标签:embedding ict inf app 课程 cuda 全连接 mic image
在上一篇blog里,ATP分析了TransCoder模型最顶层的main函数,理清了它的训练过程是怎么循环的。
这次ATP本来想要看一下它的模型具体是什么样子的。但ATP发现,pretrain过程(只有encoder)和后续的过程(同时有encoder和decoder)它模型的结构与训练过程还是差别很大的。
为了避免ATP的blog写得太乱七八糟,ATP决定这次先有针对性地去看一下MLM的训练过程,也就是只有encoder的时候它是怎么操作的。
只考虑MLM的过程的话,build_model这块内容非常简单,就是建立了一个Transformer的encoder。基本结构整理出来就像下面这样:
def build_model(params, dico):
"""
Build model.
"""
if params.encoder_only:
# build
model = TransformerModel(
params, dico, is_encoder=True, with_output=True)
# reload pretrained word embeddings
if params.reload_emb != ‘‘:
......
# reload a pretrained model
if params.reload_model != ‘‘:
......
......
return [model.cuda()]
在用MLM进行pretrain的时候,参数里面的“reload_emb”和“reload_model”都是空串,意思是既不需要载入已有的embedding,也不需要载入已有的model(因为MLM过程是训练的第一个过程,不需要从别的地方载入什么东西)。
而通过对比可以发现,在进行DAE/BT的训练时,reload_model这个参数有值,指向的是用MLM训练好的model。这也进一步印证了该模型的训练过程是先MLM,再DAE/BT。
Transformer内部的细节ATP没有仔细看。ATP倾向于认为它就是一个普通的transformer。
在main函数中,模型建立完成后,又定义了一个trainer。这个类的定义位于XLM/src/trainer.py中,作用是执行训练的步骤。
例如在主循环中,mlm_step这个函数就是trainer类的一个成员函数,作用是执行一次MLM的训练。
# generate batch / select words to predict
x, lengths, positions, langs, _ = self.generate_batch(lang1, lang2, ‘pred‘)
x, lengths, positions, langs, _ = self.round_batch(x, lengths, positions, langs)
x, y, pred_mask = self.mask_out(x, lengths)
mlm_step函数首先通过generate_batch这个函数生成一批数据。虽然这个函数返回很多个值,但在MLM过程中我们只需要关注x(返回的数据)和lengths(数据的长度)。
round_batch是与fp16有关的。mask_out是给数据打mask的,返回的x,y,pred_mask三个参数分别是打过mask的数据、原始数据,以及一个布尔数组表示哪里打了mask。
接下来,将得到的数据推送到显存上后,就可以开始训练了。mlm_step的核心语句是这几句:
# forward / loss
tensor = model(‘fwd‘, x=x, lengths=lengths, positions=positions, langs=langs, causal=False)
_, loss = model(‘predict‘, tensor=tensor, pred_mask=pred_mask, y=y, get_scores=False)
self.stats[(‘MLM-%s‘ % lang1) if lang2 is None else (‘MLM-%s-%s‘ % (lang1, lang2))].append(loss.item())
loss = lambda_coeff * loss
这段语句的前两行是在调用transformer类的成员函数。它们的作用光看字面意思就能猜个大概,就是把数据送入transformer,过了encoder以后再预测mask的内容,然后与真实的数据(y)算出loss进行优化。
其中,fwd函数返回的是输入数据过了encoder与一个额外的全连接层(FFN)后的输出,而predict函数利用这个输出来进行预测并计算loss。
原理和这个图是一样的:
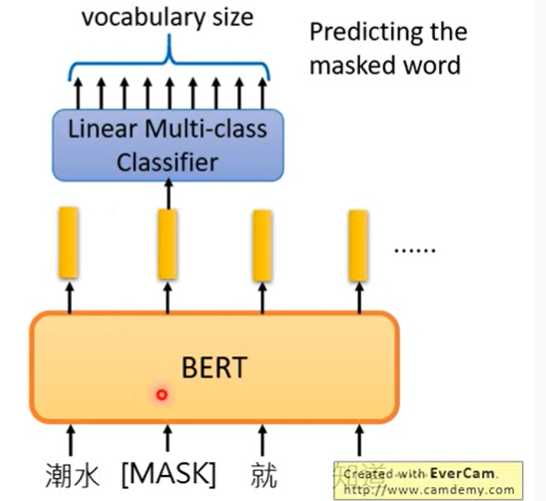
这个图是从李宏毅的讲BERT的课程视频里截出来的。关于这个训练过程他的解释是,因为线性分类器是相对比较弱的一种分类器,所以分类的效果更多地取决于encoder所作出的embedding是不是准确。所以这个MLM的训练过程能有效地训练模型的embedding能力。
另外,TransCoder的原论文中提到,模型能work的关键是它找到了不同语言之间的anchor point,也就是具有相同表示的token。ATP其实对这个地方的理解一直比较模糊。它现在认为这个anchor point应该指的是在embedding之后位置相近(或相同)的token,也就是说不同语言中上下文语境相似的token。
标签:embedding ict inf app 课程 cuda 全连接 mic image
原文地址:https://www.cnblogs.com/FromATP/p/13425447.html