标签:图像 精度 系统 rto lazy 表示 基准测试 限制 人工智
面向汽车应用的硬件推理芯片
Hardware inference chip targets automotive applications
总部位于匈牙利的AImotive是一家基于软件和硬件的自动驾驶技术的开发商,该公司已开始向其主要客户发货其aiWare3神经网络(NN)硬件推理引擎知识产权(IP)。
aiWare3P IP核去年发布,为高分辨率汽车视觉应用提供硬件NN加速器,并作为ISO26262 ASIL a、B及以上认证子系统的组件。核心可以部署在片上系统(SoC)中,也可以作为独立的NN加速器,以完全可合成的RTL形式提供;低层微体系结构设计成使用比其硬件NN加速器更少的主机CPU或共享内存资源。
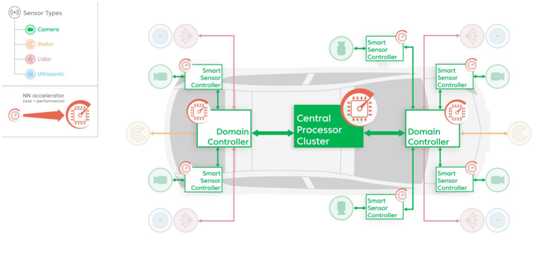
专用NN加速器,如aiWare3P IP,用于车辆电子平台的各个部分
该公司的执行顾问托尼·金·史密斯(Tony King Smith)在接受《欧洲电子时报》采访时谈到AIMotive与其解决方案的不同之处时说,大多数芯片厂商都是用学术术语谈论基于GPU和SOC的加速器,在实验室环境中进行了测试,但这并不能很好地反映到现实世界中。“关键的区别在于,有必要了解神经网络的原理,而不是加速器。在解决方案中,没有dsp,也没有片上网络(network-on-chip)。aiWare只为自动推理而设计,因此能够提供从输入到输出的低延迟。”补充说,新内核的RTL输出改进意味着释放了主CPU子系统,然后核心可以连接到任何加速器SoC。
aiWare3P IP核包含了一些特性,这些特性提高了性能,降低了功耗,更大的主机CPU负载,并为更大的芯片设计简化了布局。每个核心在2GHz下提供高达16个TMAC/s(>32个TOPS),多核和多芯片实现能够提供高达50+TMAC/s(>100个INT8 TOPS)–适用于多摄像头或异构传感器丰富的应用。核心是为AEC-Q100扩展温度操作而设计的,包含的功能使用户能够获得ASIL-B及以上认证。
IP核的性能可扩展到每个芯片超过50 TMAC/s(>100个TOPS)和低延迟持续推理是其低级微体系结构的结果。采用专利的地面设计,用于高度确定性的数据流管理,具有高度并行的以内存为中心的架构,比其硬件NN加速器的片上内存带宽高达100倍,确保使用大输入(如多个高清摄像机)的复杂DNN的持续效率高达95%。
aiWare SDK支持Khronos的NNEF以及开放标准的ONNX输入,直接编译二进制文件,无需对DSP或MCU进行低级编程。包括用于FP32到INT8量化的自动化工具,几乎没有或几乎没有精度损失,以及不断增长的复杂DNN性能分析工具组合。后者旨在帮助软件和人工智能工程师将在实验室中训练的nn迁移和转换为在aiWare驱动的生产汽车硬件平台上执行的高效实时解决方案。
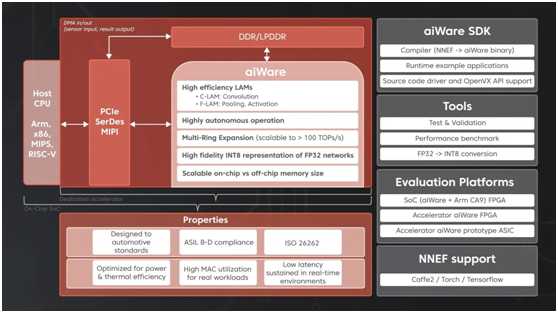
汽车AI加速器的构建块,包括aiWare硬件IP。
AImotive硬件工程高级副总裁Marton Feher说:“产品级aiWare3P发布版汇集了所知道的关于为基于视觉的汽车人工智能推理应用加速神经网络的所有知识。现在拥有汽车行业最高效、最具吸引力的NN加速解决方案之一,用于量产L2/L2+/L3 AI。”
aiWare3P硬件IP正被部署在一系列L2/L2+生产解决方案中,并且被用于更高级的异构传感器应用的研究。客户包括Nextchip公司即将推出的Apache5图像边缘处理器,以及OnSemiconductor公司与AImotive公司的合作项目,以展示先进的异构传感器融合能力。
AImotive表示,将在2020年第1季度发布基于aiWare3P IP核心的公开基准结果的完整更新。这是其承诺的一部分,即开放基准测试,使用良好控制的基准,反映真实应用,如摄像头的高分辨率输入,而不是使用224×224输入的不切实际的公共基准。
不需要主机CPU干预
aiWare3P硬件IP的新特性包括支持更大的预先优化的嵌入式激活和池功能组合,确保大多数nn在aiWare3P核心内执行,而无需任何主机CPU干预;实时数据压缩,降低外部内存带宽要求-尤其是对于较大的输入大小和更深的网络;以及在C-LAM卷积引擎和F-LAM函数引擎之间的高级交叉耦合,以提高重叠和交错执行效率。
基于物理块的微体系结构通过最小化任何进程节点上的困难时间限制,使大型aiWare核心的物理实现更加容易;基于逻辑块的数据管理实现了高效的工作负载可扩展性,每个内核最高16 TMAC/s,无需缓存,NOC或其复杂的基于多核处理器的方法会产生瓶颈、降低确定性并消耗更多的功率和硅面积aiWare3P RTL将从2020年1月起向所有客户发货,升级后的SDK包括改进的编译器和新的性能分析工具,用于离线估计和实时细粒度目标硬件分析。
标签:图像 精度 系统 rto lazy 表示 基准测试 限制 人工智
原文地址:https://www.cnblogs.com/wujianming-110117/p/13275448.html