标签:处理 扩容 逻辑 架构 理念 替代 com loading 获取
TiDB 是 PingCAP 公司自主设计、研发的开源分布式关系型数据库,是一款同时支持在线事务处理与在线分析处理 (Hybrid Transactional and Analytical Processing, HTAP)的融合型分布式数据库产品,具备水平扩容或者缩容、金融级高可用、实时 HTAP、云原生的分布式数据库、兼容 MySQL 5.7 协议和 MySQL 生态等重要特性。目标是为用户提供一站式 OLTP (Online Transactional Processing)、OLAP (Online Analytical Processing)、HTAP 解决方案。TiDB 适合高可用、强一致要求较高、数据规模较大等各种应用场景。
PS:OLTP与OLAP
数据处理大致可以分成两大类:联机事务处理OLTP(on-line transaction processing)、联机分析处理OLAP(On-Line Analytical Processing)。
OLTP是传统的关系型数据库的主要应用,主要是基本的、日常的事务处理,例如银行交易。强调数据库内存效率,强调内存各种指标的命令率,强调绑定变量,强调并发操作
OLAP是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。 则强调数据分析,强调SQL执行市场,强调磁盘I/O,强调分区等。

大多数情况下,无需修改代码即可从 MySQL 轻松迁移至 TiDB,分库分表后的 MySQL 集群亦可通过 TiDB 工具进行实时迁移。
通过简单地增加新节点即可实现 TiDB 的水平扩展,按需扩展吞吐或存储,轻松应对高并发、海量数据场景。
TiDB 100% 支持标准的 ACID 事务。
相比于传统主从 (M-S) 复制方案,基于 Raft 的多数派选举协议可以提供金融级的 100% 数据强一致性保证,且在不丢失大多数副本的前提下,可以实现故障的自动恢复 (auto-failover),无需人工介入。
TiDB 作为典型的 OLTP 行存数据库,同时兼具强大的 OLAP 性能,配合 TiSpark,可提供一站式 HTAP 解决方案,一份存储同时处理 OLTP & OLAP,无需传统繁琐的 ETL 过程。
TiDB 是为云而设计的数据库,支持公有云、私有云和混合云,使部署、配置和维护变得十分简单。
可以看出 TiDB 是 Spanner 理念的一个完美实践,一个 TiDB 集群由 TiDB、PD、TiKV 三个组件构成。
TiKV Server:负责数据存储,是一个提供事务的分布式 Key-Value 存储引擎;
PD Server:负责管理调度,如数据和 TiKV 位置的路由信息维护、TiKV 数据均衡等;
TiDB Server:负责 SQL 逻辑,通过 PD 寻址到实际数据的 TiKV 位置,进行 SQL 操作。
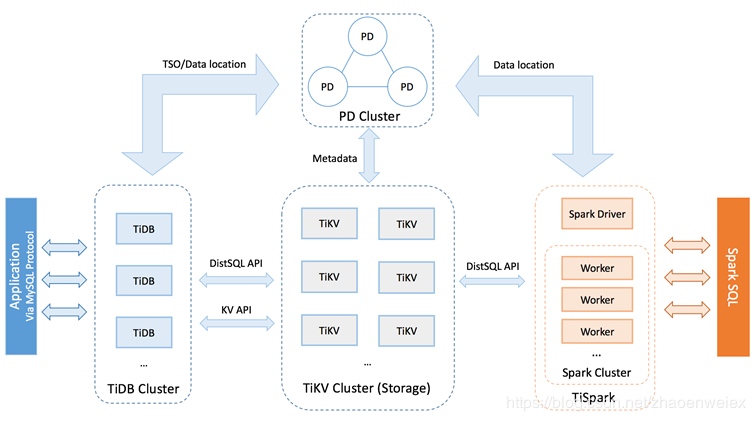
TiDB Server 负责接收 SQL 请求,处理 SQL 相关的逻辑,并通过 PD 找到存储计算所需数据的 TiKV 地址,与 TiKV 交互获取数据,最终返回结果。
TiDB Server 是无状态的,其本身并不存储数据,只负责计算,可以无限水平扩展,可以通过负载均衡组件(如LVS、HAProxy 或 F5)对外提供统一的接入地址。
Placement Driver (简称 PD) 是整个集群的管理模块,其主要工作有三个:一是存储集群的元信息(某个 Key 存储在哪个 TiKV 节点);二是对 TiKV 集群进行调度和负载均衡(如数据的迁移、Raft group leader 的迁移等);三是分配全局唯一且递增的事务 ID。
PD 是一个集群,需要部署奇数个节点,一般线上推荐至少部署 3 个节点。
TiKV Server 负责存储数据,从外部看 TiKV 是一个分布式的提供事务的 Key-Value 存储引擎。存储数据的基本单位是 Region,每个 Region 负责存储一个 Key Range(从 StartKey 到 EndKey 的左闭右开区间)的数据,每个 TiKV 节点会负责多个 Region。TiKV 使用 Raft 协议做复制,保持数据的一致性和容灾。副本以 Region 为单位进行管理,不同节点上的多个 Region 构成一个 Raft Group,互为副本。数据在多个 TiKV 之间的负载均衡由 PD 调度,这里也是以 Region 为单位进行调度
TiSpark 作为 TiDB 中解决用户复杂 OLAP 需求的主要组件,将 Spark SQL 直接运行在 TiDB 存储层上,同时融合 TiKV 分布式集群的优势,并融入大数据社区生态。至此,TiDB 可以通过一套系统,同时支持 OLTP 与 OLAP,免除用户数据同步的烦恼。
对数据一致性及高可靠、系统高可用、可扩展性、容灾要求较高的金融行业属性的场景
众所周知,金融行业对数据一致性及高可靠、系统高可用、可扩展性、容灾要求较高,传统的解决方案是同城两个机房提供服务、异地一个机房提供数据容灾能务但不提供服务,此解决方案存在资源利用率低、维扩成本高、RTO 及 PRO 无法真实达到企业所期望的值。TiDB 采用多副本 + Mutli Raft 协议的方式将数据调度到不同的机房、机架、机器,当部分机器故障时系统可自动进行切换,确保系统的 RTO <= 30s 及 RPO = 0 。
对存储容量、可扩展性、并发要求较高的海量数量及高并的 OLTP 场景
随着业务的高速发展,数据呈现爆炸性的增长,传统的单机数据库无法满足因数据爆炸性的增长对数据的容量要求,可行方案是采用分库分表的中间件产品或者 NewSQL 数据库替代、采用高端的存储设备等,其中性价比最大的是 NewSQL 数据库,例如:TiDB。TiDB 采用计算、存储分离的架构,可对计算、存储分别进行扩容和缩容,计算节点最大支持 512 节点,每个节点最大支持 1000 并发,集群容量最大支持 PB 级别。
Real-time HTAP 场景
随着 5G、物联网、人工智能的高速发展,企业所生产的数据会越来越多,其规模可能达到数百 TB 甚至 PB 级别,传统的解决方案是通过 OLTP 型数据库处理在线联机交易业务,通过 ETL 工具将数据同步到 OLAP 型数据库进行数据分析,这种处理方案存在存储成本高、实际性差等多方面的问题。TiDB 在 4.0 版本中引入列存储引擎 TiFlash 结合行存储引擎 TiKV 构建真正的 HTAP 数据库,在增加少量存储成本的情况下,可以同一个系统中做联机交易处理、实时数据分析,极大的节省企业的成本。
数据汇聚、二次加工处理的场景
当前绝大部分企业的业务数据都分散在不同的系统中,没有一个统一的汇总,随着业务的发展,企业的决策层需要了解整个公司的业务状况方便即时的做出决策,故需要将分散在各个系统的数据汇聚在同一个系统并进行二次加工处理生成 T + 0/1 的报表。传统常见的解决方案是采用 ETL + Hadoop 来完成,但 Hadoop 体系统太复杂,运维、存储成本太高无法满度用户的需求。与 Hadoop 相比,TiDB 就会简单得多,业务通过 ETL 工具或者 TiDB 的同步工具将数据同步到 TiDB,在 TiDB 中可通过 SQL 直接生成报表。
见:https://pingcap.com/docs-cn/stable/production-deployment-using-tiup/
※更多文章和资料|点击后方文字直达 ↓↓↓
100GPython自学资料包
阿里云K8s实战手册
[阿里云CDN排坑指南]CDN
ECS运维指南
DevOps实践手册
Hadoop大数据实战手册
Knative云原生应用开发指南
OSS 运维实战手册
云原生架构白皮书
Zabbix企业级分布式监控系统源码文档
Linux&Python自学资料包
10G面试题戳领
标签:处理 扩容 逻辑 架构 理念 替代 com loading 获取
原文地址:https://www.cnblogs.com/woshijiuke/p/13531104.html