标签:完全 理解 依赖关系 目标 cond 场景 文件包含 名称 集成
随着机器学习(ML)在过去几年的快速发展,开始ML实验变得非常容易。多亏了像scikit-learn和Keras这样的库,用几行代码就可以创建模型。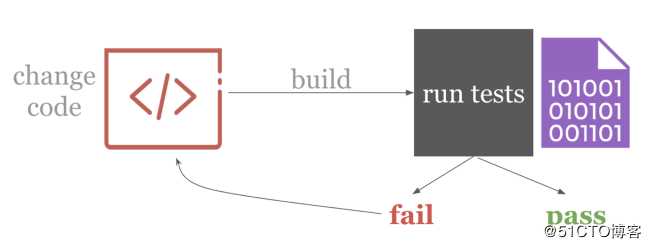
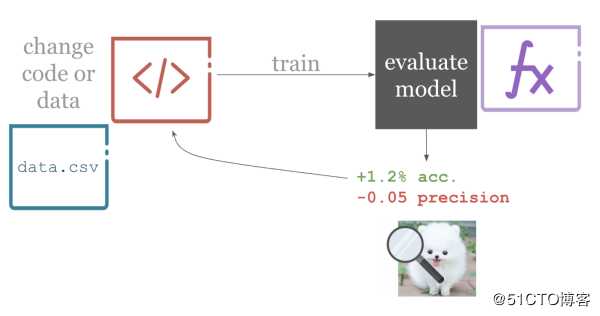
1. $ python train.py 2、你可以以某种方式更改项目存储库中的文件,然后Git提交更改。然后,推到GitHub存储库。
1. # Create a new git branch for experimenting
2. $ git checkout -b "experiment"
3. $ edit train.py
4. # git add, commit, and push your changes
5. $ git add . && commit -m "Normalized features"
6. $ git push origin experiment 3、一旦GitHub检测到push,GitHub就会部署他们的一台计算机来运行.yaml中的函数。
4、如果函数运行成功或失败,GitHub会返回一个通知。
在GitHub存储库的Actions选项卡中找到它
就是这样!真正奇妙的是,你正在使用GitHub的计算机来运行你的代码。你所要做的就是更新代码并将更改推送到存储库中,工作流就会自动发生。
回到我在第1步中提到的特殊的.yaml文件——让我们快速查看一个。它可以有任何你喜欢的名称,只要文件扩展名是.yaml,并且它存储在.github/workflows目录中。这里有一个:
1. # .github/workflows/ci.yaml
2. name: train-my-model
3. on: [push]
4. jobs:
5. run:
6. runs-on: [ubuntu-latest]
7. steps:
8. - uses: actions/checkout@v2
9. - name: training
10. run: |
11. pip install -r requirements.txt
12. python train.py 有很多操作在进行,但大多数操作都是相同的——你可以复制粘贴这个标准的GitHub动作模板,但在“运行”字段中填写你的工作流。
如果这个文件在你的项目repo中,每当GitHub检测到对你的代码的更改(通过push注册),GitHub Actions就会部署一个Ubuntu运行程序,并尝试执行你的命令来安装需求并运行Python脚本。请注意,你必须在项目repo中包含你的工作流所需的文件——这里是requirementes .txt和train.py。
得到更好的反馈
正如我们之前提到的,自动训练是非常酷的,但重要的是要有一个容易理解的形式的结果。目前,GitHub操作允许你访问运行的纯文本日志。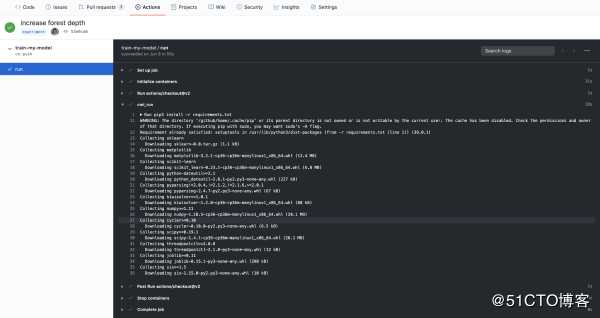
从GitHub动作日志中打印出来的示例
但是理解你的模型的性能是很棘手的。模型和数据是高维的,并且通常是非线性的——如果没有图片,这两件事是特别难以理解的。
我可以向你展示一种将数据viz放入CI循环的方法。在过去的几个月里,我的团队在Iterative.ai(我们做数据版本控制)正在开发一个工具包,帮助在机器学习项目中使用GitHub动作和GitLab CI。它被称为持续机器学习(简称CML),并且是开源免费的。
从“让我们使用GitHub动作来训练ML模型”的基本思想出发,我们构建了一些函数来提供比通过/失败通知更详细的报告。CML帮助你在报告中放入图像和表格,就像这个由SciKit-learn生成的混淆矩阵: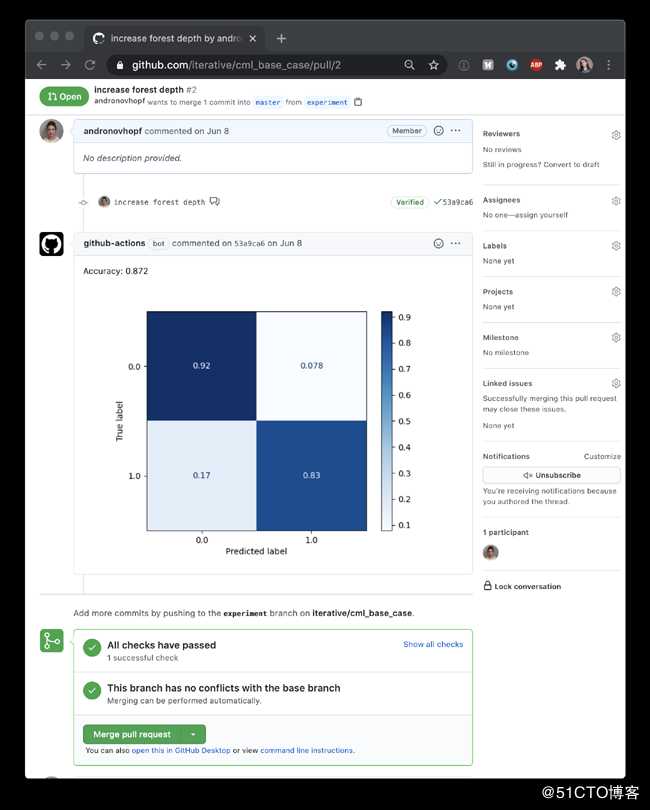
当你在GitHub中请求Pull时,这个报告就会出现
为了制作这个报告,我们的GitHub操作执行了一个Python模型训练脚本,然后使用CML函数将我们的模型准确性和混淆矩阵写入一个markdown文档。然后CML将减价文档传递给GitHub。
我们修改后的.yaml文件包含以下工作流(新添加的行被加粗以示强调):
1. name: train-my-model
2. on: [push]
3. jobs:
4. run:
5. runs-on: [ubuntu-latest]
6. container: docker://dvcorg/cml-py3:latest
7. steps:
8. - uses: actions/checkout@v2
9. - name: training
10. env:
11. repo_token: ${{ secrets.GITHUB_TOKEN }}
12. run: |
13.
14. # train.py outputs metrics.txt and confusion_matrix.png
15. pip3 install -r requirements.txt
16. python train.py
17.
18. # copy the contents of metrics.txt to our markdown report
19. cat metrics.txt >> report.md
20. # add our confusion matrix to report.md
21. cml-publish confusion_matrix.png --md >> report.md
22. # send the report to GitHub for display
23. cml-send-comment report.md 你可以在这里看到整个项目存储库。注意,我们的.yaml现在包含更多的配置细节,比如一个特殊的Docker容器和一个环境变量,以及一些要运行的新代码。容器和环境变量细节在每个CML项目中都是标准的,而不是用户需要操作的东西,所以请关注代码。
在工作流中添加了这些CML功能后,我们在CI系统中创建了一个更完整的反馈循环:
? 创建一个Git分支并更改该分支上的代码。
? 自动训练模型并产生度量(准确性)和可视化(混淆矩阵)。
? 将这些结果嵌入到Pull请求的可视报告中。
现在,当你和你的团队成员决定你的变更是否对你的建模目标有积极的影响时,你就有了一个可以检查的仪表板。另外,Git还将此报告链接到你的确切项目版本(数据和代码)、用于训练的跑步器以及那次运行的日志。很彻底,不再有那些很久以前就失去了与代码的任何连接的图形在你的工作空间中浮动。
这就是数据科学项目中CI的基本思想。明确地说,这个示例是使用CI的最简单方法之一。在现实生活中,你可能会遇到相当复杂的场景。CML还有一些功能可以帮助你使用存储在GitHub存储库之外的大型数据集(使用DVC),并在云实例上进行训练,而不是使用默认的GitHub动作运行器。这意味着你可以使用GPU和其他专门的设置。
例如,我做了一个使用GitHub Actions部署EC2 GPU的项目,然后训练一个神经类型的传输模型。以下是我的CML报告: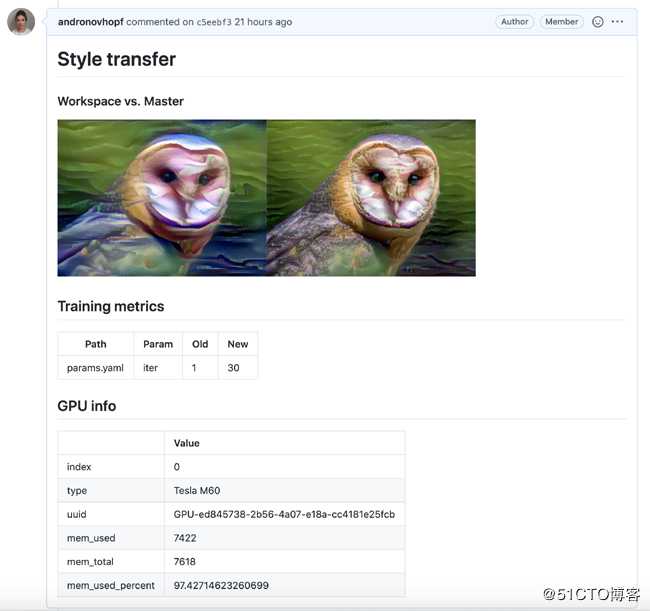
你还可以使用自己的Docker容器,这样就可以在生产中紧密地模拟模型的环境。以后我将更多地介绍这些高级用例。
关于ML的CI的最后思考
总结一下我们到目前为止所说的:
DevOps不是一种特定的技术,而是一种哲学、一套原则和实践,用于从根本上重构创建软件的过程。它之所以有效,是因为它解决了团队如何工作和试验新代码的系统瓶颈。
随着数据科学在未来几年的成熟,懂得如何将DevOps原则应用到他们的机器学习项目中的人将成为一种有价值的商品——无论是从薪水还是从组织影响的角度。持续集成是DevOps的主要内容,也是构建具有可靠自动化、快速测试和团队自治的文化的最有效的已知方法之一。
CI可以通过GitHub Actions或GitLab CI等系统实现,你可以使用这些服务来构建自动模型培训系统。好处很多:
? 你的代码、数据、模型和培训基础设施(硬件和软件环境)都是Git版本化的。
? 你正在自动化工作,频繁地进行测试并获得快速的反馈(如果使用CML,则使用可视化的报告)。从长远来看,这几乎肯定会加速项目的开发。
? CI系统使你的工作对团队中的每个人都可见。没有人需要非常费力地搜索你的最佳运行的代码、数据和模型。
我保证,一旦你进入最佳状态,通过一个Git提交自动启动你的模型训练、记录和报告是非常有趣的。
你会觉得很酷。
【编辑推荐】
标签:完全 理解 依赖关系 目标 cond 场景 文件包含 名称 集成
原文地址:https://blog.51cto.com/14887308/2516497