标签:target 记录 应该 mic blog into att The 修改
原文链接:https://blog.csdn.net/qq_36653505/java/article/details/90026373
关于 pytorch inplace operation需要注意的问题(data和detach方法的区别)
https://zhuanlan.zhihu.com/p/69294347
对于任意一个张量来说,我们可以用 tensor.is_leaf 来判断它是否是叶子张量(leaf tensor)。在反向传播过程中,只有 is_leaf=True 的时候,需要求导的张量的导数结果才会被最后保留下来。
对于 requires_grad=False 的 tensor 来说,我们约定俗成地把它们归为叶子张量。但其实无论如何划分都没有影响,因为张量的 is_leaf 属性只有在需要求导的时候才有意义。
我们真正需要注意的是当 requires_grad=True 的时候,如何判断是否是叶子张量:当这个 tensor 是用户创建的时候,它是一个叶子节点,当这个 tensor 是由其他运算操作产生的时候,它就不是一个叶子节点。我们来看个例子:
1 a = torch.ones([2, 2], requires_grad=True) 2 print(a.is_leaf) 3 # True 4 5 b = a + 2 6 print(b.is_leaf) 7 # False 8 # 因为 b 不是用户创建的,是通过计算生成的
这时有同学可能会问了,为什么要搞出这么个叶子张量的概念出来?原因是为了节省内存(或显存)。我们来想一下,那些非叶子结点,是通过用户所定义的叶子节点的一系列运算生成的,也就是这些非叶子节点都是中间变量,一般情况下,用户不会去使用这些中间变量的导数,所以为了节省内存,它们在用完之后就被释放了。
我们回头看一下之前的反向传播计算图,在图中的叶子节点我用绿色标出了。可以看出来,被叫做叶子,可能是因为游离在主干之外,没有子节点,因为它们都是被用户创建的,不是通过其他节点生成。对于叶子节点来说,它们的 grad_fn 属性都为空;而对于非叶子结点来说,因为它们是通过一些操作生成的,所以它们的 grad_fn 不为空。
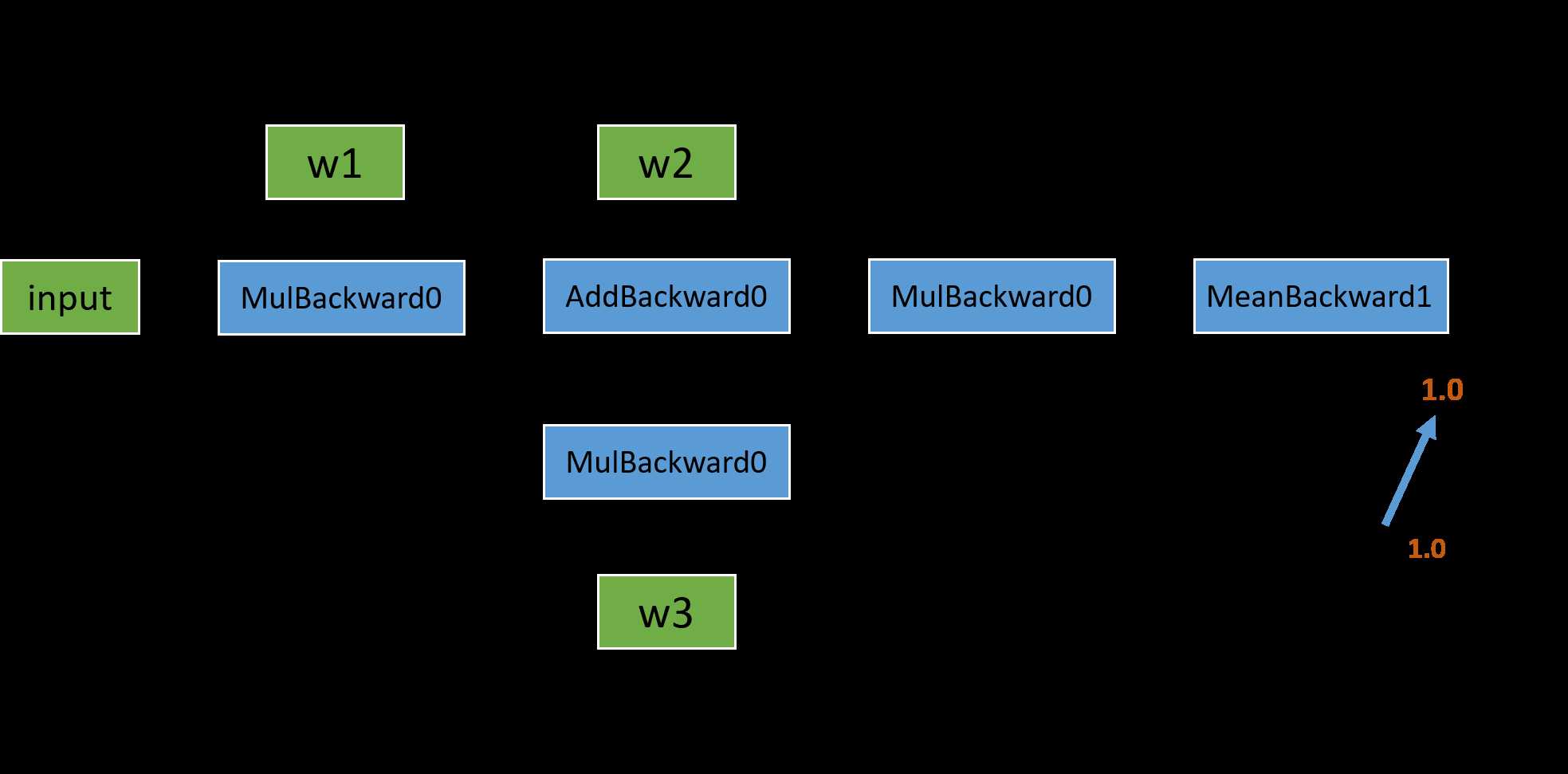
在编写 pytorch 代码的时候, 如果模型很复杂, 代码写的很随意, 那么很有可能就会碰到由 inplace operation 导致的问题. 所以本文将对 pytorch 的 inplace operation 做一个简单的总结。
inplace operation引发的报错:
1 RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation.
我们先来了解一下什么是 inplace 操作:inplace 指的是在不更改变量的内存地址的情况下,直接修改变量的值。
如 i += 1, i[10] = 0等
PyTorch 是怎么检测 tensor 发生了 inplace 操作呢?答案是通过 tensor._version 来检测的。我们还是来看个例子:
1 a = torch.tensor([1.0, 3.0], requires_grad=True) 2 b = a + 2 3 print(b._version) # 0 4 5 loss = (b * b).mean() 6 b[0] = 1000.0 7 print(b._version) # 1 8 9 loss.backward() 10 # RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation ...
每次 tensor 在进行 inplace 操作时,变量 _version 就会加1,其初始值为0。在正向传播过程中,求导系统记录的 b 的 version 是0,但是在进行反向传播的过程中,求导系统发现 b 的 version 变成1了,所以就会报错了。但是还有一种特殊情况不会报错,就是反向传播求导的时候如果没用到 b 的值(比如 y=x+1, y 关于 x 的导数是1,和 x 无关),自然就不会去对比 b 前后的 version 了,所以不会报错。
上边我们所说的情况是针对非叶子节点的,对于 requires_grad=True 的叶子节点来说,要求更加严格了,甚至在叶子节点被使用之前修改它的值都不行。我们来看一个报错信息:
1 RuntimeError: leaf variable has been moved into the graph interior
这个意思通俗一点说就是你的一顿 inplace 操作把一个叶子节点变成了非叶子节点了。我们知道,非叶子节点的导数在默认情况下是不会被保存的,这样就会出问题了。举个小例子:
1 a = torch.tensor([10., 5., 2., 3.], requires_grad=True) 2 print(a, a.is_leaf) 3 # tensor([10., 5., 2., 3.], requires_grad=True) True 4 5 a[:] = 0 6 print(a, a.is_leaf) 7 # tensor([0., 0., 0., 0.], grad_fn=<CopySlices>) False 8 9 loss = (a*a).mean() 10 loss.backward() 11 # RuntimeError: leaf variable has been moved into the graph interior
我们看到,在进行对 a 的重新 inplace 赋值之后,表示了 a 是通过 copy operation 生成的,grad_fn 都有了,所以自然而然不是叶子节点了。本来是该有导数值保留的变量,现在成了导数会被自动释放的中间变量了,所以 PyTorch 就给你报错了。还有另外一种情况:
1 a = torch.tensor([10., 5., 2., 3.], requires_grad=True) 2 a.add_(10.) # 或者 a += 10. 3 # RuntimeError: a leaf Variable that requires grad has been used in an in-place operation.
这个更厉害了,不等到你调用 backward,只要你对需要求导的叶子张量使用了这些操作,马上就会报错。那是不是需要求导的叶子节点一旦被初始化赋值之后,就不能修改它们的值了呢?我们如果在某种情况下需要重新对叶子变量赋值该怎么办呢?有办法!
1 # 方法一 2 a = torch.tensor([10., 5., 2., 3.], requires_grad=True) 3 print(a, a.is_leaf, id(a)) 4 # tensor([10., 5., 2., 3.], requires_grad=True) True 2501274822696 5 6 a.data.fill_(10.) 7 # 或者 a.detach().fill_(10.) 8 print(a, a.is_leaf, id(a)) 9 # tensor([10., 10., 10., 10.], requires_grad=True) True 2501274822696 10 11 loss = (a*a).mean() 12 loss.backward() 13 print(a.grad) 14 # tensor([5., 5., 5., 5.]) 15 16 # 方法二 17 a = torch.tensor([10., 5., 2., 3.], requires_grad=True) 18 print(a, a.is_leaf) 19 # tensor([10., 5., 2., 3.], requires_grad=True) True 20 21 with torch.no_grad(): 22 a[:] = 10. 23 print(a, a.is_leaf) 24 # tensor([10., 10., 10., 10.], requires_grad=True) True 25 26 loss = (a*a).mean() 27 loss.backward() 28 print(a.grad) 29 # tensor([5., 5., 5., 5.])
修改的方法有很多种,核心就是修改那个和变量共享内存,但 requires_grad=False 的版本的值,比如通过 tensor.data 或者 tensor.detach()(至于这二者更详细的介绍与比较,欢迎参照我 上一篇文章的第四部分)。我们需要注意的是,要在变量被使用之前修改,不然等计算完之后再修改,还会造成求导上的问题,会报错的。
为什么 PyTorch 的求导不支持绝大部分 inplace 操作呢?从上边我们也看出来了,因为真的很 tricky。比如有的时候在一个变量已经参与了正向传播的计算,之后它的值被修改了,在做反向传播的时候如果还需要这个变量的值的话,我们肯定不能用那个后来修改的值吧,但没修改之前的原始值已经被释放掉了,我们怎么办?一种可行的办法就是我们在 Function 做 forward 的时候每次都开辟一片空间储存当时输入变量的值,这样无论之后它们怎么修改,都不会影响了,反正我们有备份在存着。但这样有什么问题?这样会导致内存(或显存)使用量大大增加。因为我们不确定哪个变量可能之后会做 inplace 操作,所以我们每个变量在做完 forward 之后都要储存一个备份,成本太高了。除此之外,inplace operation 还可能造成很多其他求导上的问题。
总之,我们在实际写代码的过程中,没有必须要用 inplace operation 的情况,而且支持它会带来很大的性能上的牺牲,所以 PyTorch 不推荐使用 inplace 操作,当求导过程中发现有 inplace 操作影响求导正确性的时候,会采用报错的方式提醒。但这句话反过来说就是,因为只要有 inplace 操作不当就会报错,所以如果我们在程序中使用了 inplace 操作却没报错,那么说明我们最后求导的结果是正确的,没问题的。这就是我们常听见的没报错就没有问题。
在 pytorch 中, 有两种情况不能使用 inplace operation:
下面将通过代码来说明以上两种情况:
1 import torch 2 3 w = torch.FloatTensor(10) # w 是个 leaf tensor 4 w.requires_grad = True # 将 requires_grad 设置为 True 5 w.normal_() # 在执行这句话就会报错 6 # 报错信息为 7 # RuntimeError: a leaf Variable that requires grad has been used in an in-place operation.
很多人可能会有疑问, 模型的参数就是 requires_grad=true 的 leaf tensor, 那么模型参数的初始化应该怎么执行呢? 如果看一下 nn.Module._apply() 的代码, 这问题就会很清楚了
修改那个和变量共享内存,requires_grad=False 的版本的值
1 w.data = w.data.normal() # 可以使用曲线救国的方法来初始化参数
1 import torch 2 x = torch.FloatTensor([[1., 2.]]) 3 w1 = torch.FloatTensor([[2.], [1.]]) 4 w2 = torch.FloatTensor([3.]) 5 w1.requires_grad = True 6 w2.requires_grad = True 7 8 d = torch.matmul(x, w1) 9 f = torch.matmul(d, w2) 10 d[:] = 1 # 因为这句, 代码报错了 RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation 11 12 f.backward()

1 import torch 2 x = torch.FloatTensor([[1., 2.]]) 3 w1 = torch.FloatTensor([[2.], [1.]]) 4 w2 = torch.FloatTensor([3.]) 5 w1.requires_grad = True 6 w2.requires_grad = True 7 8 d = torch.matmul(x, w1) 9 d[:] = 1 # 稍微调换一下位置, 就没有问题了 10 f = torch.matmul(d, w2) 11 f.backward()
标签:target 记录 应该 mic blog into att The 修改
原文地址:https://www.cnblogs.com/jiangkejie/p/13390377.html