标签:known cto 日志 类型 失效 table listen 文件的 取消
Redis的哨兵机制存在的意义就是当主从架构中,master发生宕机,无需人工干预,自动实现故障转移。Redis的Sentinel系统用于管理多个Redis示例,该系统执行以下三个任务:
- 监控(Monitoring): Sentinel 会不断地检查你的master和slave是否运作正常。
- 提醒(Notification): 当被监控的某个 Redis 服务器出现问题时, Sentinel 可以通过 API 向管理员或者其他应用程序发送通知。
- 自动故障迁移(Automatic failover): 当一个主服务器不能正常工作时, Sentinel 会开始一次自动故障迁移操作, 它会将失效master的其中一个slave升级为新的master,并让失效master的其他slave改为复制新的master;当客户端试图连接失效的master时,集群也会向客户端返回新master的地址, 使得集群可以使用新master代替失效服务器。
环境如下
| hostname | IP | server |
|---|---|---|
| redis1 | 192.168.171.150 | Redis(master) |
| redis2 | 192.168.171.151 | Redis(slave) |
| redis3 | 192.168.171.152 | Redis(slave) |
注:需要保证各个节点的redis服务正常运行,关于部署redis可以参考博文:Redis 5.0部署
配置主从复制
在两台slave节点上执行以下命令,指定主机redis01为master
127.0.0.1:6379> slaveof 192.168.171.151 6379在redis01主机上查看连接的slave
127.0.0.1:6379> info replication # 执行此指令,查看复制信息
# Replication
role:master
connected_slaves:2
# 以下是连接的slave信息
slave0:ip=192.168.171.152,port=6379,state=online,offset=70,lag=1
slave1:ip=192.168.171.153,port=6379,state=online,offset=70,lag=0
.............................验证主从复制
# redis01节点:
127.0.0.1:6379> set test slave_copy
OK
# 其他节点确定新建的数据已同步
127.0.0.1:6379> get test
"slave_copy"至此,主从复制完成。
若要了解主从复制更多原理,可以参考博文:redis主从复制详解
配置Sentinel节点
以下操作在其中一个节点进行即可(我这里在redis01节点上)。
[root@redis1 conf]# pwd
/usr/local/redis/conf
# 拷贝一份sentinel的配置文件到当前目录
[root@redis1 conf]# cp ~/redis-5.0.5/sentinel.conf .
# 修改后的配置文件如下:
[root@redis1 conf]# egrep -v ‘^$|^#‘ sentinel.conf
bind 0.0.0.0 # 监听地址
port 26379 #监听端口
daemonize yes # 开启守护进程
pidfile /var/run/redis-sentinel.pid # 指定pid文件
logfile "/usr/local/redis/data/sentinel.log" # 指定日志文件
dir /tmp # 指定工作目录
# 下面的配置稍后解释
sentinel monitor mymaster 192.168.171.151 6379 2
sentinel down-after-milliseconds mymaster 60000
sentinel parallel-syncs mymaster 1
sentinel failover-timeout mymaster 180000
sentinel deny-scripts-reconfig yes
# 发送修改后的配置文件到其他redis节点
[root@redis1 conf]# for i in 152 153;do scp sentinel.conf root@192.168.171.${i}:/usr/local/redis/conf/;done其他参数解释
sentinel monitor mymaster 192.168.171.151 6379 2:
上面这行配置是指示sentinel去监视一个名为mymaster(这个名称自定义)的主服务器,这个master的IP地址为192.168.171.151,端口号为6379,而将这个master判断为失效至少需要2个sentinel同意(只要同意sentinel的数量不达标,自动故障迁移就不会执行。这个数值的由来:sentinel节点的总数 / 2 + 1,也就是sentinel节点的半数以上是最好的)。
sentinel down-after-milliseconds mymaster 60000
上面的配置意思为:如果mymaster这个主节点在指定的60000毫秒内,没有返回sentinel发送的ping命令的回复,或者返回一个错误,那么sentinel将这个服务器标记为主观下线。
不过只有一个 Sentinel 将服务器标记为主观下线并不一定会引起服务器的自动故障迁移: 只有在足够数量的 Sentinel都将一个服务器标记为主观下线之后,服务器才会被标记为客观下线,这时自动故障迁移才会执行。将服务器标记为客观下线所需的 Sentinel 数量由对主服务器的配置决定。
sentinel parallel-syncs mymaster 1
指定了在执行故障转移时, 最多可以有多少个从服务器同时对新的主服务器进行同步, 这个数字越小, 完成故障转移所需的时间就越长。但是避免了故障转移后,多个slave都去同步新的master发生的阻塞,可以根据实际情况来设置这个值,比如上面设置值为1,则表示发生故障转移后,一次只能有一个slave去同步新master的数据,这样可以避免阻塞。
sentinel failover-timeout mymaster 180000
sentinel failover-timeout Sentinel failover-timeout failover-timeout通常被解释成故障转移超时时间,但实际上它作用于故障转移的各个阶段:
failover-timeout的作用具体体现在四个方面:
- 如果Redis Sentinel对一个主节点故障转移失败,那么下次再对该主节点做故障转移的起始时间是failover-timeout的2倍。
- 在b)阶段时,如果Sentinel节点向a)阶段选出来的从节点执行slaveof no one一直失败(例如该从节点此时出现故障),当此过程超过failover-timeout时,则故障转移失败。
- 在b)阶段如果执行成功,Sentinel节点还会执行info命令来确认a)阶段选出来的节点确实晋升为主节点,如果此过程执行时间超过failover-timeout时,则故障转移失败。
- 如果c)阶段执行时间超过了failover-timeout(不包含复制时间),则故障转移失败。注意即使超过了这个时间,Sentinel节点也会最终配置从节点去同步最新的主节点。
sentinel auth-pass
如果Sentinel监控的主节点配置了密码, sentinel authpass配置通过添加主节点的密码,防止Sentinel节点对主节点无法监控。
启动sentinel
以下操作需要在所有节点执行。
[root@redis1 conf]# pwd # 确定当前路径
/usr/local/redis/conf
[root@redis1 conf]# redis-sentinel sentinel.conf # 启动sentinel,sentinel.conf为哨兵机制的配置文件名
[root@redis1 conf]# ss -anput | grep 26379 # 哨兵的监听端口为26379
tcp LISTEN 0 511 *:26379 *:* users:(("redis-sentinel",pid=40904,fd=6))查看sentinel启动后配置文件的变化
[root@redis1 conf]# egrep -v ‘^$|^#‘ sentinel.conf
bind 0.0.0.0
port 26379
daemonize yes
pidfile "/var/run/redis-sentinel.pid"
logfile "/usr/local/redis/data/sentinel.log"
dir "/tmp"
sentinel myid 10d5c185e309cd1fd2540b8fe2b3a07748b72eef
sentinel deny-scripts-reconfig yes
sentinel monitor mymaster 192.168.171.151 6379 2
sentinel down-after-milliseconds mymaster 60000
sentinel config-epoch mymaster 0
protected-mode no
sentinel leader-epoch mymaster 0
# 可以发现它已经通过master的info信息,采集到了其他两个slave节点的信息
sentinel known-replica mymaster 192.168.171.153 6379
sentinel known-replica mymaster 192.168.171.152 6379
sentinel known-sentinel mymaster 192.168.171.152 26379 f446083dcdbf99a9253efcc2a5197094e9d75d35
sentinel known-sentinel mymaster 192.168.171.153 26379 fafa402e43edf1ea5b8aebaf5685c07e5194246f
sentinel current-epoch 0验证故障转移效果
当我此时手动将当前的master进行shutdown关闭后,sentinel的日志显示如下(任意一个sentinel节点的日志即可):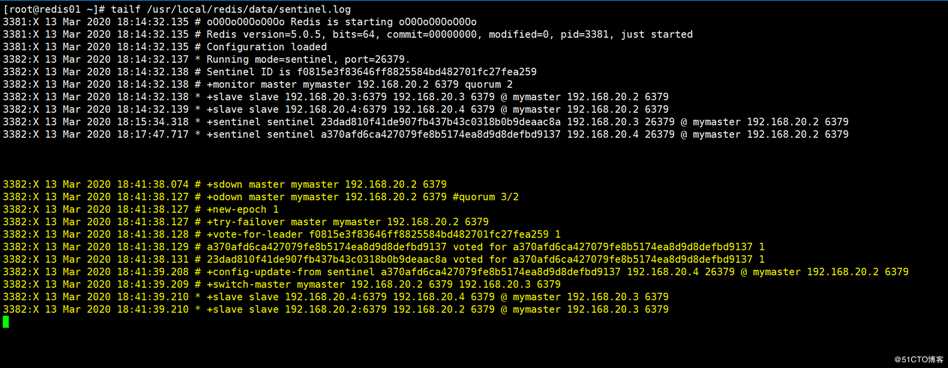
上面标注的信息,就是一次故障转移产生的日志,可以看到之前的slave节点192.168.171.152成为了新主,此时可以去redis2和redis3主机上查看确认当前的主.
# 主机redis2
127.0.0.1:6379> info replication
# Replication
role:master # redis02当前为master
connected_slaves:1
slave0:ip=192.168.171.153,port=6379,state=online,offset=98179,lag=0
# 主机redis3
127.0.0.1:6379> info replication
# Replication
role:slave
master_host:192.168.171.152 # 当前主为redis02的地址
master_port:6379
master_link_status:up重新启动redis1实例
[root@redis1 ~]# redis-server /usr/local/redis/conf/redis.conf
[root@redis1 ~]# redis-cli # 登录到数据库
127.0.0.1:6379> info replication # 查看复制信息
# Replication
role:slave
master_host:192.168.171.152 # 可以发现自动指向redis02节点作为了master
master_port:6379
master_link_status:up这就是完整的故障转移效果
sentinel维护命令
Sentinel节点是一个特殊的Redis节点,它有自己专属的API,下面将分别展示。
登录到哨兵监听的26379端口
[root@redis1 ~]# redis-cli -p 26379 # 使用redis-cli指令即可登录
127.0.0.1:26379> sentinel master mymaster # 查看mymaster的主节点状态以及相关的统计信息
返回结果如下: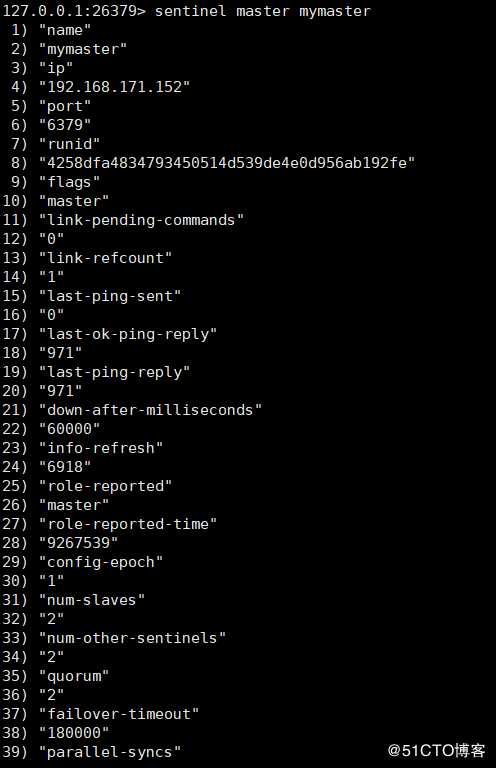
其他相关指令:
127.0.0.1:26379> sentinel slaves mymaster # 查看指定的从节点状态及相关统计信息
127.0.0.1:26379> sentinel get-master-addr-by-name mymaster # 返回主节点的IP和端口
127.0.0.1:26379> sentinel failover mymaster # 对指定进行强制故障转移(他会将master角色自动转移到当前任意一个slave,没有和其他sentinel节点协商),当故障转移完成之后,其他的sentinel节点按照故障转移的结果更新自身配置。
127.0.0.1:26379> sentinel ckquorum mymaster # 检测当前主节点的哨兵是否到达quorum的个数。
127.0.0.1:26379> sentinel flushconfig # 将sentinel节点的配置信息强制写道磁盘上
127.0.0.1:26379> sentinel remove mymaster # 取消当前sentinel节点对于指定主节点的监控redis哨兵机制中的其他概念
主观下线和客观下线
Redis的Sentinel中关于下线(down)有两个不同的概念:
服务器对 PING 命令的有效回复可以是以下三种回复的其中一种:
- 返回 +PONG 。
- 返回 -LOADING 错误。
- 返回 -MASTERDOWN 错误。
如果服务器返回除以上三种回复之外的其他回复,又或者在指定时间内没有回复 PING 命令, 那么Sentinel认为服务器返回的回复无效(non-valid)。
注意,一个服务器必须在 master-down-after-milliseconds 毫秒内,一直返回无效回复才会被 Sentinel 标记为主观下线。
举个例子, 如果 master-down-after-milliseconds 选项的值为 30000 毫秒(30 秒),那么只要服务器能在每29秒之内返回至少一次有效回复,这个服务器就仍然会被认为是处于正常状态的。
从主观下线状态切换到客观下线状态并没有使用严格的法定人数算法(strong quorum algorithm), 而是使用了流言协议:如果 Sentinel 在给定的时间范围内, 从其他 Sentinel 那里接收到了足够数量的主服务器下线报告, 那么 Sentinel就会将主服务器的状态从主观下线改变为客观下线。如果之后其他 Sentinel 不再报告主服务器已下线,那么客观下线状态就会被移除。
客观下线条件只适用于主服务器: 对于任何其他类型的 Redis 实例, Sentinel 在将它们判断为下线前不需要进行协商, 所以从服务器或者其他 Sentinel 永远不会达到客观下线条件。
只要一个Sentinel发现某个主服务器进入了客观下线状态, 这个Sentinel就可能会被其他 Sentinel 推选出,并对失效的主服务器执行自动故障迁移操作。
每个 Sentinel 都需要定期执行的任务
- 每个Sentinel以每秒钟一次的频率向它所知的主服务器、从服务器以及其他Sentinel实例发送一个PING命令。
- 如果一个实例(instance)距离最后一次有效回复 PING 命令的时间超过 down-after-milliseconds 选项所指定的值, 那么这个实例会被Sentinel 标记为主观下线。 一个有效回复可以是: +PONG 、 -LOADING 或者-MASTERDOWN 。
- 如果一个主服务器被标记为主观下线, 那么正在监视这个主服务器的所有 Sentinel要以每秒一次的频率确认主服务器的确进入了主观下线状态。
- 如果一个主服务器被标记为主观下线, 并且有足够数量的 Sentinel (至少要达到配置文件指定的数量)在指定的时间范围内同意这一判断,那么这个主服务器被标记为客观下线。
- 在一般情况下,每个Sentinel会以每 10 秒一次的频率向它已知的所有主服务器和从服务器发送INFO命令。 当一个主服务器被Sentinel标记为客观下线时,Sentinel向下线主服务器的所有从服务器发送INFO命令的频率会从10秒一次改为每秒一次。
- 当没有足够数量的Sentinel同意主服务器已经下线,主服务器的客观下线状态就会被移除。当主服务器重新向 entinel的PING命令返回有效回复时,主服务器的主观下线状态就会被移除。
其他可参考官方文档
标签:known cto 日志 类型 失效 table listen 文件的 取消
原文地址:https://blog.51cto.com/14227204/2513515