标签:pos 编辑 type exp idt war 数据 miss 缩减
GBDT和XGB基本上是机器学习面试里面的必考题。最近面试了五十场面试,基本三分之二的面试官都问了关于GBDT和XGB的问题。
下面把里面常用的知识点、常见的面试题整理出来
首先来说集成学习
boosting
bagging
方差&偏差
方差:
GBDT主要的优点有:
GBDT的主要缺点有:
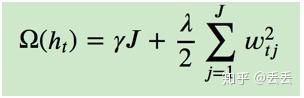 J是叶子节点的个数,w是滴j个叶子节点的最优质的
J是叶子节点的个数,w是滴j个叶子节点的最优质的
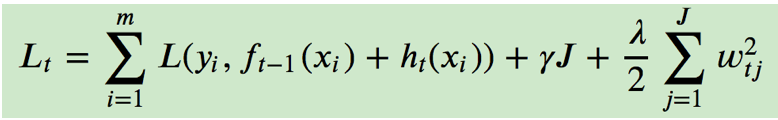
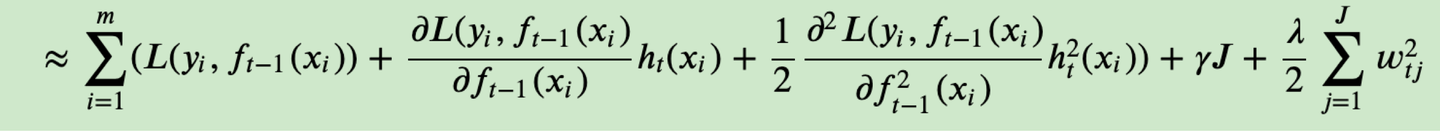
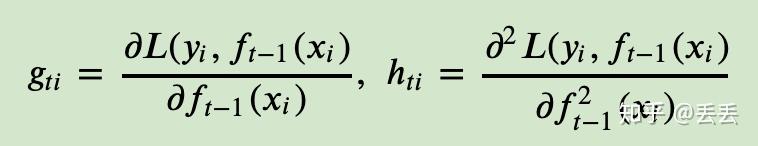
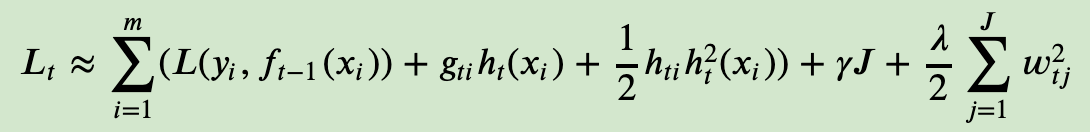

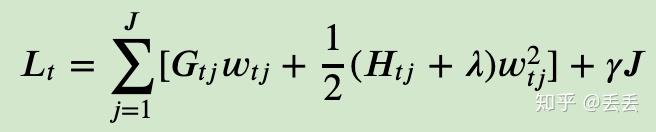
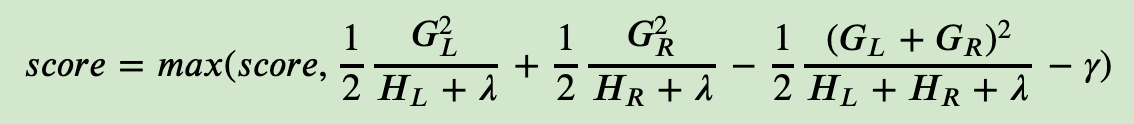

《一篇文章搞定GBDT、Xgboost和LightGBM的面试》
标签:pos 编辑 type exp idt war 数据 miss 缩减
原文地址:https://www.cnblogs.com/cx2016/p/13232616.html