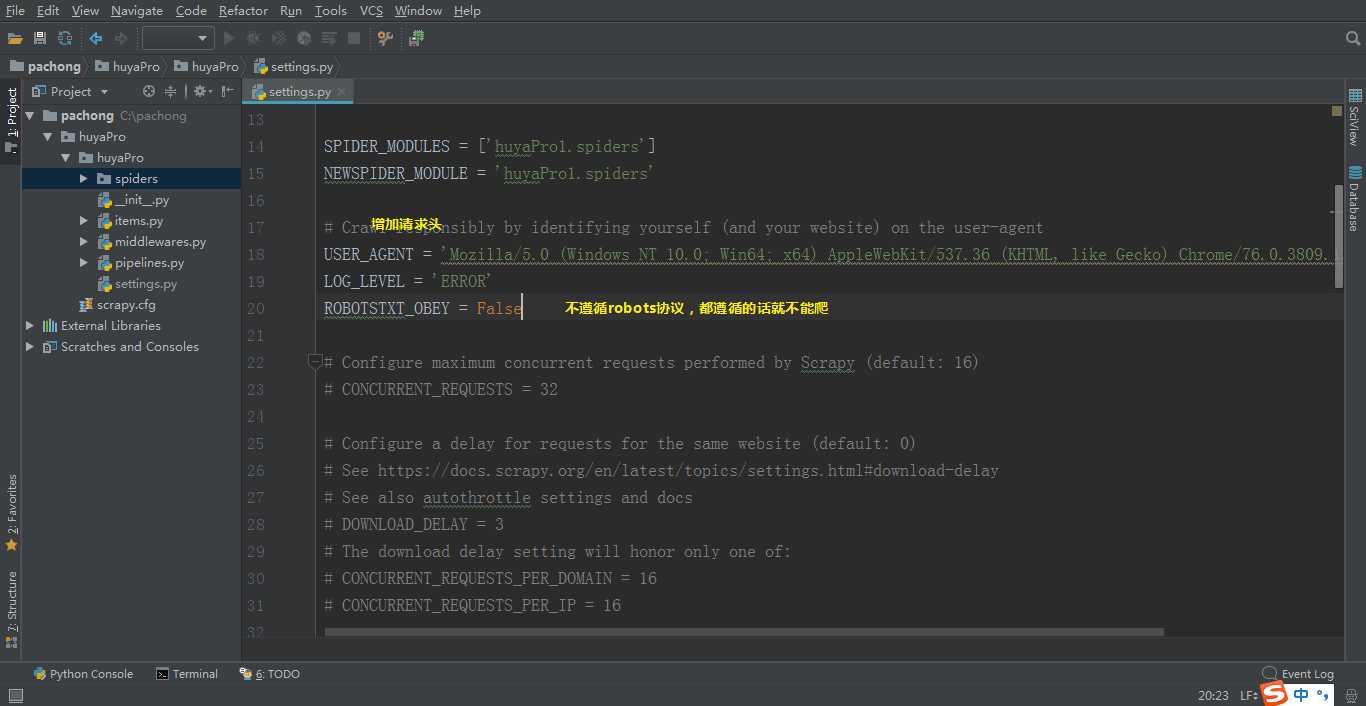
4、先看下数据试试
scrapy crawl huya
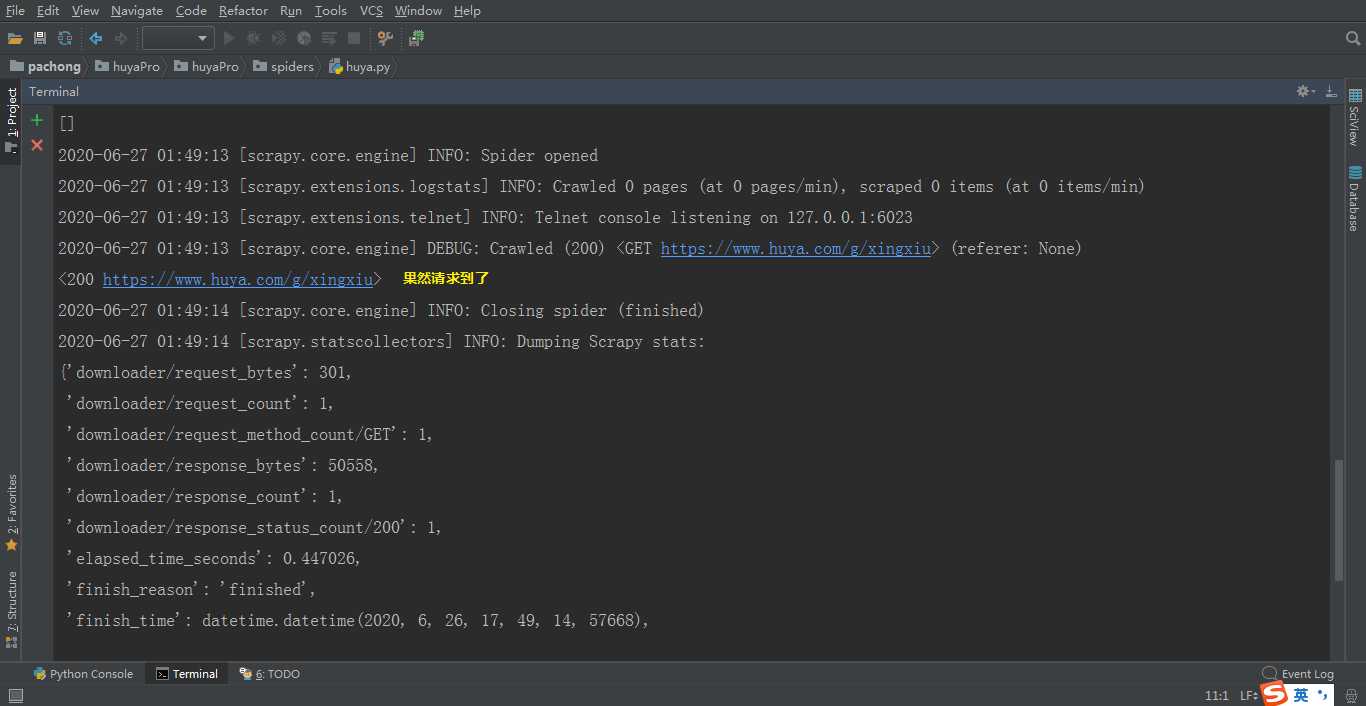
5、复制ul的xpath
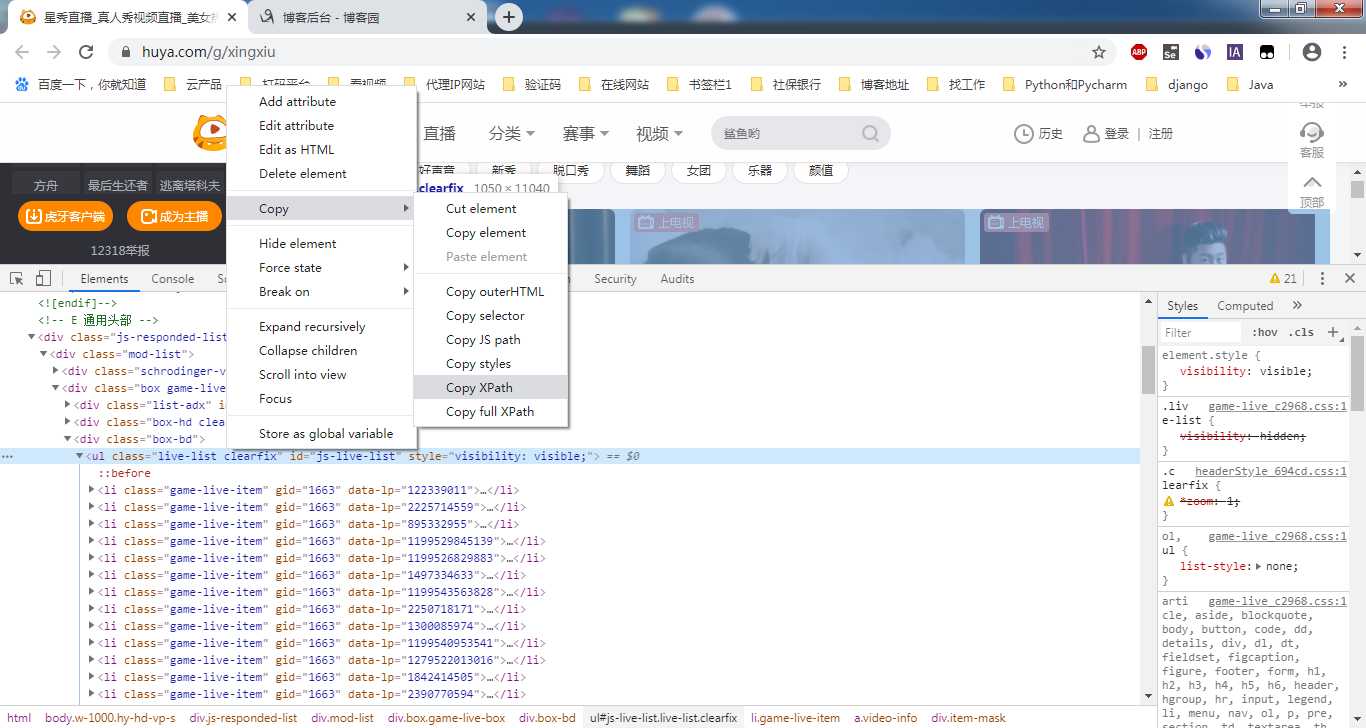
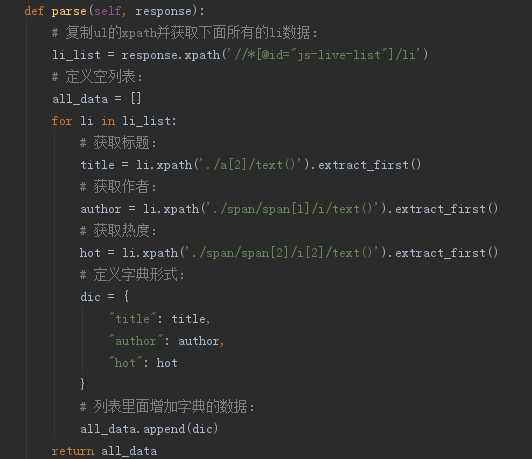
6、分别定位标题、作者、热度
import scrapy
class HuyaSpider(scrapy.Spider):
name = ‘huya‘
start_urls = [‘https://www.huya.com/g/xingxiu‘]
def parse(self, response):
# 复制ul的xpath并获取下面所有的li数据:
li_list = response.xpath(‘//*[@id="js-live-list"]/li‘)
# 定义空列表:
all_data = []
for li in li_list:
# 获取标题:
title = li.xpath(‘./a[2]/text()‘).extract_first()
# 获取作者:
author = li.xpath(‘./span/span[1]/i/text()‘).extract_first()
# 获取热度:
hot = li.xpath(‘./span/span[2]/i[2]/text()‘).extract_first()
# 定义字典形式:
dic = {
"title": title,
"author": author,
"hot": hot
}
# 列表里面增加字典的数据:
all_data.append(dic)
return all_data
7、存储到本地文件.csv格式
终端执行命令:scrapy crawl huya -o huya.csv


8、存储到mysql数据库

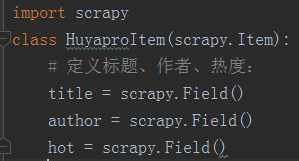
9、items.py
10、接下来管道处理
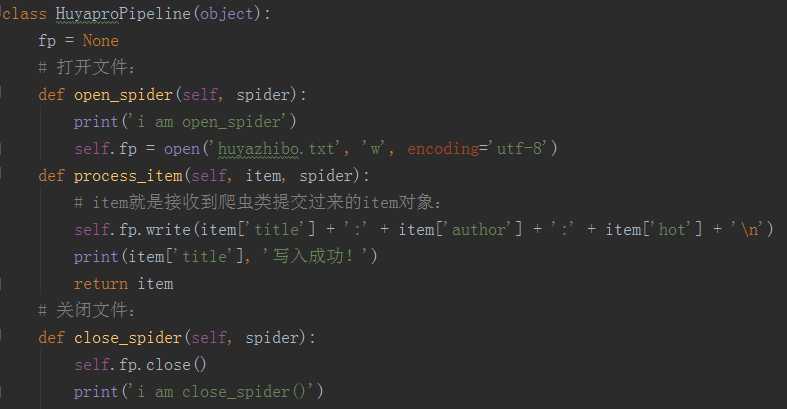
11、配置文件开启管道
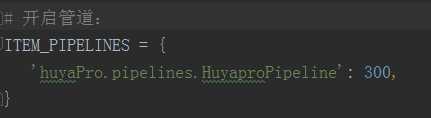
12、爬取到本地
终端执行命令:scrapy crawl huya

13、mysql配置部分

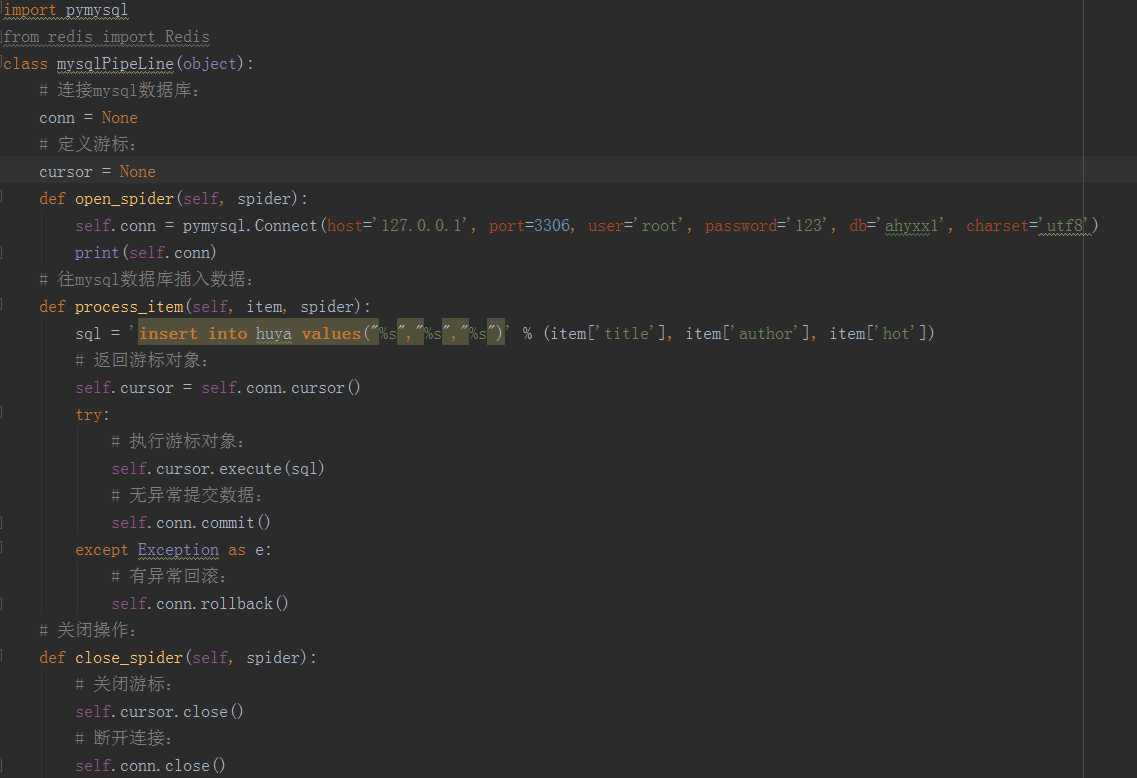
14、管道mysql
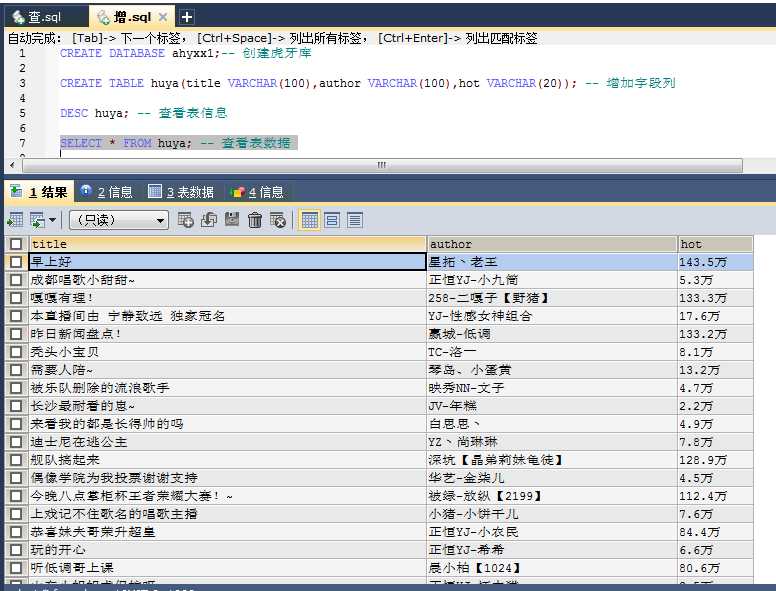
15、后台查数据
16、存储到redis
17、升级redis版本
pip install -U redis==2.10.6

18、终端执行命令
scrapy crawl huya
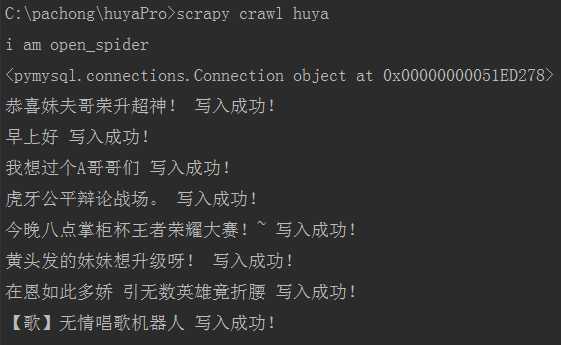
19、查看redis库
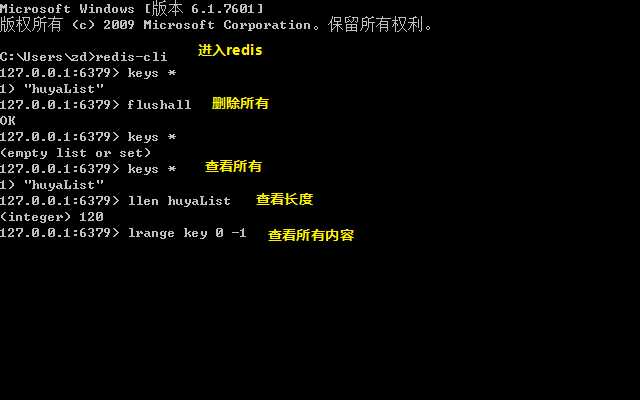
lrange huyaList 0 -1查看所有内容
原文:https://www.cnblogs.com/zhang-da/p/13197072.html?from=timeline
标签:运行 数据库 logs redis awl auth crawl app mys
原文地址:https://www.cnblogs.com/shiguanggege/p/13202732.html