标签:开启 apr zlib 任务 offset org foo overwrite visio
hive (default)>set hive.exec.compress.output=true;
hive (default)>set mapreduce.output.fileoutputformat.compress=true;
hive (default)> set mapreduce.output.fileoutputformat.compress.codec = org.apache.hadoop.io.compress.SnappyCodec;
hive (default)> set mapreduce.output.fileoutputformat.compress.type=BLOCK;
hive (default)> insert overwrite local directory ‘/opt/module/datas/distribute-result‘ select * from emp distribute by deptno sort by empno desc;
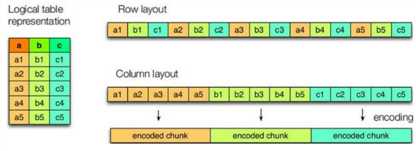

create table log_text ( track_time string, url string, session_id string, referer string, ip string, end_user_id string, city_id string ) row format delimited fields terminated by ‘\t‘ stored as textfile ;
hive (default)> load data local inpath ‘/opt/module/datas/log.data‘ into table log_text ;
hive (default)> dfs -du -h /user/hive/warehouse/log_text;
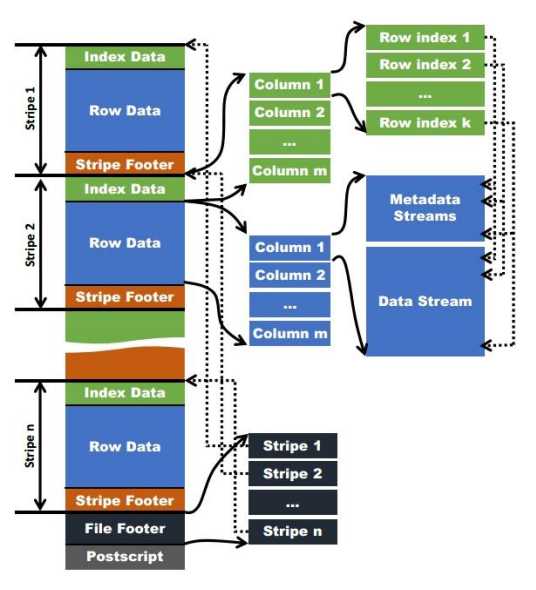
create table log_orc( track_time string, url string, session_id string, referer string, ip string, end_user_id string, city_id string ) row format delimited fields terminated by ‘\t‘ stored as orc ;
hive (default)> insert into table log_orc select * from log_text ;
hive (default)> dfs -du -h /user/hive/warehouse/log_orc/ ;
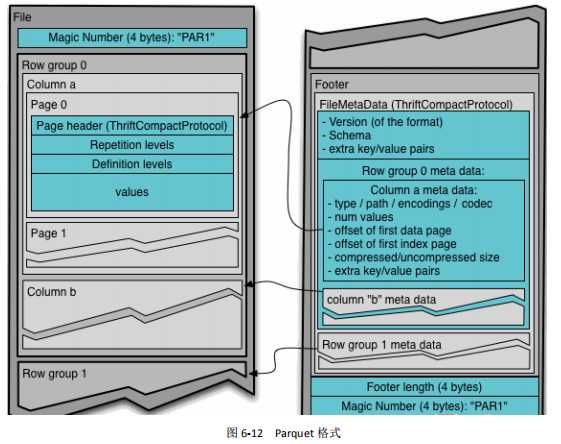
create table log_parquet( track_time string, url string, session_id string, referer string, ip string, end_user_id string, city_id string ) row format delimited fields terminated by ‘\t‘ stored as parquet ;
hive (default)> insert into table log_parquet select * from log_text ;
hive (default)> dfs -du -h /user/hive/warehouse/log_parquet/ ;
hive (default)> select count(*) from log_text; _c0 100000 Time taken: 21.54 seconds, Fetched: 1 row(s) Time taken: 21.08 seconds, Fetched: 1 row(s) Time taken: 19.298 seconds, Fetched: 1 row(s)
hive (default)> select count(*) from log_orc; _c0 100000 Time taken: 20.867 seconds, Fetched: 1 row(s) Time taken: 22.667 seconds, Fetched: 1 row(s) Time taken: 18.36 seconds, Fetched: 1 row(s)
hive (default)> select count(*) from log_parquet; _c0 100000 Time taken: 22.922 seconds, Fetched: 1 row(s) Time taken: 21.074 seconds, Fetched: 1 row(s) Time taken: 18.384 seconds, Fetched: 1 row(s)
[atguigu@hadoop104 hadoop-2.7.2]$ hadoop checknative [-a|-h] check native hadoop and compression libraries availability
[atguigu@hadoop104 hadoop-2.7.2]$ hadoop checknative 17/12/24 20:32:52 WARN bzip2.Bzip2Factory: Failed to load/initialize native-bzip2 library system-native, will use pure-Java version 17/12/24 20:32:52 INFO zlib.ZlibFactory: Successfully loaded & initialized native-zlib library Native library checking: hadoop: true /opt/module/hadoop-2.7.2/lib/native/libhadoop.so zlib: true /lib64/libz.so.1 snappy: false lz4: true revision:99 bzip2: false
[atguigu@hadoop102 software]$ tar -zxvf hadoop-2.7.2.tar.gz
[atguigu@hadoop102 native]$ pwd /opt/software/hadoop-2.7.2/lib/native [atguigu@hadoop102 native]$ ll
-rw-r--r--. 1 atguigu atguigu 472950 9 月 1 10:19 libsnappy.a -rwxr-xr-x. 1 atguigu atguigu 955 9 月 1 10:19 libsnappy.la lrwxrwxrwx. 1 atguigu atguigu 18 12 月 24 20:39 libsnappy.so -> libsnappy.so.1.3.0 lrwxrwxrwx. 1 atguigu atguigu 18 12 月 24 20:39 libsnappy.so.1 -> libsnappy.so.1.3.0 -rwxr-xr-x. 1 atguigu atguigu 228177 9 月 1 10:19 libsnappy.so.1.3.0
[atguigu@hadoop102 native]$ cp ../native/* /opt/module/hadoop-2.7.2/lib/native/
[atguigu@hadoop102 lib]$ xsync native/
[atguigu@hadoop102 hadoop-2.7.2]$ hadoop checknative 17/12/24 20:45:02 WARN bzip2.Bzip2Factory: Failed to load/initialize native-bzip2 library system-native, will use pure-Java version 17/12/24 20:45:02 INFO zlib.ZlibFactory: Successfully loaded & initialized native-zlib library Native library checking: hadoop: true /opt/module/hadoop-2.7.2/lib/native/libhadoop.so zlib: true /lib64/libz.so.1 snappy: true /opt/module/hadoop-2.7.2/lib/native/libsnappy.so.1 lz4: true revision:99 bzip2: false
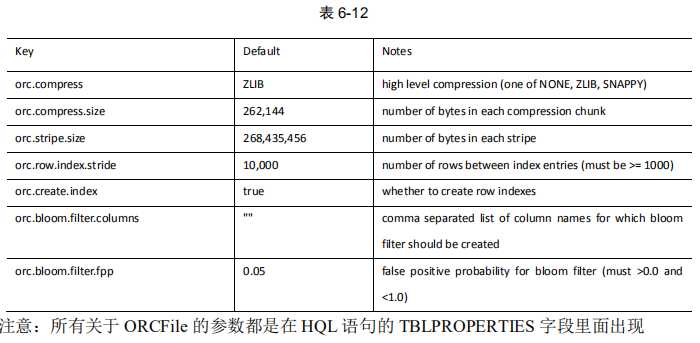
create table log_orc_none( track_time string, url string, session_id string, referer string, ip string, end_user_id string, city_id string ) row format delimited fields terminated by ‘\t‘ stored as orc tblproperties ("orc.compress"="NONE");
hive (default)> insert into table log_orc_none select * from log_text ;
hive (default)> dfs -du -h /user/hive/warehouse/log_orc_none/ ;
create table log_orc_snappy( track_time string, url string, session_id string, referer string, ip string, end_user_id string, city_id string ) row format delimited fields terminated by ‘\t‘ stored as orc tblproperties ("orc.compress"="SNAPPY");
hive (default)> insert into table log_orc_snappy select * from log_text ;
hive (default)> dfs -du -h /user/hive/warehouse/log_orc_snappy/ ;
标签:开启 apr zlib 任务 offset org foo overwrite visio
原文地址:https://www.cnblogs.com/qiu-hua/p/13368443.html