标签:回调 return lan ted 操作 统计 大量 end rev
最近也是快要被折磨死, 都上线了还在不断要改需求和调整, 数据量猛增, 一周几百万的增量, 着实有点超过预期, 这个体量. 刚上线就要面临 SQL 优化, 通常的方案是, 基于宽表, 再加工一层汇总表, 然而, 有些指标, 就必须从几百万的明细表中出, 尤其那种带时间筛选的, 这个, 我真的是一点办法也没有...
一个BI项目的数据处理流程, 我是这样做的, 如下图.
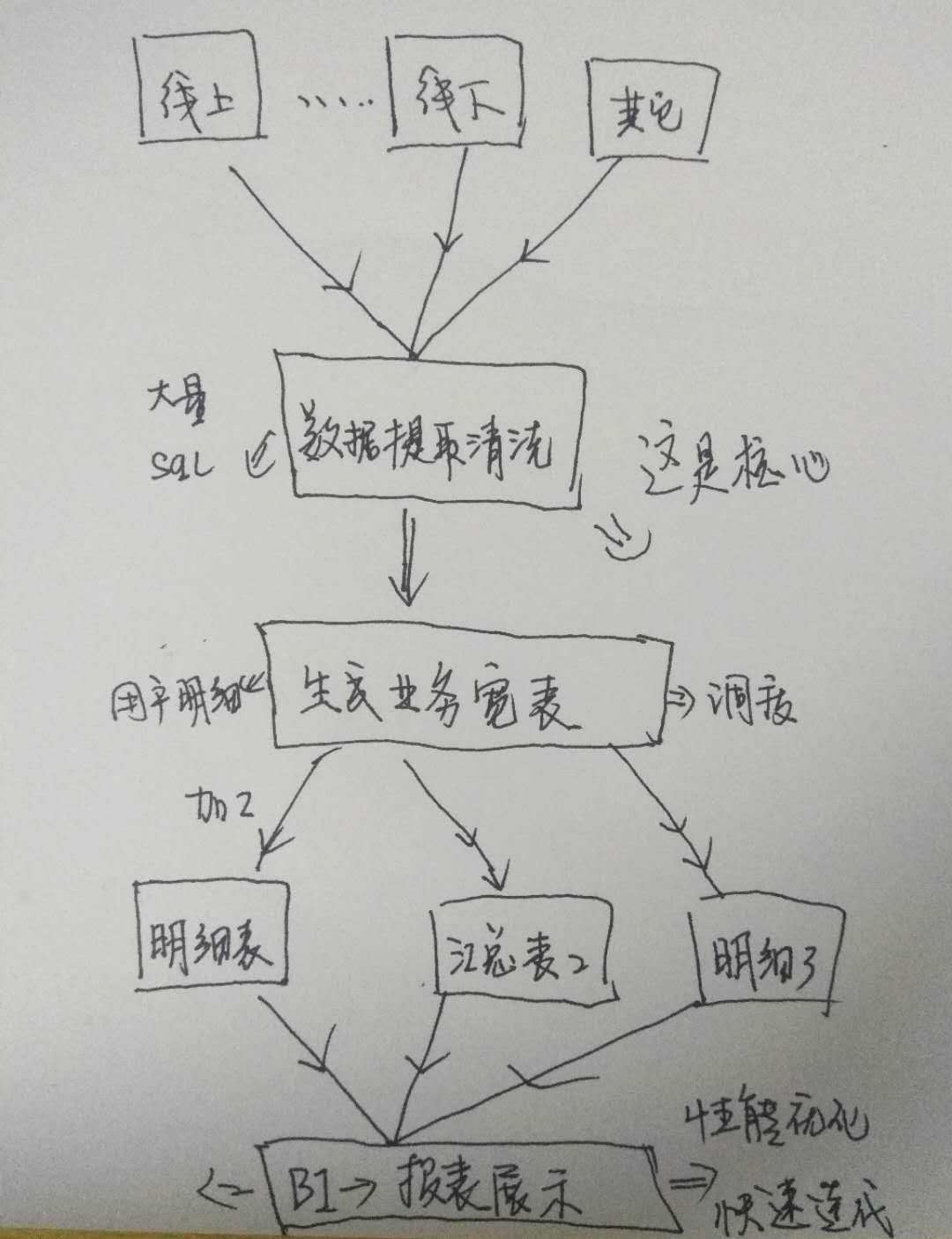
我整个过程都做, 最有价值的, 其实生成业务宽表的那个过程, 会写大量的 SQL, 同时也是其数据价值最为有用的地方呀, 其次就是报表展示, 直接面向用户的, 对性能是有要求的, 数据量一般都几百万, 上千万, 直接查询这么大的表, 铁定不行, 只能是基于宽表再做一层汇总, 即按业务要关注的维度, group by 来一层, 这样就变为小数据集了. 然而, 当前我的一个指标, 真实想来想去, 没有规律, 就只能查明细.. 这根本就没法优化, 还是有点难度, 我个人觉得数据这块.
定义一个函数或者方法, 它的一个或多个参数是可选的并且有一个默认值.
通过给参数指定一个默认值即可.
def spam(a, b=666):
print(a, b)
# test
spam(1)
spam(1, 2)
1 666
1 2
如果默认参数是一个可修改的容器, 如列表, 字段, 集合等, 可以用 None 作为默认值.
# Using a list as default value
def spam(a, b=None):
if b is None:
b = []
print(a, b)
如果只是测试一下默认参数是否有传递进来, 而不提供默认值的话, 可以这样写:
_no_value = object()
def spam(a, b= _no_value):
if b is _no_value:
print(‘No b value supplied.‘)
# test
spam(1)
spam(1, 2) # b = 2
spam(1, None) # b = None
No b value supplied.
可以发现, None 和 ‘没有值‘ 是不同的概念, None, 也是基类 object 的实例对象.
虽然看上去, 这默认值参数非常容易理解, 平时也经常会使用, 但仔细去看一下的, 会发现里面仍有很多特性在里面.
x = 666
def spam(a, b=x):
print(a, b)
spam(1)
x = 999
spam(1)
1 666
1 666
我个人理解是跟作用域有关哦. 如上, 函数在定义的时候, b = x 这里就已经找到了它的默认值 666. 后面再对 x 进行修改或者指向其他值, 都不会影响 b, 类似 b = x 这里, 第一次 b 就已经对 x 当时指向的对象进行了深拷贝了.
另外, 默认参数的值应该是 不可变对象, 比如 None, True, False, 数字, 字符串. 尤其不要这些写哦:
def spam(a, b=[]):
pass
这些的操作会影响到下次调用该函数时的默认值, 于是就出现 ‘莫名的 bug‘ , 很难去发现了.
def spam(a, b=[]):
print(b)
return b
x = spam(1)
print(x)
x.append(666)
x.append(‘youge‘)
print(x)
spam(1) # Modified list gets returned!
[]
[]
[666, ‘youge‘]
[666, ‘youge‘]
[666, ‘youge‘]
这样就全乱了. 因此, 最好将默认值设为不可变类型的, 比如 None 呀, 补一点, 在测试 None 值时使用 is 是非常关键的. 通常, 包括我自己也喜欢这样错误地写.
def spam(a, b=None):
if not b:
b = []
print(‘b is None‘)
在 Python 中, 对于 False 是: None, 0, ‘ ‘, [ ], { }, ( ) 等都是. 如果这样写就会将一些输入给判错了.
spam(1, 0)
spam(1, ‘‘)
spam(1, False)
spam(1, [])
spam(1, {})
b is None
b is None
b is None
b is None
b is None
对于参数校验, 我最为常用还是 isinstance(obj, type)
def spam(a, b, c):
if not isinstance(a, int):
print(‘a not int‘)
return
if not isinstance(b, str):
print(‘b not str‘)
returnn
print(a, b, c)
为 sort( ) 操作创建一个很短的回调函数, 但又不想通过 def 去写一段, 而想通过内连的方式来创建一个函数.
通过 lambda 表达式来创建匿名函数即可.
add = lambda x, y: x + y
print(add(1, 1))
print(add(‘hello‘, ‘youge!‘))
2
helloyouge!
# 等价于
def add(x, y):
return x + y
lambda 在一些排序的场景也比较常用, 如:
names = [
‘David ben‘, ‘Bruce‘, ‘Jordan‘,
‘Hello‘, ‘You Ge‘, ‘Jane‘
]
sorted(names, key=lambda name: name.split()[-1].lower())
[‘David ben‘, ‘Bruce‘, ‘You Ge‘, ‘Hello‘, ‘Jane‘, ‘Jordan‘]
更加经典的应该是, 字典按值排序了, 我见过很多回了, 先让你做词频统计, 然后再按值排序输出.
# 字典按值排序
my_str = "eaaabbccccddderrfc"
d = {}
for s in my_str:
if d.get(s):
d[s] += 1
else:
d[s] = 1
# 按值降序排列
sorted(d.items(), key=lambda arr: arr[1], reverse=True)
[(‘c‘, 5), (‘a‘, 3), (‘d‘, 3), (‘e‘, 2), (‘b‘, 2), (‘r‘, 2), (‘f‘, 1)]
就到这吧, 真的是学而时习之呀, 虽然这些东西我早已熟知, 但记忆最好的方法, 其实就是重复和强化.
标签:回调 return lan ted 操作 统计 大量 end rev
原文地址:https://www.cnblogs.com/chenjieyouge/p/13286199.html