标签:src 时序 翻译 http term memory 决定 连接 语音
循环神经网络往往应用于具有前后文关系的任务,比如语音识别,机器翻译,文本填空,股票预测,图像理解等等
RNN引入了时序的概念,有些类似于时序数字电路,由此具有记忆的能力
RNN的基本结构为
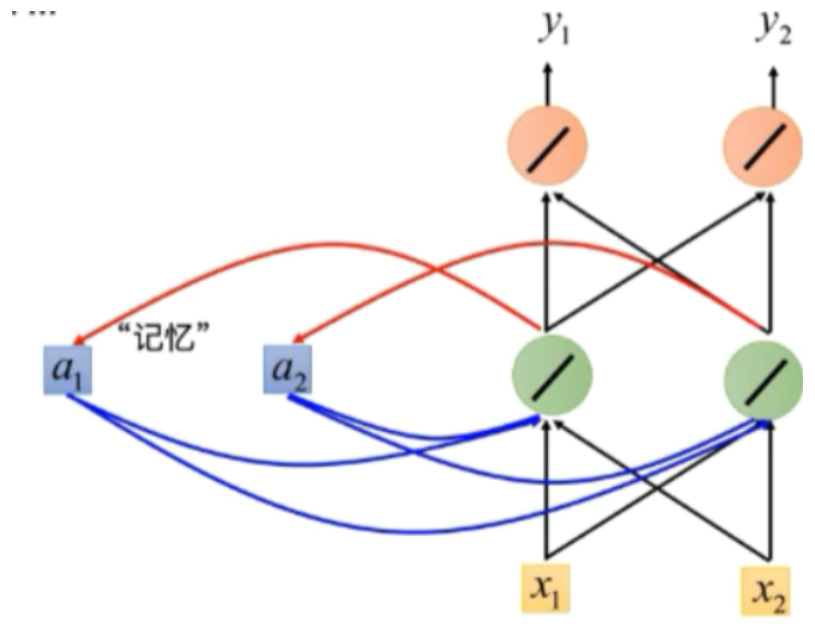
可以看到,最大的不同就是添加了记忆单元
整体结构为
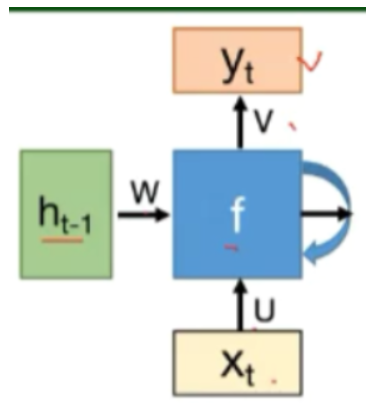
不断地对 \(h_t\) 进行更新,使其具有记忆功能,其中 \(U,V,W\) 为模型参数,\(f\) 可以用双曲正切函数 \(tanh\) ,模型输出由以下式子决定
\(y_t\) 为时刻 \(t\) 的模型输出
横向排列,可以得到RNN的基本模型
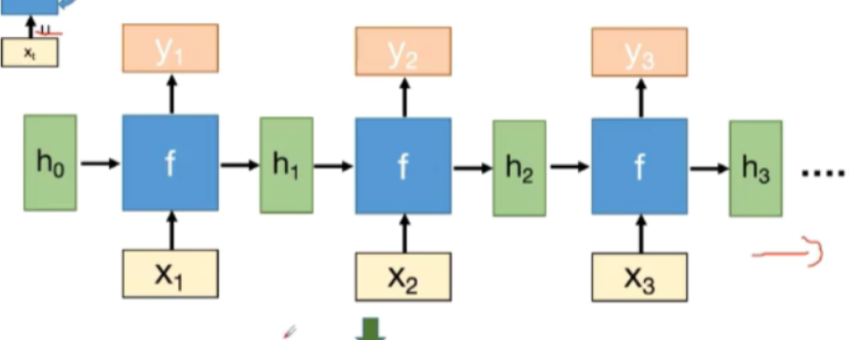
可以在深度上拓展,构成深度结构
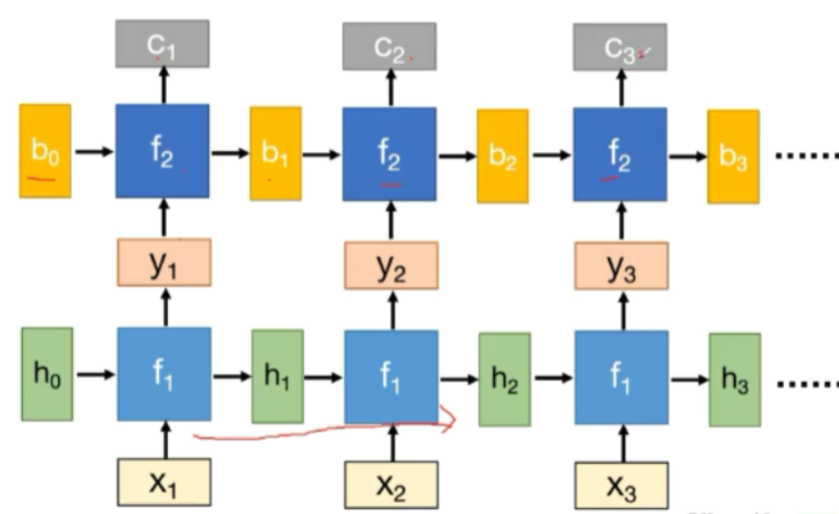
或者反向连接,构成双向RNN
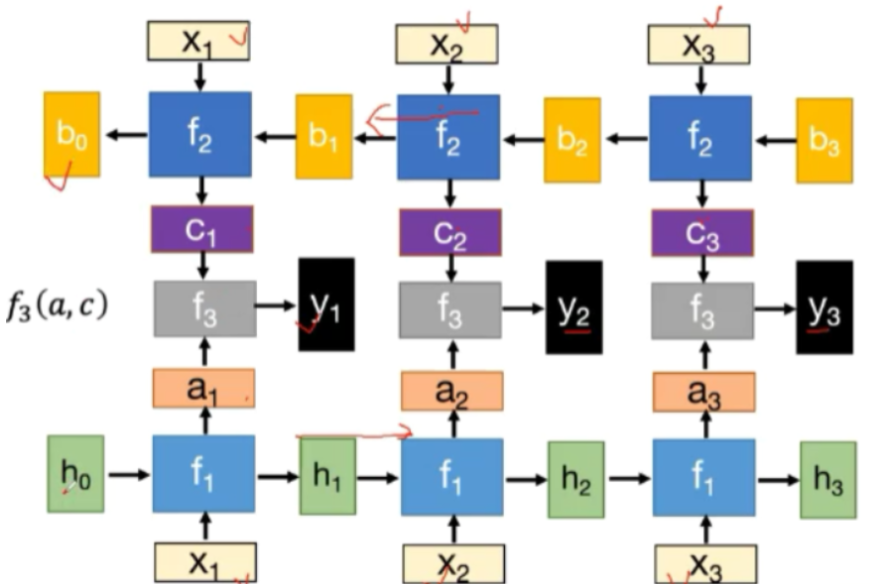
神经网络的基本模型为
对 \(\sigma(z)\) ,我们有
所以
BPTT算法采用同样的思路,只不过输出依赖于前一时刻的输入,所以求导需要进行复合函数偏导求导法则
LSTM即Long Short-term Memory(长短期记忆模型),他模拟了人类记忆的规律,对信息进行特定遗忘和摄取便于处理信息,主要结构如下
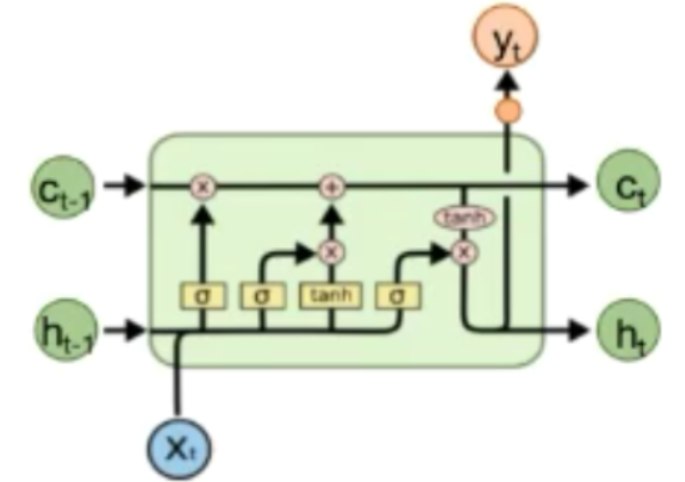
主要由三个门组成,分别是遗忘门,输入门和输出门,遗忘门主要是为了决定丢弃多少信息,输入门用来确定需要更新的信息(从不更新到完全更新),输出门则用于输出数据,LSTM的模型如下所示
在训练时,LSTM的学习率应该尽量小以避免梯度消失
GRU结构为
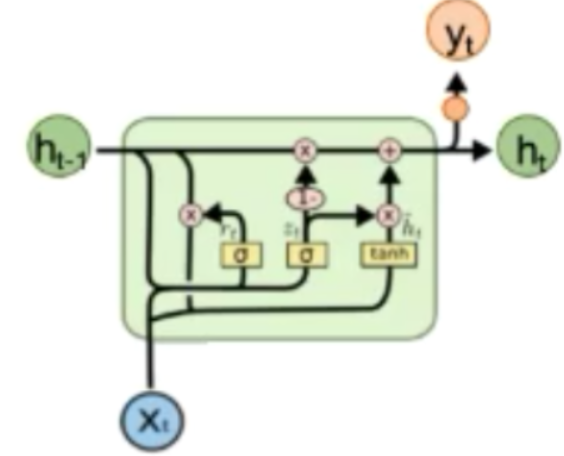
GRU相较LSTM,只有两个门,分别是重置门和更新门,重置门主要是用来控制上一时刻状态信息保留的多少,而更新门则控制上一时刻用以计算当前时刻数据的影响的大小,更新门值越大则表示前一时刻的状态信息带入的越多,其基本模型为
标签:src 时序 翻译 http term memory 决定 连接 语音
原文地址:https://www.cnblogs.com/sand65535/p/13543579.html