标签:评估 enable 多核 乘法器 http 方案 积分 算法 处理
电阻存储器为edge-AI提供了仿生架构
Resistive memories enable bio-inspired architectures for edge AI
近年来,脑启发计算领域的研究活动取得了很大的发展势头。其主要原因是人试图超越传统Von Neumann体系结构的局限性,这种局限性越来越受到存储器逻辑通信带宽和延迟的限制。在神经形态结构中,存储是分布的,并且可以与逻辑共同定位。新的电阻存储器技术可以很容易地提供这种可能性,因为能够集成在CMOS工艺的互连层中。
在传统的人工智能技术被广泛应用于集成电路的实现中,受到了广泛的关注。虽然先进的标准CMOS技术已经被用于开发GPU和特定的电路加速器,但还没有真正推动使用任何“生物灵感”硬件。新出现的电阻存储器件(rram)可以通过施加相对较低的偏压来调节电导,从而在纳米尺度上模拟生物上看似合理的突触行为,但由于这项技术的(感知)不够成熟,所开辟的途径仅限于研究小组。
然而,这些新设备可以解决将人工智能大规模部署到消费和工业产品中所面临的一个主要问题:能源效率。如果人工智能的应用越来越广泛,将所有数据传输到云/服务器系统进行分析的能源开销将很快达到人工智能经济可行性的极限。此外,对于自动车辆和工业控制等实时系统,如果连接到5G基础设施以处理数据的服务器集中在定义明确的区域,而不是分布在基础设施中,那么延迟仍然是一个问题。出于这些原因,在欧洲,出于隐私考虑,具有边缘/使用点的人工智能系统将变得越来越重要,高效节能,并可能逐步提高本地学习能力。
嵌入式人工智能系统非常适合处理需要实时响应的数据,并且在能源是主要问题的情况下。tinyML倡议的成功证明了人对此类系统的兴趣正在增长。在处理由麦克风、激光雷达、超声波等传感器生成的稀疏、时域数据流时,该领域的生物启发(即,存储元件也充当互连和计算元件)方法具有额外的优势。然后,这些系统将能够在模拟域中执行大部分操作,通过避免耗电、不必要的多个模拟到数字转换,以及使用非时钟、数据驱动的体系结构来简化数据流。时钟的缺失和仅在信号脉冲期间在存储器元件中的耗散导致在没有输入的情况下极低的功耗(因此其适用于稀疏信号),并且可能不需要特定的睡眠模式来获得电池供电的操作状态。此外,非易失性只需要在系统首次通电或最终更新时进行参数设置,而不需要在每次通电时从外部源进行传输。
然而,新电阻存储器的使用不仅限于这种“边缘”或“生物灵感”的应用,而且也有利于在神经加速器中执行慢非易失性缓存/快速大容量存储中间存储器电平功能的传统全数字时钟系统。在这种情况下,这样做的好处是减少了快速DRAM和SRAM缓存区域,同时还减少了访问大容量存储的延迟。
Hardware Platforms for bio-inspired computing
生物启发计算的硬件平台
从技术角度来看,rram是一个很好的神经形态应用的候选,因为具有CMOS兼容性、高扩展性、强持久性和良好的保留特性。然而,定义大规模共集成混合神经形态系统(具有电阻存储突触的CMOS神经元)的实际实现策略和有用的应用仍然是一个困难的挑战。
电阻RAM(RRAM)器件如相变存储器(PCM)、导电桥RAM(CBRAM)和氧化物RAM(OxRAM)被提出来模拟突触功能的生物学特性,这些特性对于实现神经形态硬件是必不可少的。在不同类型的模拟突触特征中,尖峰时间依赖性可塑性(STDP)是最常用的方法之一,但肯定不是唯一的可能性,有些可能在实际应用中更有用。
实现这些想法并验证方法的电路示例是SPIRIT,ay IEDM 2019提出。所实现的SNN拓扑是一个单层的、全连通的拓扑,其目标是在MNIST数据库上执行推理任务,每个类有10个输出神经元。为了减少突触的数量,图像缩小到12×12像素(每个神经元有144个突触)。突触是用单级细胞(SLC)rram实现的,即只考虑低电阻和高电阻水平。结构为1T-1R型,每个单元有一个接入晶体管。多个电池并联连接,以实现不同的重量。在该学习框架上进行的突触量化实验表明,在-4到+4之间的整数值是分类精度和RRAM数之间的一个很好的折衷。由于目标是获得加权电流,因此必须使用4 rram作为正权重。对于负权重,符号位也可以使用rram进行编码:但是,由于需要容错的三重冗余,因此最好使用4个附加rram来实现负权重。
“整合与激发(IF)”模拟神经元的设计是由数学等价性的需要指导的,tanh激活函数用于有监督的离线学习。其特征如下:(1)突触重量等于±4的刺激必须产生一个尖峰;(2)神经元必须产生正负尖峰;(3)必须有一个不应期,在此期间不能发出尖峰,但必须继续整合。神经元是围绕一个MOM 200fF电容器构建的。两个比较器用于比较其电压电平与正负阈值。由于RRAM必须在其终端之间的电压降限制为100mV的情况下读取,为了防止将设备设置为LRS,获得的电流不能被神经元直接积分,而是由电流注入器复制。评估了编程条件的影响,并使用适当的编程条件来确保足够大的内存窗口。放松机制确实出现在很短的时间尺度上(不到一个小时)。因此,分类精度不会随着时间的推移而降低。读取稳定性也得到了验证,高达800米的峰值发送到电路。
对MNIST数据库的10K测试图像的分类准确率为84%。必须将该值与从88%的理想模拟中获得的精度进行比较,该精度受简单网络拓扑结构(1层10个输出神经元)的限制。每个突触事件的能量消耗相当于3.6pj。当考虑到电路逻辑和SPI接口时,达到了180pj(可以通过优化通信协议来降低)。测量表明,图像分类平均需要136个输入峰值(对于ΔS=10):这小于每个输入累积的一个峰值,与130nm节点中等效的形式编码MAC操作相比,能量增益是5倍。能量增益来自于(1)基运算的轻巧性(累加,而不是经典编码中的乘法累加);(2)尖峰编码导致的活动稀疏性。稀疏效益随层数的增加而增加。
这个小的演示程序展示了如何在与传统的嵌入式方法相同的性能水平上实现性能水平,但功耗却大大降低。事实上,SNN演示中使用的速率码使得这种实现与经典编码的实现等效:从经典域到峰值域的转换不会导致任何精度损失。然而,从这个概念证明中使用的简单拓扑结构来看,与使用更大网络和更多层的最先进深度学习模型相比,单层感知器解释的分类精度略低。为了克服这一差异,目前正在实施一种更为复杂的拓扑结构(MobileNet类),分类精度将相应提高,同时具有相同的能量效益。
同样的方法将扩展到嵌入麦克风或激光雷达的电路中,以本地和实时地分析数据流,从而避免了通过网络传输的需要。速率编码和时间编码都可以根据信号的信息量来优化网络。最初,学习将集中进行,只有推理集成到系统中,但在以后的几代人中会引入一定程度的增量学习。
另一种利用RRAM特性有益于嵌入式AI产品的方法是使用基于RRAM的crossbar阵列的模拟架构。与传统的数字实现相比,可以提供更密集的乘法器-累加器(MAC)功能的实现,在推理和学习电路中都是核心。如果进入时域并消除时钟的进一步步骤被采取,那么超越当前技术水平的紧凑型低功耗系统是可以实现的。虽然这种方法非常有前途,学术界也进行了大量的研究,但仍然没有被业界广泛接受,这表明了设计、验证、描述和验证模拟异步设计的困难,以及扩展模拟解决方案的困难。在看来,所有这些障碍都是可以克服的,有利于极为节能的解决方案。
这些存储的部分感知困难来自于观察到的可变性,但那是实验条件的反射。观察到在300毫米范围内操作和集成过程更加成熟时,分布会更好,因此假设在工业化过程中可以解决变异性问题。设计工具也在出现,更精确的模型也逐渐可用。温度变化当然会产生影响,但这种计算的统计性质及其在推断阶段对某种程度的参数变化的内在稳健性,使其最终影响远不如社区习惯的传统模拟设计相关。模拟纵横制方法的优点之一是,当应用“零”数据时,自动没有电流。然而,当应用“一”数据时,存储的“零”值存在泄漏电流贡献,这会限制横杆的合理尺寸,并推动研究朝着电阻水平的最佳值方向发展。
有些问题更为根本。第一个问题是,功耗效率和高并行度来自于时间复用(操作频率)与面积的权衡:网络大小(问题或类数大小)的限制是什么?这种权衡是有利的,如何依赖于实现节点?另一个是这些存储的循环性。虽然对于推理阶段来说已经足够了,并且交叉杆的编程可以在初始化阶段以可接受的开销完成,但是由于过度的写入负载,使用经典反向传播方案和迭代次数的片上学习是不可能的。然而,使用其学习方法的非常有希望的途径正在被寻求,并有望在未来几年内提供有效的解决方案。
在引入这种类型的电路之前,像RRAM和3D集成这样的技术可以在传统的实现中使用,从而以更小的功耗预算和更小的外形因数提供已经存在的解决方案。用于高度定制应用的FPGA实现、运行在mcu或cpu上的纯软件实现或专用的高度并行的多核/加速器(类似或类似于gpu的通用应用)是当今的主流。所有这些芯片还可以受益于本地非易失性存储器的可用性,这可能导致FPGA更紧凑、更优化的MCU/CPU和多核/加速器芯片的存储层次。特别是,使用单片3D集成的专用版本,在模拟神经元平面之间插入RRAM平面,可以产生更紧凑、功耗更低的系统。
在欧洲H2020计划NeuRAM3的框架下,研究了这种方法,领导了一个著名的欧盟研发机构多学科小组,致力于研究先进器件技术、电路结构和算法之间的最佳匹配,以制造神经形态芯片。在该项目的许多结果中,如下图所示,可以看到在CoolCube 3D单片工艺中制造的OxRAM示例,该工艺连接到顶部和底部CMOS层。向前看,这种技术可以用于在专门用于人工智能的复杂CMOS电路结构中集成非常密集的阵列。
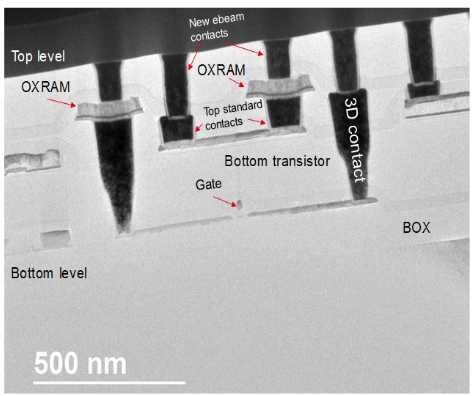
图. CoolCube 3D单片集成OxRam内部互连
顶部和底部的CMOS层为密集多层神经网络开辟了道路。
3DTSV和3D-by-Cu键合也有希望具有紧凑的神经形态系统,包括高度集成的体系结构中的各种元件,其中根据应用优化分区,或者嵌入AI元件与成像仪或其传感或执行元件紧密耦合。
结论
本文综述了RRAM在仿生计算系统中的作用,并讨论了一些有希望的结果和概念。
标签:评估 enable 多核 乘法器 http 方案 积分 算法 处理
原文地址:https://www.cnblogs.com/wujianming-110117/p/13266273.html