标签:hadoop 集群 手工 src 检查 参数说明 enter cluster load table
Flink 的安装和部署主要分为本地(单机)模式和集群模式,其中本地模式只需直接解压就可以使用,不以修改任何参数,一般在做一些简单测试的时候使用。本地模式在我们的 课程里面不再赘述。集群模式包含:
u Standalone。
u Flink on Yarn。
u Mesos。
u Docker。
u Kubernetes。
u AWS。
u Goole Compute Engine。
目前在企业中使用最多的是 Flink on Yarn 模式。我们的课程中讲 Standalone 和 Flink on Yarn 这两种模式。
Flink 整个系统主要由两个组件组成,分别为 JobManager 和 TaskManager,Flink 架构也遵循 Master-Slave 架构设计原则,JobManager 为 Master 节点,TaskManager 为 Worker(Slave)节点。所有组件之间的通信都是借助于 Akka Framework,包括任务的状态以及Checkpoint 触发等信息。
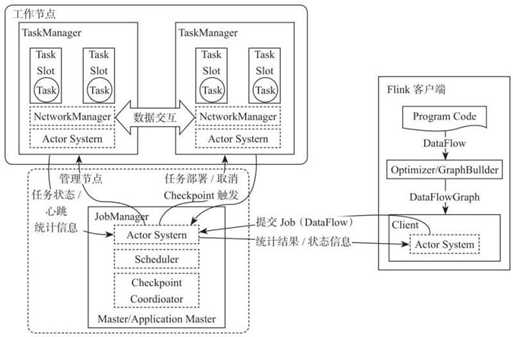
客户端负责将任务提交到集群,与 JobManager 构建 Akka 连接,然后将任务提交到JobManager,通过和 JobManager 之间进行交互获取任务执行状态。客户端提交任务可以采用 CLI 方式或者通过使用 Flink WebUI 提交,也可以在应用程序中指定 JobManager 的 RPC 网络端口构建 ExecutionEnvironment 提交 Flink 应用。
JobManager 负责整个 Flink 集群任务的调度以及资源的管理,从客户端中获取提交的应用,然后根据集群中 TaskManager 上 TaskSlot 的使用情况,为提交的应用分配相应的TaskSlots 资源并命令 TaskManger 启动从客户端中获取的应用。JobManager 相当于整个集群的 Master 节点,且整个集群中有且仅有一个活跃的 JobManager,负责整个集群的任务管理和资源管理。JobManager 和 TaskManager 之间通过 Actor System 进行通信,获取任务执行的情况并通过 Actor System 将应用的任务执行情况发送给客户端。同时在任务执行过程中,Flink JobManager 会触发 Checkpoints 操作,每个 TaskManager 节点收到 Checkpoint 触发指令后,完成 Checkpoint 操作,所有的 Checkpoint 协调过程都是在 Flink JobManager 中完成。当任务完成后,Flink 会将任务执行的信息反馈给客户端,并且释放掉 TaskManager 中的资源以供下一次提交任务使用。
TaskManager 相当于整个集群的 Slave 节点,负责具体的任务执行和对应任务在每个节点上的资源申请与管理。客户端通过将编写好的 Flink 应用编译打包,提交到 JobManager, 然后 JobManager 会根据已经注册在 JobManager 中 TaskManager 的资源情况,将任务分配给有资源的 TaskManager 节点,然后启动并运行任务。TaskManager 从 JobManager 接收需要部署的任务,然后使用 Slot 资源启动 Task,建立数据接入的网络连接,接收数据并开始数据处理。同时 TaskManager 之间的数据交互都是通过数据流的方式进行的。
可以看出,Flink 的任务运行其实是采用多线程的方式,这和 MapReduce 多 JVM 进程的方式有很大的区别Fink 能够极大提高CPU 使用效率,在多个任务和 Task 之间通过TaskSlot 方式共享系统资源,每个 TaskManager 中通过管理多个 TaskSlot 资源池进行对资源进行有效管理。
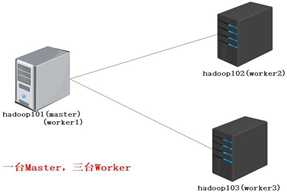
Standalone 是 Flink 的独立部署模式,它不依赖其他平台。在使用这种模式搭建 Flink 集群之前,需要先规划集群机器信息。在这里为了搭建一个标准的 Flink 集群,需要准备 3 台 Linux 机器,如图下所示。
3) 分发给另外两台服务器
4) 启动 Flink 集群服务
5) 访问 WebUI
6) 通过命令提交 job 到集群
7) 通过 WebUI 提交 job 到集群
8) 配置文件参数说明
下面针对 flink-conf.yaml 文件中的几个重要参数进行分析:
u jobmanager.heap.size:JobManager 节点可用的内存大小。
u taskmanager.heap.size:TaskManager 节点可用的内存大小。
u taskmanager.numberOfTaskSlots:每台机器可用的 Slot 数量。
u parallelism.default:默认情况下 Flink 任务的并行度。上面参数中所说的 Slot 和 parallelism 的区别:
u Slot 是静态的概念,是指 TaskManager 具有的并发执行能力。
u parallelism 是动态的概念,是指程序运行时实际使用的并发能力。
u 设置合适的 parallelism 能提高运算效率。
Flink on Yarn 模式的原理是依靠 YARN 来调度 Flink 任务,目前在企业中使用较多。这种模式的好处是可以充分利用集群资源,提高集群机器的利用率,并且只需要 1 套 Hadoop 集群,就可以执行 MapReduce 和 Spark 任务,还可以执行 Flink 任务等,操作非常方便,不需要维护多套集群,运维方面也很轻松。Flink on Yarn 模式需要依赖 Hadoop 集群,并且Hadoop 的版本需要是 2.2 及以上。我们的课程里面选择的 Hadoop 版本是 2.7.2。
Flink On Yarn 的内部实现原理:
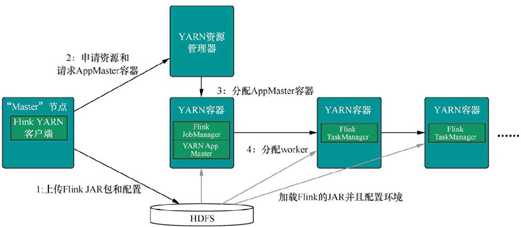
l 当启动一个新的 Flink YARN Client 会话时,客户端首先会检查所请求的资源(容器和内存)是否可用。之后,它会上传 Flink 配置和 JAR 文件到 HDFS。
l 客户端的下一步是请求一个 YARN 容器启动 ApplicationMaster 。 JobManager 和ApplicationMaster(AM)运行在同一个容器中,一旦它们成功地启动了,AM 就能够知道JobManager 的地址,它会为 TaskManager 生成一个新的 Flink 配置文件(这样它才能连上 JobManager),该文件也同样会被上传到 HDFS。另外,AM 容器还提供了 Flink 的Web 界面服务。Flink 用来提供服务的端口是由用户和应用程序 ID 作为偏移配置的,这使得用户能够并行执行多个 YARN 会话。
l 之后,AM 开始为 Flink 的 TaskManager 分配容器(Container),从 HDFS 下载 JAR 文件和修改过的配置文件。一旦这些步骤完成了,Flink 就安装完成并准备接受任务了。
u 第 1 种模式(Session-Cluster):是在 YARN 中提前初始化一个 Flink 集群(称为 Flink yarn-session),开辟指定的资源,以后的 Flink 任务都提交到这里。这个 Flink 集群会常驻在 YARN 集群中,除非手工停止。这种方式创建的 Flink 集群会独占资源,不管有没有 Flink 任务在执行,YARN 上面的其他任务都无法使用这些资源。
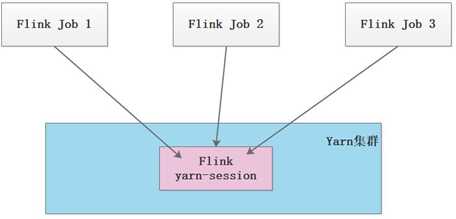
u 第 2 种模式(Per-Job-Cluster):每次提交 Flink 任务都会创建一个新的 Flink 集群, 每个 Flink 任务之间相互独立、互不影响,管理方便。任务执行完成之后创建的 Flink 集群也会消失,不会额外占用资源,按需使用,这使资源利用率达到最大,在工作中推荐使用这种模式。
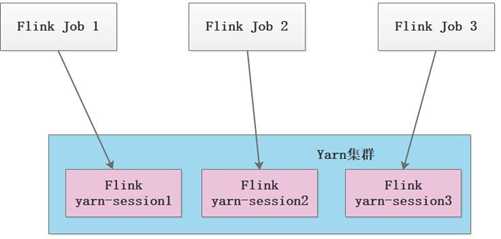
注意:Flink on Yarn 还需要两个先决条件:
u 配置 Hadoop 的环境变量
u 下载 Flink 提交到 Hadoop 的连接器(jar 包),并把 jar 拷贝到 Flink 的 lib 目录下
先启动 Hadoop 集群,然后通过命令启动一个 Flink 的 yarn-session 集群:
其中 yarn-session.sh 后面支持多个参数。下面针对一些常见的参数进行讲解:
u -n,--container <arg> 表示分配容器的数量(也就是 TaskManager 的数量)。
u -D <arg> 动态属性。
u -d,--detached 在后台独立运行。
u -jm,--jobManagerMemory <arg>:设置 JobManager 的内存,单位是 MB。
u -nm,--name:在 YARN 上为一个自定义的应用设置一个名字。
u -q,--query:显示 YARN 中可用的资源(内存、cpu 核数)。
u -qu,--queue <arg>:指定 YARN 队列。
u -s,--slots <arg>:每个 TaskManager 使用的 Slot 数量。
u -tm,--taskManagerMemory <arg>:每个 TaskManager 的内存,单位是 MB。
u -z,--zookeeperNamespace <arg>:针对 HA 模式在 ZooKeeper 上创建 NameSpace。
-id,--applicationId <yarnAppId>:指定 YARN 集群上的任务 ID,附着到一个后台独立运行的 yarn
session 中。
查看 WebUI: 由于还没有提交 Flink job,所以都是 0。
这个时候注意查看本地文件系统中有一个临时文件。有了这个文件可以提交 job 到 Yarn
u -yn,--container <arg> 表示分配容器的数量,也就是 TaskManager 的数量。
u -d,--detached:设置在后台运行。
u -yjm,--jobManagerMemory<arg>:设置 JobManager 的内存,单位是 MB。
u -ytm,--taskManagerMemory<arg>:设置每个 TaskManager 的内存,单位是 MB。
u -ynm,--name:给当前 Flink application 在 Yarn 上指定名称。
u -yq,--query:显示 yarn 中可用的资源(内存、cpu 核数)
u -yqu,--queue<arg> :指定 yarn 资源队列
u -ys,--slots<arg> :每个 TaskManager 使用的 Slot 数量。
u -yz,--zookeeperNamespace<arg>:针对 HA 模式在 Zookeeper 上创建 NameSpace
u -yid,--applicationID<yarnAppId> : 指定 Yarn 集群上的任务 ID,附着到一个后台独立运行的 Yarn Session 中。
默认情况下,每个 Flink 集群只有一个 JobManager,这将导致单点故障(SPOF),如果这个 JobManager 挂了, 则不能提交新的任务, 并且运行中的程序也会失败。使用JobManager HA,集群可以从 JobManager 故障中恢复,从而避免单点故障。用户可以在Standalone 或 Flink on Yarn 集群模式下配置 Flink 集群 HA(高可用性)。
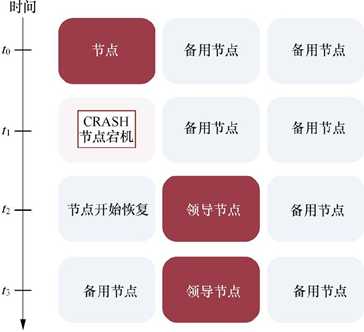
Standalone 模式下,JobManager 的高可用性的基本思想是,任何时候都有一个 Alive JobManager 和多个 Standby JobManager。Standby JobManager 可以在 Alive JobManager 挂掉的情况下接管集群成为
Alive JobManager,这样避免了单点故障,一旦某一个 Standby JobManager 接管集群,程序就可以继续运行。Standby JobManagers 和 Alive JobManager 实例之间没有明确区别,每个 JobManager 都可以成为 Alive 或 Standby。
实现 HA 还需要依赖 ZooKeeper 和 HDFS,因此要有一个 ZooKeeper 集群和 Hadoop 集群,
修改配置文件 conf/masters
首先启动 Zookeeper 集群和 HDFS 集群。我们的课程中分配 3 台 JobManager,如下表:
|
hadoop101 |
hadoop102 |
hadoop103 |
|
JobManager |
JobManager |
JobManager |
|
TaskManager |
TaskManager |
TaskManager |
修改配置文件 conf/flink-conf.yaml
|
#要启用高可用,设置修改为zookeeper high-availability: zookeeper #Zookeeper的主机名和端口信息,多个参数之间用逗号隔开high-availability.zookeeper.quorum: hadoop103:2181,hadoop101:2181,hadoop102:2181 # 建议指定HDFS的全路径。如果某个Flink节点没有配置HDFS的话,不指定HDFS的全路径则无法识到,storageDir存储了恢复一个JobManager所需的所有元数据。 high-availability.storageDir: hdfs://hadoop101:9000/flink/h |
|
[root@hadoop101 conf]# scp masters flink-conf.yaml root@hadoop102:`pwd` [root@hadoop101 conf]# scp masters flink-conf.yaml root@hadoop103:`pwd` |
把修改的配置文件拷贝其他服务器中
启动集群
版本问题:目前使用 Flink1.7.1 版本测试没有问题,使用 Flink1.9 版本存在 HA 界面不能
自动跳转到对应的 Alive JobManager 的现象。
正常基于 Yarn 提交 Flink 程序,无论是使用 yarn-session 模式还是 yarn-cluster 模式 , 基 于 yarn 运 行 后 的 application 只 要 kill 掉 对 应 的 Flink 集 群 进 程“YarnSessionClusterEntrypoint”后,基于 Yarn 的 Flink 任务就失败了,不会自动进行重试,所以基于 Yarn 运行 Flink 任务,也有必要搭建 HA,这里同样还是需要借助 zookeeper 来完成,步骤如下:
修改所有 Hadoop 节点的 yarn-site.xml
|
#在每台hadoop节点yarn-site.xml中设置提交应用程序的最大尝试次数,建议不低于4,这里 重试指的是ApplicationMaster <property> <name>yarn.resourcemanager.am.max-attempts</name> <value>4</value> </property> |
将所有 Hadoop 节点的 yarn-site.xml 中的提交应用程序最大尝试次数调大
启动 Hadoop 集群
#在每台hadoop节点yarn-site.xml中设置提交应用程序的最大尝试次数,建议不低于4,这里 重试指的是ApplicationMaster
<property>
<name>yarn.resourcemanager.am.max-attempts</name>
<value>4</value>
</property>
启动 zookeeper,启动 Hadoop 集群。
|
#配置依赖zookeeper模式进行HA搭建high-availability: zookeeper #配置JobManager原数据存储路径 high-availability.storageDir: hdfs://hadoop101:9000/flink/yarnha/ #配置zookeeper集群节点 high-availability.zookeeper.quorum: hadoop101:2181,hadoop102:2181,hadoop103:2181 #yarn停止一个application重试的次数yarn.application-attempts: 10 |
修改 Flink 对应 flink-conf.yaml 配置
|
#配置依赖zookeeper模式进行HA搭建high-availability: zookeeper #配置JobManager原数据存储路径 high-availability.storageDir: hdfs://hadoop101:9000/flink/yarnha/ #配置zookeeper集群节点 high-availability.zookeeper.quorum: hadoop101:2181,hadoop102:2181,hadoop103:2181 #yarn停止一个application重试的次数yarn.application-attempts: 10 |
配置对应的 conf 下的 flink-conf.yaml,配置内容如下:
启动 yarn-session.sh 测试 HA: yarn-session.sh -n 2 ,也可以直接提交 Job 启动之后,可以登录 yarn 中对应的 flink webui,如下图示:
点击对应的 Tracking UI,进入 Flink 集群 UI:
查看对应的 JobManager 在哪台节点上启动:
进入对应的节点,kill 掉对应的“YarnSessionClusterEntrypoint”进程。然后进入到 Yarn 中观察“applicationxxxx_0001”job 信息:
点击 job ID,发现会有对应的重试信息:
点击对应的“Tracking UI”进入到 Flink 集群 UI,查看新的 JobManager 节点由原来的hadoop103
变成了 hadoop101,说明 HA 起作用。
Flink 中每一个worker(TaskManager)都是一个JVM 进程,它可能会在独立的线程(Solt) 上执行一个或多个 subtask。Flink 的每个 TaskManager 为集群提供 Solt。Solt 的数量通常与每个 TaskManager 节点的可用 CPU 内核数成比例,一般情况下 Slot 的数量就是每个节点的 CPU 的核数。
Slot 的 数 量 由 集 群 中 flink-conf.yaml 配 置 文 件 中 设 置taskmanager.numberOfTaskSlots 的值为 3,这个值的大小建议和节点 CPU 的数量保持一致。
一个任务的并行度设置可以从 4 个层面指定:
u Operator Level(算子层面)。
u Execution Environment Level(执行环境层面)。
u Client Level(客户端层面)。
u System Level(系统层面)。
这 些 并 行 度 的 优 先 级 为 Operator Level>Execution Environment Level>Client Level>System Level。
Operator、Source 和 Sink 目的地的并行度可以通过调用 setParallelism()方法来指定
任务的默认并行度可以通过调用 setParallelism()方法指定。为了以并行度 3 来执行所有的 Operator、Source 和 Sink,可以通过如下方式设置执行环境的并行度
并行度还可以在客户端提交 Job 到 Flink 时设定。对于 CLI 客户端,可以通过-p 参数
指定并行度。
在系统级可以通过设置flink-conf.yaml 文件中的parallelism.default 属性来指定所有执行环境的默认并行度。
Flink 集群中有 3 个 TaskManager 节点,每个 TaskManager 的 Slot 数量为 3
标签:hadoop 集群 手工 src 检查 参数说明 enter cluster load table
原文地址:https://www.cnblogs.com/tesla-turing/p/13260062.html