标签:物联网 工作 智能 客服端 互联网 程序 cluster 管理数据 client
随着互联网不断得突飞猛进,数据就逐渐演变为科技和经济发展的核心。更是对于互联网时代的人类和企业来说,是至关重要的,可能对于普通人来说没有太大影响,但是对于国家和大型企业来说,数据就是其命脉,人工智能就是对数据海量化的最好证明之一。所以,数据存储的稳定在一定程度上就可以决定人类经济的高度。
但是,许多人还没有搞清楚个人电脑互联网是什么,移动互联网在这里,当我们还没搞清楚移动互联网的时候,大数据时代又来了," 马云在离任时说。大数据的应用已经进入了一个快速发展的时期,未来一种新的商业模式的出现有望带来更大的发展。
由于以人工智能、5G 和物联网为主导的新一轮信息技术革命,数据中心的迅速增长导致存储产业链的需求大幅增加。在全球和中国数据存储需求迅速增长的背后,必然伴随着产业链的繁荣。
目前市场中,HDFS分布式存储系统是很热门的讨论话题,各种企业也倾向于搭建分布式存储系统。
那么什么是 HDFS 分布式存储?
HDFS分布式存储公链是一套完整的个人数据存储解决方案,它由无数的节点以p2p的形式组成一个数据存储阵列,采用POC+POST的双重共识机制来识别及分配奖励,采用加密机制对数据传输及存储过程进行保护形成一套安全、高效、经济的个人数据存储全套解决方案。
分布式存储框架
分布式存储技术的实现,往往离不开底层的分布式存储框架。根据其存储的类型,可分为块存储,对象存储和文件存储。在主流的分布式存储技术中,HDFS属于文件存储,Swift属于对象存储,而Ceph可支持块存储、对象存储和文件存储,故称为统一存储。
分布式存储
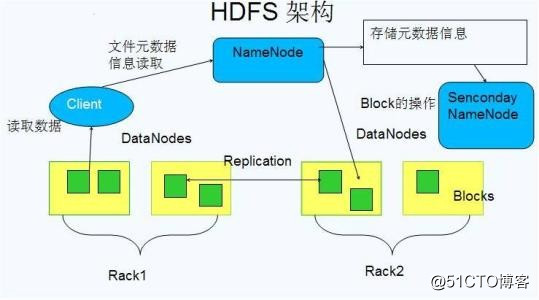
HDFS是Hadoop核心组成之一,是分布式计算中数据存储管理的基础,被设计成适合运行在通用硬件上的分布式文件系统。
HDFS的功能模块
Client
Client是用户与HDFS交互的手段,当文件上传 HDFS 的时候,Client 将文件切分成一个一个的 Block,然后进行上传;Client通过与NameNode 交互,来获取文件的位置信息;与 DataNode 交互,读取或者写入数据;Client还可以提供NameNode格式化等一些命令来管理HDFS;同时,Client可以通过对HDFS的增删改查等操作来访问HDFS。
NameNode
NameNode就是HDFS的Master架构,它维护着文件系统树及整棵树内所有的文件和目录,HDFS文件系统中处理客服端读写请求、管理数据块(Block)的映射信息、配置副本策略等管理工作由NameNode来完成。
DataNode
NameNode 下达命令,DataNode 执行实际操作。DataNode表示实际存储的数据块,同时可以执行数据块的读写操作。
Secondary NameNode
Secondary NameNode的功能主要是辅助NameNode,分担其工作量;在紧急情况下可以辅助恢复NameNode,但是它不能替换NameNode并提供服务。
HDFS的优势
1.容错性:数据自动保存多个副本。通过增加副本的形式,提高容错性。其中一个副本丢失以后,可以自动恢复。
可以处理大数据:能够处理数据规模达到GB、TB甚至PB级别的数据;能够处理百万规模以上的文件数量。
可以构建在廉价的机器上,通过多副本机制,提高可靠性。
HDFS的特点
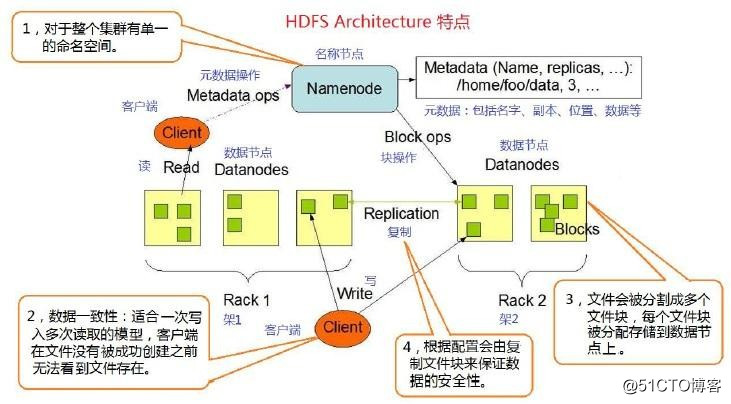
1、故障检测和恢复 – 由于 HDFS 包含大量产品硬件,组件故障频繁。因此,HDFS 应具有快速自动故障检测和恢复的机制。
2、数据集的管理 – HDFS 每个群集都有数百个节点来管理具有大型数据集的应用程序。
3、数据硬件处理 – 当计算在数据物理附近时,可以高效地完成请求的任务。特别是在涉及大量数据集时,它减少了网络流量并提高了吞吐量。
分布式存储
HDFS的功能
1)数据的分布式存储和处理。
2)Hadoop 提供了一个命令接口来与 HDFS 进行交互。
3)namenode 和 datanode 的内置服务器可帮助用户轻松检查群集的状态。
4)对文件系统数据的流式处理访问。
5)HDFS 提供文件权限和身份验证。
HDFS的元素
1.Namenod
Namenode是包含 GNU/Linux 操作系统的产品硬件。它是一种可以在产品硬件上运行的软件。具有Namenode的系统充当主服务器,并执行以下任务。
1)管理文件系统命名空间
2)调节客户端对文件的访问
3)执行文件系统操作,如重命名、关闭和打开文件和目录。
2.Datanode
Datanode是具有 GNU/Linux 操作系统和数据内核软件的产品硬件。对于cluster(群集)中的每个产品硬件/系统,都将有一个数据节点,这些节点管理其系统的数据存储。
1)根据客户端请求在文件系统上执行读写操作。
2)根据 namenode 的说明执行块创建、删除和复制等操作。
3.Block
通常,用户数据存储在 HDFS 的文件中。文件系统中的文件将分为一个或多个片段存储在单个数据节点中。这些文件段称为block。换句话说,HDFS 可以读取或写入的最小数据量称为block。默认块大小为 64MB,可以根据 HDFS 配置进行更改。
综上所述就是本篇文章的全部内容,更多HDFS相关信息敬请关注。
HDFS分布式存储中NameNode 和DataNode 有什么区别?
标签:物联网 工作 智能 客服端 互联网 程序 cluster 管理数据 client
原文地址:https://blog.51cto.com/14804622/2521416