标签:指定 删除 公众 游标 存在 Scanner类 优先级队列 位置 机制
在了解HBase架构的基础上,我们需要进一步学习HBase的读写过程,一方面是了解各个组件在整个读写过程中充当的角色,另一方面只有了解HBase的真实请求过程,才能为后续的正确使用打下初步基础,毕竟,除了会使用api,你还得知道怎么能写得更快,怎么查得更快。1.首次读写的基本过程
在上一篇 深入HBase架构(建议收藏)中已经做了介绍。这里再重申一下。
这里要解决的主要问题是,
client如何知道去那个region server执行自己的读写请求。
有一个特殊的HBase表,叫做META table,保存了集群中各个region的位置。
而这个表的位置信息是保存在zookeeper中的。因此,当我们第一次访问HBase集群时,会做以下操作:
1)客户端从zk中获取保存meta table的位置信息,知道meta table保存在了哪个region server,并在客户端缓存这个位置信息;
2)client会查询这个保存meta table的特定的region server,查询meta table信息,在table中获取自己想要访问的row key所在的region在哪个region server上。
3)客户端直接访问目标region server,获取对应的row
这里我们需要关注一定,在读写的过程中,客户端实际上是不需要跟HMaster有任何交互的。这也是为什么我们在客户端的配置中,连接地址是填写的zookeeper的地址。
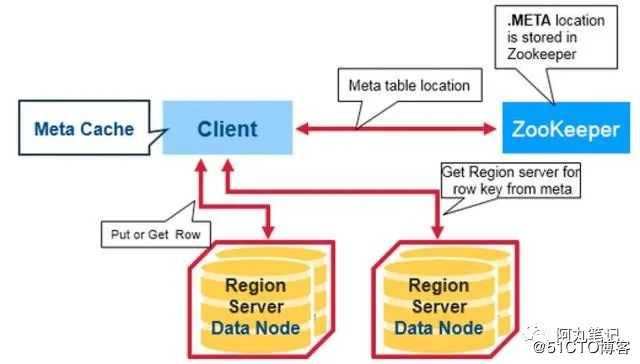
meta table信息都可以在client上进行缓存(apache的原生abase-client类的Connection的实现类中)。
2.写请求
从上文我们知道了,client如何找到目标region server发起请求。
接下来,就是正式的写操作了。
当client将写请求发送到客户端后,会执行以下流程。
(1)获取行锁:HBase中使用行锁保证对同一行数据的更新都是互斥操作,用以保证更新的原子性。
(2)Append HLog:顺序写入HLog中,并执行sync。
(3)写缓存memstore
(4)释放行锁
这里需要重点关注WAL。
WAL(Write-Ahead Logging)是一种高效、高可靠的日志机制。
基本原理就是在数据写入时,通过先顺序写入日志,然后再写入缓存,等到缓存写满之后统一落盘。
为什么可以提高写入性能和可靠性呢?
众所周知,对于磁盘的写入,顺序写性能是远高于随机写的。因此,WAL将将一次随机写转化为了一次顺序写加一次内存写,提高了性能。
至于可靠性,我们可以看到,因为先写日志再写缓存,即使发生宕机,缓存数据丢失,那么我们也可以通过恢复日志还原出丢失的数据。
另一方面,我们需要关注一下HBase中的各个结构的关系。
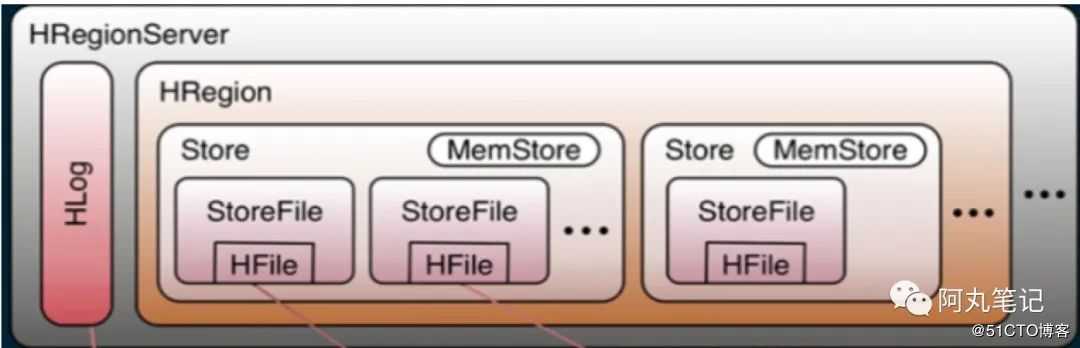
每个region server上只有一个HLog,但是有多个region。
每个HRegion里面有多个HStore,每个HStore会有一个写入缓存memstore,memstore是根据columnfamily来划分。
因此,在一个写入操作中,我们对任意一行的改变是落在memstore上,然后HBase并不会直接将数据落盘,而是先写入缓存,等缓存满足一定大小之后再一起落盘,生成新的HFile。
3.读请求
HBase-client上的读请求分为 两种,Get和Scan。
Get是一种随机查询的模式,根据给定的rowkey返回一行数据,虽然Get也支持输入多个rowkey返回多个结果,但是本质上是多次随机查询。具体rpc次数,看查询list的数据分布,如果都分布在一个region server上,就是一次rpc,如果是分布在3个rs,就是3次rpc,但是是并发请求和返回的,时间取决于最慢的那个。
Scan是一种批量查询的模式,根据指定的startRow和endRow进行范围扫描,获取区间内的数据。
而对于hbase服务端来说,当一个Get请求过来后,还是会转换为一个特殊的scan请求,即startrow和endrow一致的Scan请求。所以,下文的介绍,就围绕scan展开。
首先,我们要知道,HBase的写入很快,是追加多版本的形式,删除也很快,只是插入一条打上“deteled”标签的数据。因此,hbase的读操作比较复杂的,需要处理各种状态和关系。
因为Store是按照columfamily来划分的,一张表由N个列族组成,就有N个StoreScanner负责该列族的数据扫描。
当client要查询一个region,那么就会有一个RegionScanne,这个regionscannerr会创建N个StoreScanner。
而一个store由多个storefile和一个memstore组成,
因此,StoreScanner对象会创建一个MemStoreScanner和多个StoreFileScanner进行实际数据的读取。
这些scanner首先根据TimeRange和RowKey Range过滤掉一部分肯定无用的StoreFileScanner。
剩下的scanner组成一个最小堆KeyValueHeap。这个最小堆的实际数据结构是一个优先级队列,队列中所有元素是scanner,根据scanner指向的keyvalue进行排序(scanner类似游标,每次查询一个结果后,通过next下移找下一个kv值)。
举个简单的例子。
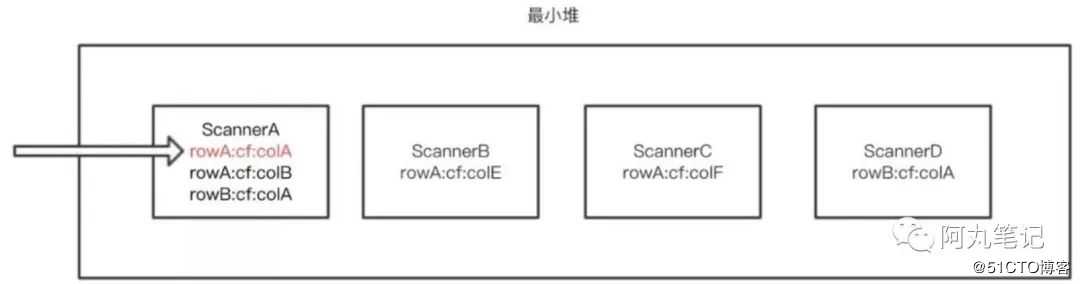
假设有4个scanner组成的优先级队列,分布标记为ScannerA\B\C\D。
1)查询的时候首先pop出heap的堆顶元素。
2)第一次pop出来的是scannerA。调用 next 请求,将会返回 ScannerA 中的 rowA:cf:colA,而后 ScannerA 的指针移动到下一个 KeyValue rowA:cf:colB;
3)重新组织堆中元素,堆中的 Scanners 排序不变;
4)第二次 pop出来的还是scannerA。调用next 请求,返回 ScannerA 中的 rowA:cf:colB,ScannerA 的 current 指针移动到下一个 KeyValue rowB:cf:ColA;
5)重新组织堆中元素,由于此时scannerA的指针指向了rowB,按照 KeyValue 排序可知 rowB 小于 rowA, 所以堆内部,scanner 顺序发生改变,改变之后如下图所示:
6)第三次pop出来的就是ScannerB了。
以此类推。
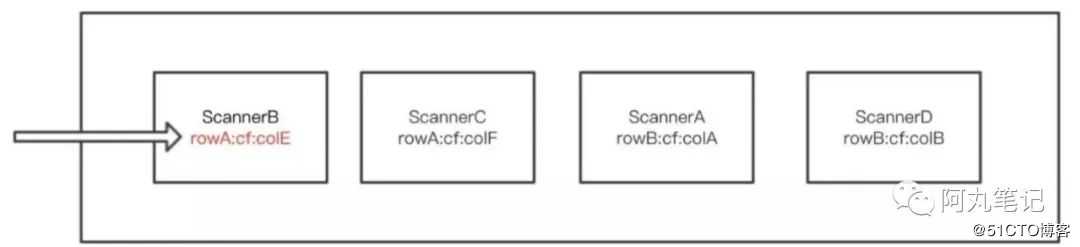
当某个scanner 内部数据完全检索之后会就会被 close 掉,或者 rowA 所有数据检索完毕,则查询下一条。
默认情况下返回的数据需要经过 ScanQueryMatcher 过滤返回的数据需要满足下面的条件:
我们经常听说HBase数据读取要读Memstore、HFile和Blockcache,为什么我们这里说Scanner只有StoreFileScanner和MemstoreScanner,而没有BlockcacheScanner呢?
因为HBase中数据仅独立地存在于Memstore和StoreFile中,Blockcache作为读缓存,里面有StoreFile中的部分热点数据,因此,如果有数据存在于Blockcache中,那么这些数据必然存在StoreFile中。因此使用MemstoreScanner和StoreFileScanner就可以覆盖到所有数据。
而在实际的读操作时,StoreFileScanner通过索引定位到待查找key所在的block之后,会先去查看该block是否存在于Blockcache中,如果存在,那么就会去BlockCache中取出,避免IO,如果BlockCache中不存在,才会再到对应的StoreFile中读取。
原创:阿丸笔记(微信公众号:aone_note),欢迎 分享,转载请保留出处。
扫描下方二维码可以关注我哦~
标签:指定 删除 公众 游标 存在 Scanner类 优先级队列 位置 机制
原文地址:https://blog.51cto.com/14887261/2514295