标签:显示 bsp 通过 csharp export incr 内存 算法 mic
本讲主要内容
为什么基础监控第一项是CPU
1)CPU是处理所有任务的核心
2)另外 Linux 由于CPU存在各种 状态类型CPU时间 所以 很多情况下 ?部分的出现问题的情况 都可以 反应在CPU的表现上
下?举?个 在企业中对CPU使?率监控的实例
数据采集: Node_exporter
使用公式
(1-sum(increase(node_cpu{mode="idle"}[1m])) by(instance) / sum(increase(node_cpu[1m])) by(instance))*100
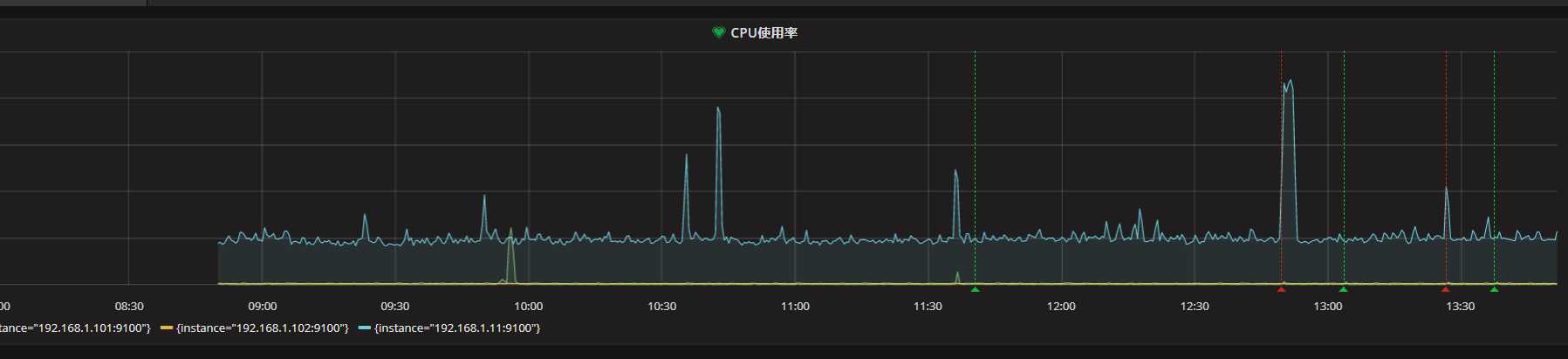
第?幅图 就是咱们之前 讲过的,计算CPU综合使?率 这?就 不再重复它的计算?法了
在?产环境中 ?般70-80%以上的CPU? 是因为 ?户态user CPU?所导致
我们使?Top命令随便查看?台服务器的时候 ?般也会看到 user%会最?

?户态的CPU使?率 是跟应?程序(或者说软件)的运?密 切相关的
?户态的CPU使?率 是跟应?程序(或者说软件)的运?密 切相关的
不过我们 在做监控的时候 ?般倒是不? 单独列出?个 user% 态的CPU使?率图 因为 除去IO等待造成的CPU?之外,?部 分情况 就是 user%造成
下图是io等待CPU利用率的监控图
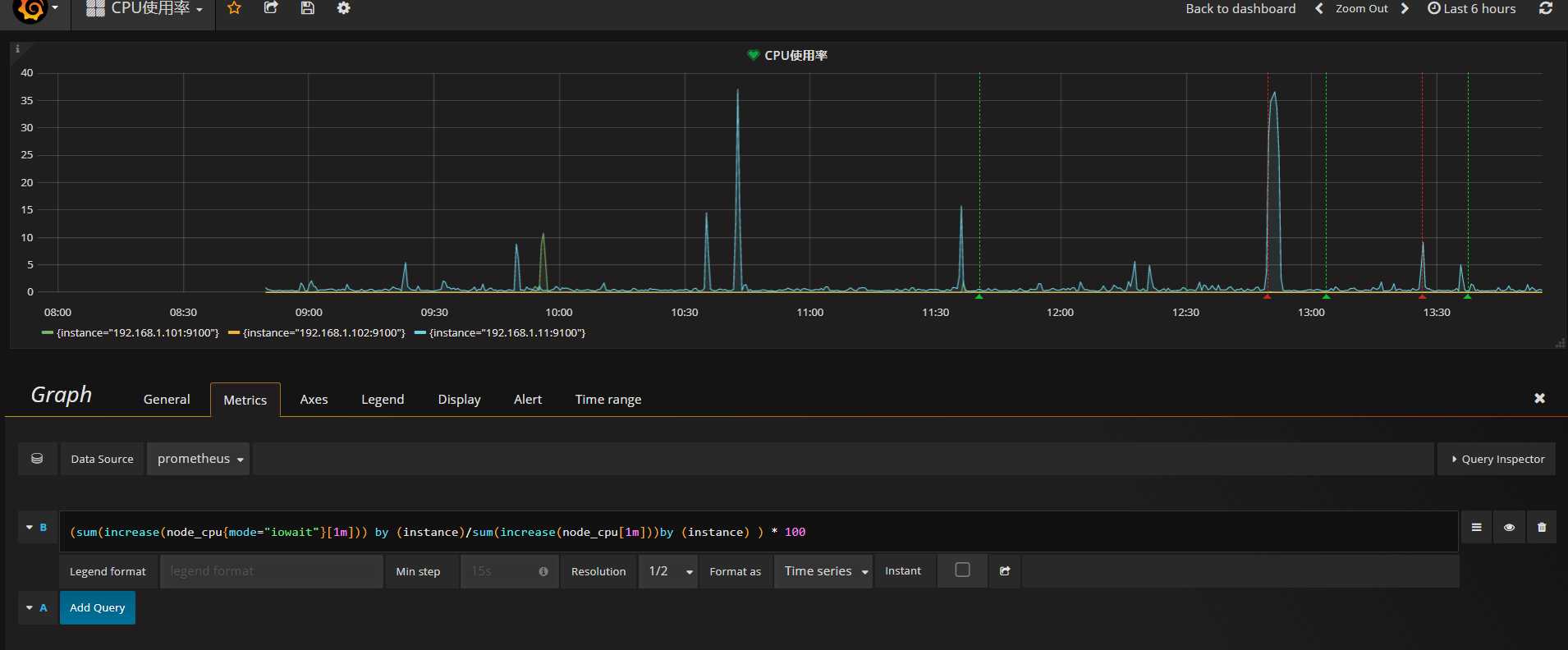
监控公式是
(sum(increase(node_cpu{mode="iowait"}[1m])) by (instance)/sum(increase(node_cpu[1m]))by (instance) ) * 100
第?个图 是针对 IOWAIT类型的 CPU等待时间 user% 其中不同的地? 是mode=iowait
很多情况下 , 当服务器 硬盘IO占?过?时,CPU会等待IO 的返回 进? interuptable 类型的CPU等待时间 所以 对于 IOWAIT CPU的监控 是很有必要的
grafana 另外 对于CPU?的报警阈值 是这样的设置的
设置成 99 或者 100 都可以 如果设置成 80 90 就报警,根据实际测试 并不合适,因为 80% 90%状态下的服务器 还是可以处理请求的 只不过速度会慢了 但是 ?旦综合CPU上了 98 99 100 那么整个服务器 就?乎失 去可?性了 连SSH登录 有时候都很困难 所以 针对Linux系统的优化 ?常重要 要通过各种内核参数 软 件参数 来控制服务器 尽量不让CPU堆到 99 100
接下来 就到了 内存监控了 ?先 ??需要给?家 说?下 内存的计算?式 我们先从Linux命令来看起
free -m

内存管理 是Linux内核的 ?常重要的?个强势功能 可以说 Linux对于内存的使?率 ?常的?校 ?起windows来说 真的智能了很多
主要依赖于 Linux内存管理的 缓存功能 (简单来说就是 刚? 过的内存中的内容 会被暂时缓存?段时间 以备下次再使? 快 速调?)
然? 5.x 6.x 的 内存命令 却有?点 不太善解?意 对于 ?多数的零基础和初级学员来说, 命令?显?的这个
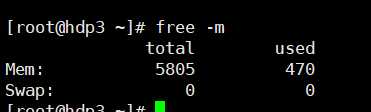
很容易让?误解
直接给出?家 5.x 6.x 的真实内存使?率公式即可
从应?用程序的?角度来说,Linux 实际可?用内存=系统free memory+bu?ers+cached。
Centos 7.x
对于 最新的 7.x中 free 命令?的输出 解决了这个问题 变得简单易懂 实际可?内存 直接放在最后?列 直接使?
接下来我们来看 企业实际内存监控案例
监控公式适用于CentOS 5 6 7
(1-((node_memory_Buffers+ node_memory_Cached+ node_memory_MemFree) / node_memory_MemTotal)) * 100
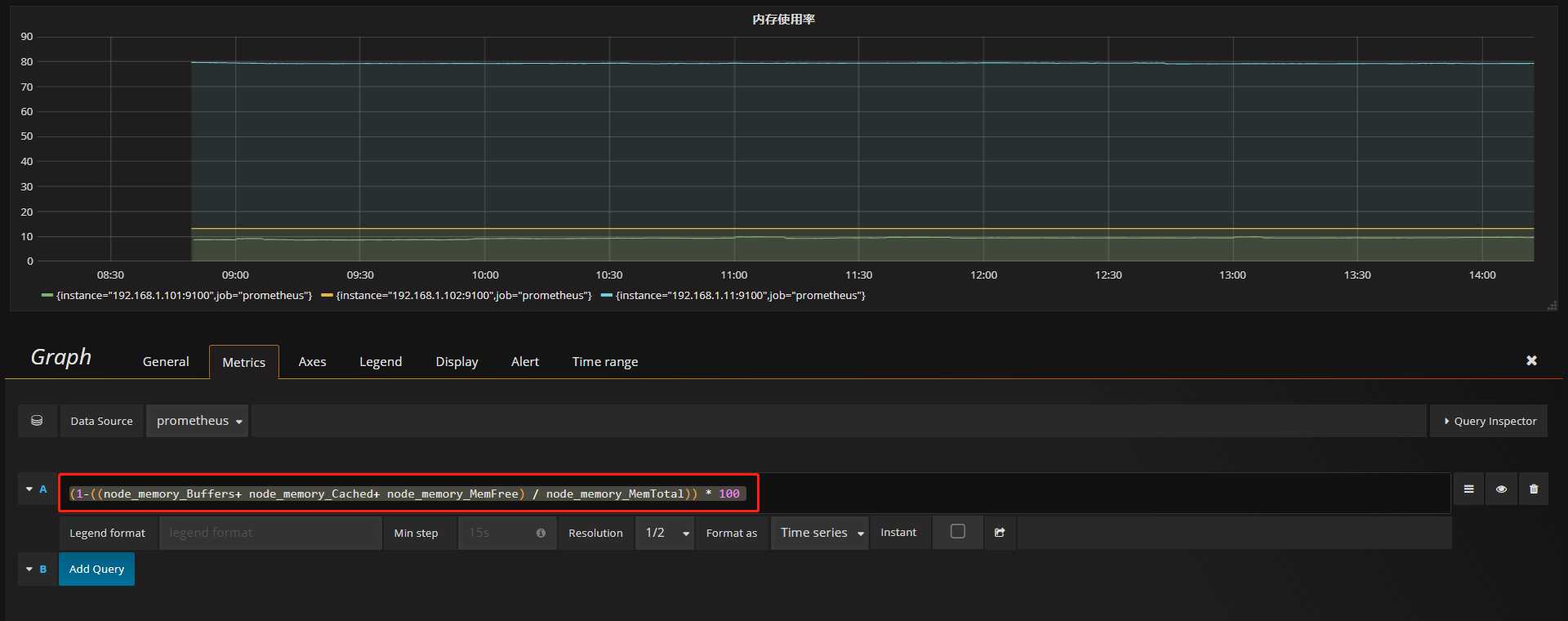
所以说 我们从内存的计算公式来说, promehtues也让我们很 精细 很放? , 很多?式的监控 直接返回?个 内存使?率 很 多时候 ?法确认准确性
数据来源:Node_exporter
硬盘剩余容量的监控 相?上?的2个 就简单很多
(node_filesystem_free/node_filesystem_size)<0.2
当硬盘空闲率小于20%则显示
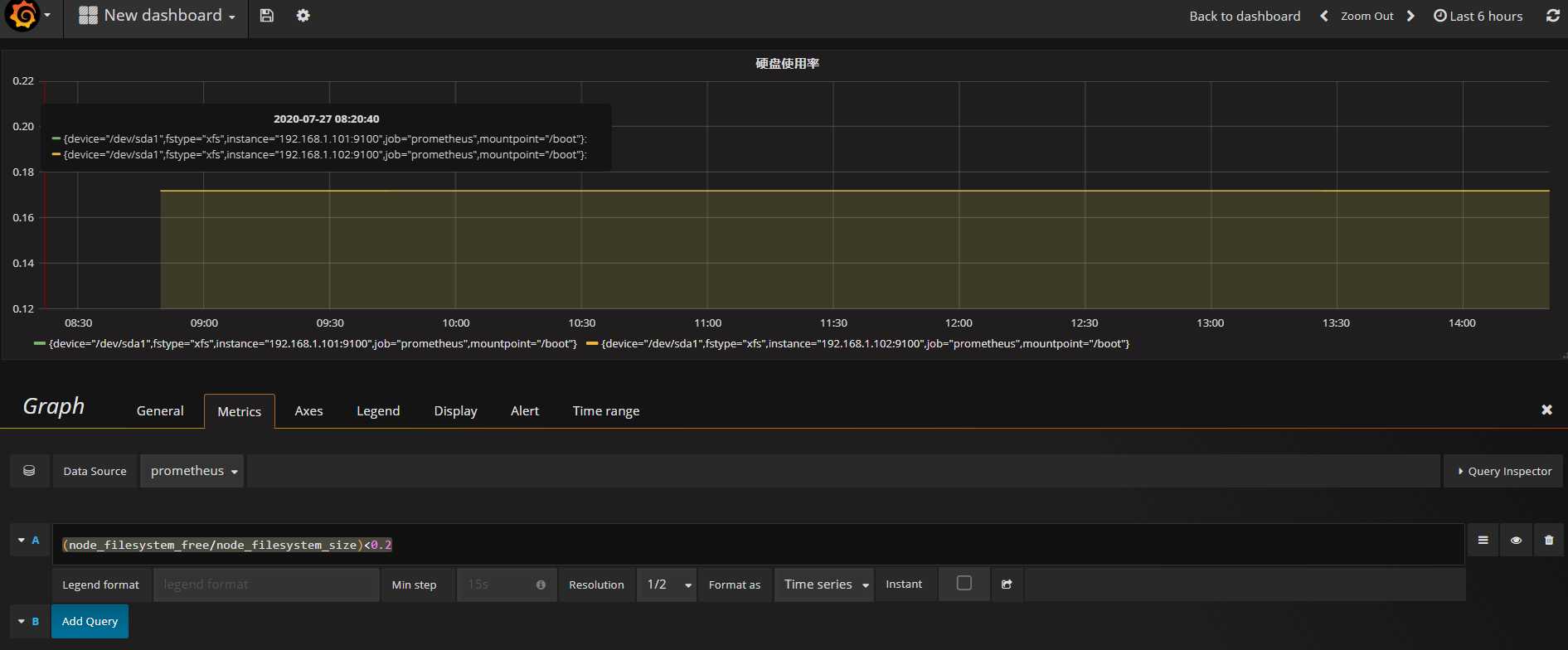
我在这? 给?家推荐另?个 难度较?的 prometheus 函数 predict_linear()
对于硬盘使?率来说
通常不管使? 什么样?的监控?具 基本上 都是简单算法 空 闲/总量 或 以使?/总量 当?于或?于 ?个阈值时 报警
这么定义的?法 ?较简单也普遍
这个函数 如果想讲清楚它的底层实现原理 没个 2 3天还真说 不完 我们在这?就给?家简单介绍?下它能做什么吧 对于刚才那种 硬盘百分?报警的案例(剩余空间的百分?) predict_linear() 函数 可以起到 对曲线变化速率的计算 以及在 ?段时间 加速度的未来预测 说的更简单?些 它可以 实时监测 硬盘使?率曲线的 变化情况,假如在?个很 ?的时间段中 发现硬盘使?率 急速的下降(跟之前平缓时期 相?较)
那么对这种下降的速度 进??个未来?段时间的预测 , 如果 发现 未来 ?如5分钟内 按照这个速度 硬盘肯定就100%了 那么 在当前硬盘还剩余 20%的时候 就会报警!
说起来都觉得绕? 不过使?起来 并不是很难
官网介绍
https://prometheus.io/docs/prometheus/latest/querying/functions/#predict_linear()
然后 我们来看下 硬盘IO使?的 监控
使用的公式
((rate(node_disk_bytes_read[1m] )+ rate(node_disk_bytes_written[1m])) / 1024 /1024) > 0
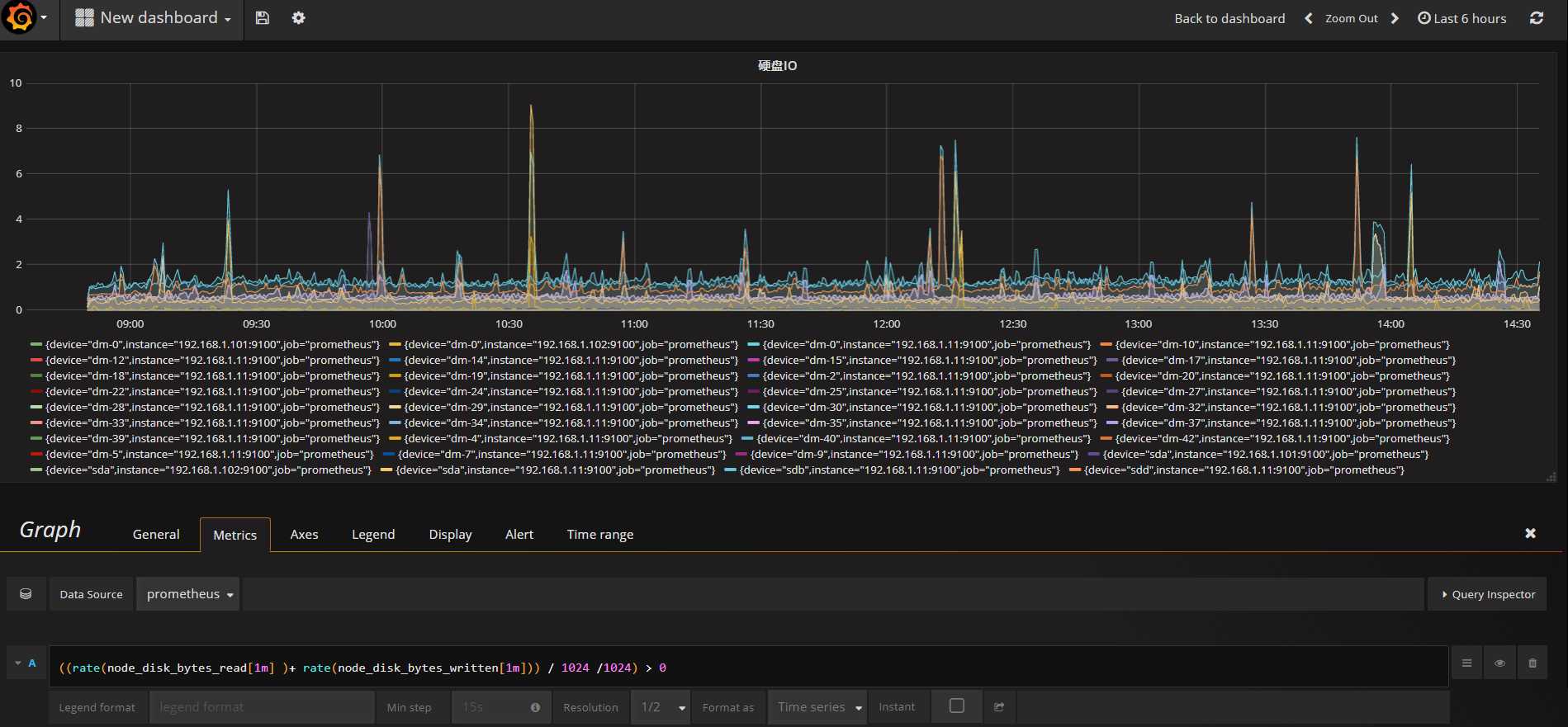
硬盘IO针对不同服务器差别较大,生产中可以多分几张图进行区分
硬盘使?率 是 read + written 读和写 都会占?IO /1024 两次后 就由 bytes => Mbs
如果这个指标标?了, 那么必然 CPU_IOWAIT 也会飙?
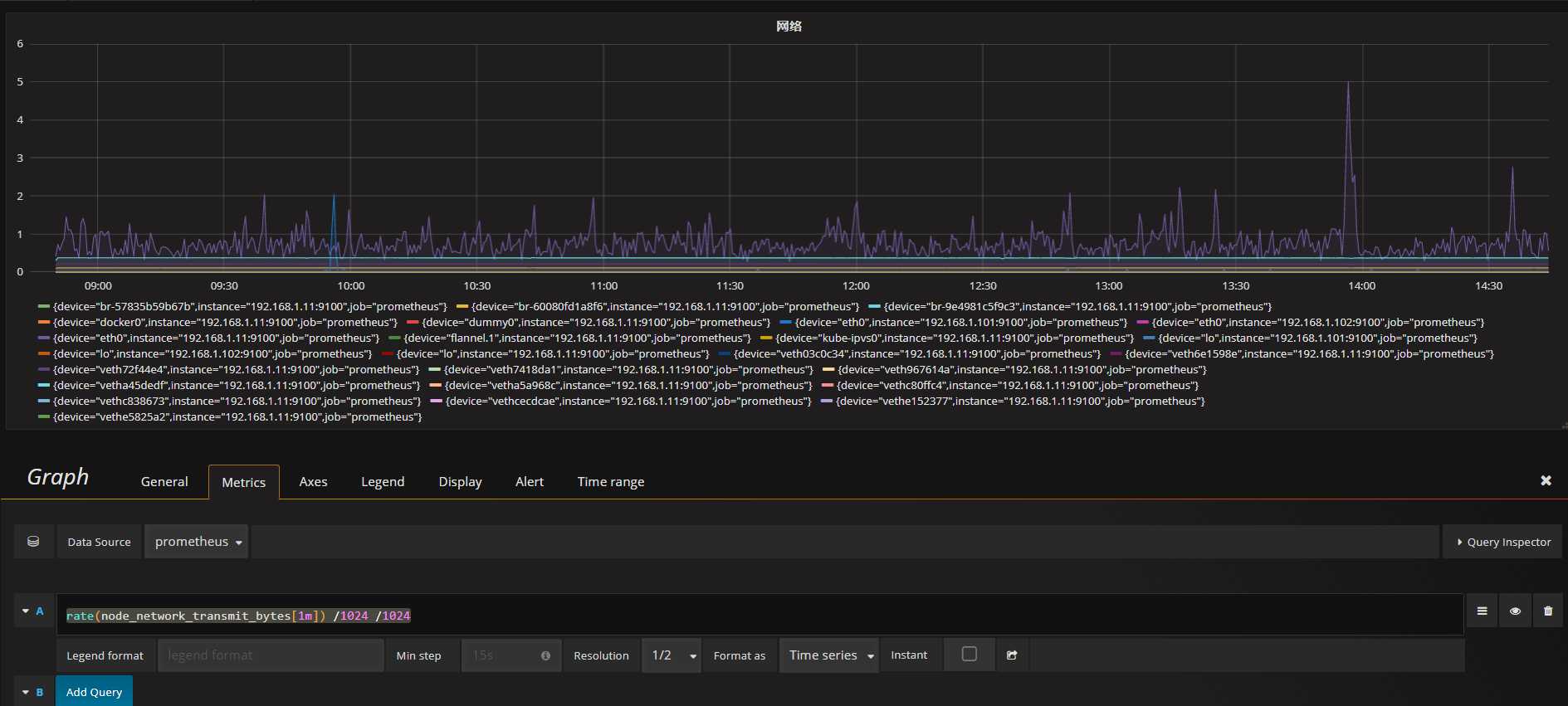
计算公式
rate(node_network_transmit_bytes[1m]) /1024 /1024
标签:显示 bsp 通过 csharp export incr 内存 算法 mic
原文地址:https://www.cnblogs.com/minseo/p/13385353.html