标签:优化 png 密码 eric start encode 开始 ima oat
? 用来创建一个生成一系列整数的可迭代对象(也叫整数序列生成器)
? range(stop) 从零开始,每次生成一个整数后加1操作,直到stop为止(不包含stop)
? range(start, stop[,step]) 从start开始,每次生成一个整数后移动step,直到stop为止(不包含stop,且step可以为负整数
? Python程序是由代码块构造的,块是一个python程序的文本,它是作为一个单元执行的;所有代码都必须依赖代码块执行。
? 一个模块,一个函数,一个类,一个文件等都是一个代码块。
? 而作为交互方式输入的每个命令都是一个代码块。(交互方式:命令行模式的Python解释器)。
? 在同一个代码块使用一个缓存机制
? Python在执行同一个代码块的初始化对象的命令时,会检查是否其值是否已经存在,如果存在,会将其重用。换句话说:执行同一个代码块时,遇到初始化对象的命令时,他会将初始化的这个变量与值存储在一个字典中,在遇到新的变量时,会先在字典中查询记录,如果有同样的记录那么它会重复使用这个字典中的之前的这个值。所以在你给出的例子中,文件执行时(同一个代码块)会把i1、i2个变量指向同一个对象;
满足缓存机制则他们在内存中只存在一个,即:id相同
适用对象:int( float),str,bool不可变类型
? 提升性能,节省内容
? 不在同一代码块使用另一个缓存机制
? Python自动-5~256的整数进行了缓存,当你将这些整数赋值给变量时,并不会重新创建对象,而是使用创建好的缓存对象。
? python会将一定规则的字符串在字符串驻留池中,创建一份,当你将这些字符串赋值给变量时,并不会重新创建对象,而是使用在字符串驻留池中创建好的对象。
? 其实,无论是缓存还是字符串驻留池,都是 python做的一个优化,就是将~5-256的整数和一定规则的字符串,放在一个池(容器,或者字典)中,无论程序中那些变量指向这些范围内的整数或者字符串,那么他直接在这个“池’中引用,言外之意,就是内存中只创建一个。
? int( float),str,bool
? list.copy()
? 会在内存中新开辟一个空间,存放这个copy的列表,但是列表里的内容还是沿用之前对象的内存地址,所以i1,i2的id不同,但是列表里面内容id相同。
? 切片属于浅copy
? list1 = [1,2,3,[22,33]]
? list2 = list1[:]
? list.deepcopy()
? 会在内存中开辟新空间,将原列表以及可变的数据类型在内存中重新创建一份,而不可变的数据类型则沿用之前的。
? 浅copy:嵌套的可变的数据类型是同一个
? 深copy:嵌套的可变的数据类型不是同一个
? 用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标
? enumerate(sequence, [start=0])
? sequence -- 一个序列、迭代器或其他支持迭代对象。
? start -- 下标起始位置。
? 返回 enumerate(枚举) 对象。
? 计算机起初使用的密码本是:ASCII码(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统ASCII码中只包含英文字母,数字以及特殊字符与二进制的对应关系,主要用于显示现代英语和其他西欧语言,其最多只能用 8 位来表示(一个字节),即:2**8 = 256,所以,ASCII码最多只能表示 256 个符号。
? 包含英文字母,数字,特殊字符与01010101对应关系。
? 只包含本国文字(以及英文字母,数字,特殊字符)与0101010对应关系。GBK是采用单双字节变长编码,英文使用单字节编码,完全兼容ASCII字符编码,中文部分采用双字节编码。
? 包含全世界所有的文字与二进制0101001的对应关系。通用字符集(Universal Character Set, UCS)是由ISO制定的ISO 10646(或称ISO/IEC 10646)标准所定义的标准字符集。UCS-2用两个字节编码,UCS-4用4个字节编码。
? 是一种针对Unicode的可变长度字符编码,又称万国码,包含全世界所有的文字与二进制0101001的对应关系(最少用8位一个字节表示一个字符)。
UTF-8 :最少用8位数,去表示一个字符.
英文: 8位,1个字节表示.
欧洲文字: 16位,两个字节表示一个字符.
中文,亚洲文字: 24位,三个字节表示.
? 在计算机内存中,必须使用Unicode编码(除了bytes),将数据保存到硬盘或者需要网络传输的时候,就需要转换为非Unicode编码(bytes类型可以直接发送)比如:UTF-8编码。
? 例如:用文件编辑器(word,等)编辑文件的时候,从文件将你的数据(此时你的数据是非Unicode(可能是UTF-8、gbk等,这个编码取决于你的编辑器设置))字符被转换为Unicode字符读到内存里,进行相应的编辑,编辑完成后,保存的时候再把Unicode转换为非Unicode(UTF-8,GBK 等)保存到文件。
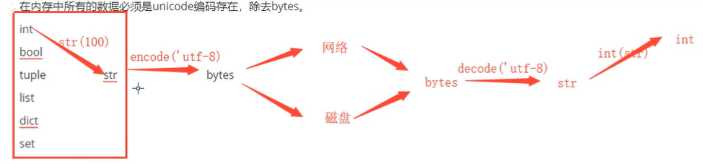
? 不同编码之间,不能直接互相识别
英文
str为例 : content : ’hello’
内存中编码方式:Unicode
表现形式:’hello’
bytes :
内存中编码方式:非Unicode
表现形式:b”hello”
中文
str为例 : content : ’中国’
内存中编码方式:Unicode
表现形式:’中国’
bytes :
内存中编码方式:非Unicode (utf-8)
表现形式:b‘\xe4\xb8\xad\xe5\x9b\xbd‘
str(文字文本) --> bytes(字节文本) :encode
? 称作编码 : 将 str 转化成 bytes类型
s1 = ‘中国‘
b1 = s1.encode(‘utf-8‘) # 转化成utf-8的bytes类型
print(s1) # 中国
print(b1) # b‘\xe4\xb8\xad\xe5\x9b\xbd‘
s1 = ‘中国‘
b1 = s1.encode(‘gbk‘) # 转化成gbk的bytes类型
print(s1) # 中国
print(b1) # b‘\xd6\xd0\xb9\xfa‘
bytes --> str :decode
? 称作解码, 将 bytes 转化成 str类型
b1 = b‘\xe4\xb8\xad\xe5\x9b\xbd‘
s1 = b1.decode(‘utf-8‘)
print(s1) # 中国
gbk --> utf-8
先转换成Unicode,再转化成utf-8
gbk --decode(’gbk’)--> unicode --encode(’utf-8’)-->utf-8
在 python 中,类型属于对象,变量是没有类型的:a=[1,2,3],a="Runoob",[1,2,3] 是 List 类型,"Runoob" 是 String 类型,而变量 a 是没有类型,她仅仅是一个对象的引用(一个指针),可以是指向 List 类型对象,也可以是指向 String 类型对象。
? str, tuples,int 是不可更改的对象,而 list,dict 等则是可以修改的对象。
? 不可变类型:变量赋值 a=5 后再赋值 a=10,这里实际是新生成一个 int 值对象 10,再让 a 指向它,而 5 被丢弃,不是改变a的值,相当于新生成了a。
? 可变类型:变量赋值 la=[1,2,3,4] 后再赋值 la[2]=5 则是将 list la 的第三个元素值更改,本身la没有动,只是其内部的一部分值被修改了。
标签:优化 png 密码 eric start encode 开始 ima oat
原文地址:https://www.cnblogs.com/q121211z/p/13344134.html