标签:距离 抽象 xxx 维基 单词 psi 数据 情况下 中国
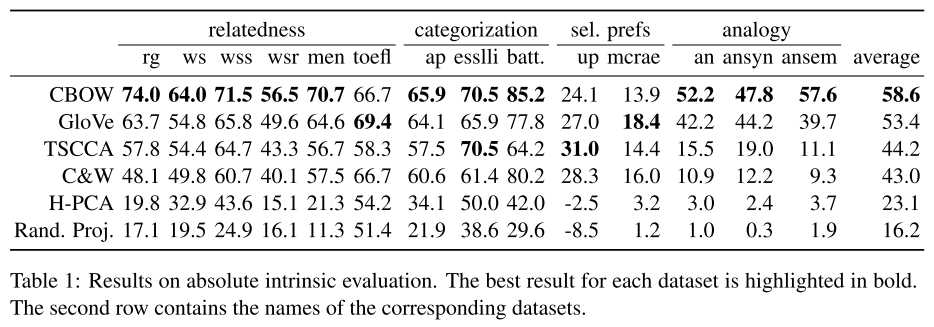
内在评估分为绝对内在评估和相对内在评估,绝对内在评估使用相同的数据集和相同的下游任务

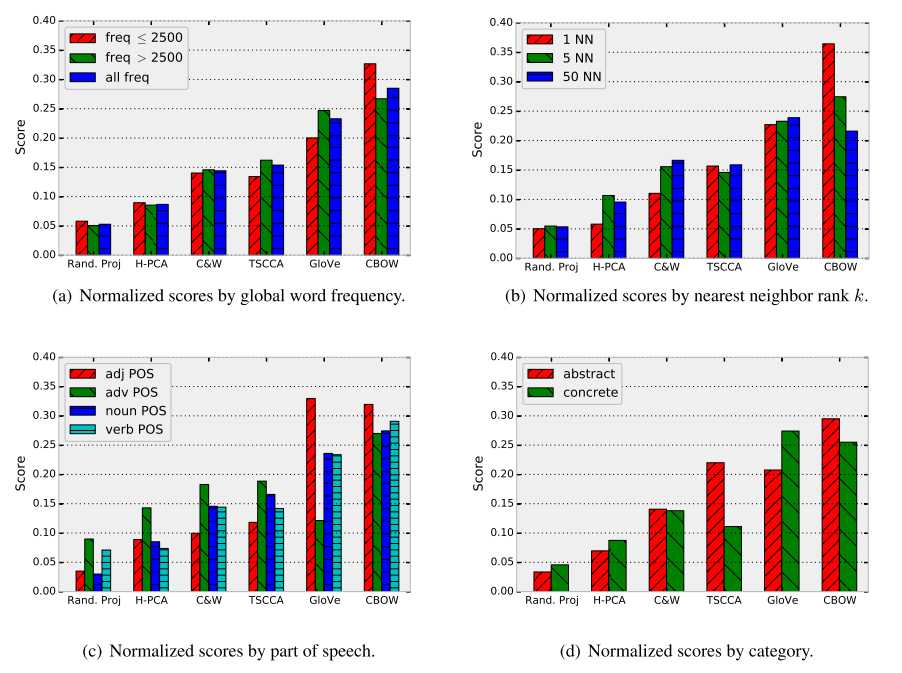
本部分考虑对于一个query word,人为选择2个语义相似度最高的单词以及一个语义不相关的干扰词,看上述6种embedding方法能否从4个词中找出不相关词,数据集使用相对内在评估使用的100个query word。
例子和实验结果分别如下图:

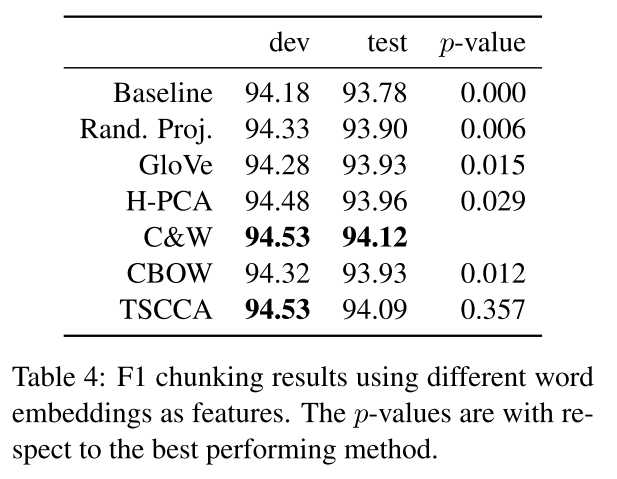
该评估方法有一个隐含假设:对于任何下游任务,都有一个全局一致的好的embedding表示,然鹅该假设不成立,即不同的下游任务有各自不同最适合的embedding。 emmmm..
论文实验了2个任务:Noun phrase chunking 和 Sentiment classification 得出了上述结论。
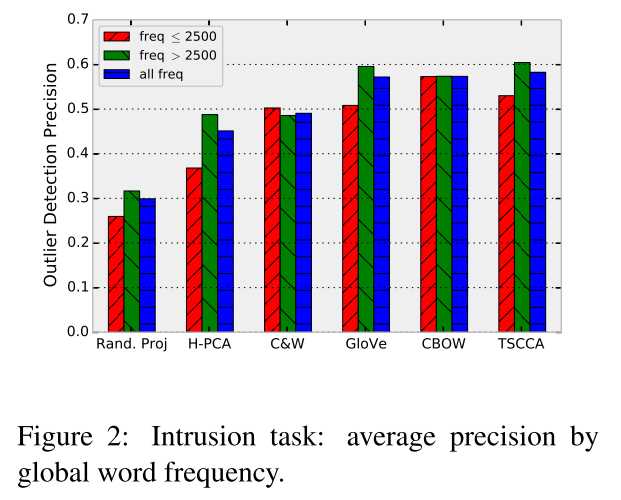
实验结果如下图:
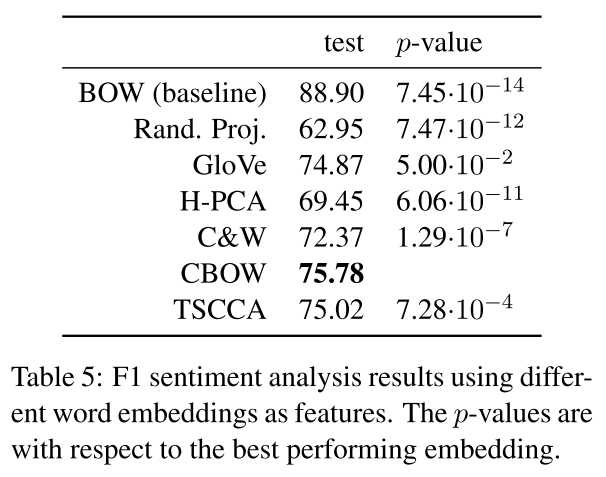
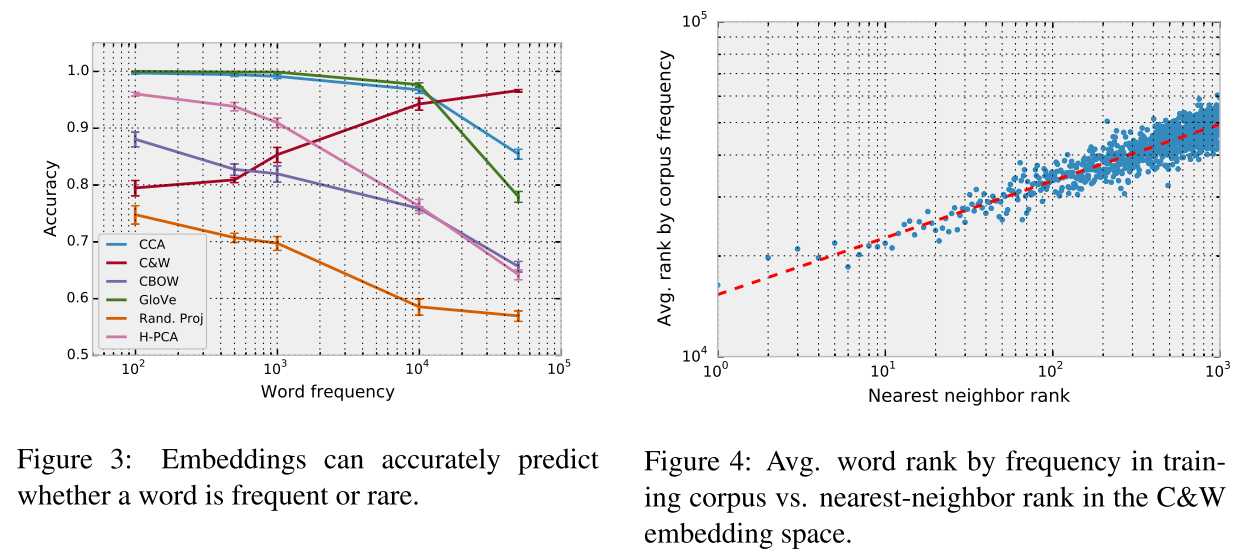
词embedding原本只是表示词语的语义信息,而作者在文中表示上述的embedding 方法或多或少的包含了词频信息,且query word的最近邻词和词频有关,同时质疑了余弦相似度作为衡量词语义相似性的合理性。
实验结果如下图:
对 【Evaluation methods for unsupervised word embeddings 】 的理解
标签:距离 抽象 xxx 维基 单词 psi 数据 情况下 中国
原文地址:https://www.cnblogs.com/andre-ma/p/13225678.html