标签:设置 加载 内存分配 文件后缀名 阶段 经历 情况下 很多 载器
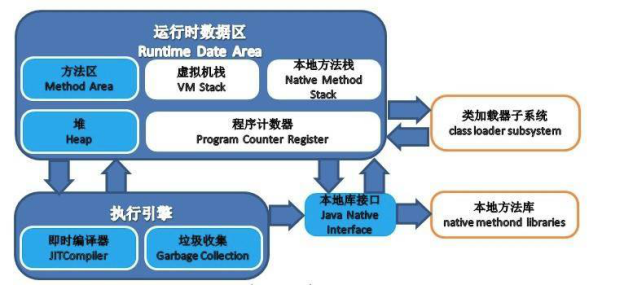
从图上看到,大致分为以下组件:
类加载子系统
运行时数据区
执行引擎
本地方法库
本地库接口
本地库接口也就是用于调用本地方法的接口,这次就不多说,主要是上面的4个组件。
类加载的过程包括了加载、验证、准备、解析和初始化这5个步骤
每一个类,都需要和它的类加载器一起确定其在JVM中的唯一性。换句话来说,不同类加载器的同一个字节码文件,得到的类都不相等。我们都可以通过默认加载器去加载一个类,然后new一个对象,再通过自己定义的一个类加载器,去加载同一个字节码文件,拿前面得到的对象去instanceof,会得到的结果是false。
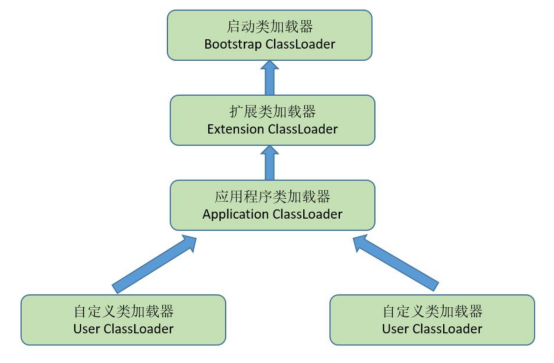
类加载器一般有4种,其中前3种是必然存在的
而双亲委派机制是如何运作的呢?
我们以应用程序加载器举例,它再需要加载一个类的时候,不会直接去尝试加载,而是委托上级的扩展类加载器去加载,而扩展类加载器也是委托启动类加载器去加载。启动类加载器再自己的搜索范围内没有找到这么一个类,表示自己无法加载,就再让扩展类加载器去加载,同样的,扩展类加载器再自己的搜索范围内找一遍,如果还是没有找到,就委托应用类程序去加载。如果最终还是没找到,那么久会直接抛出异常了。
而为什么要这么麻烦的从下到上,再从上到下呢?
这是为了安全着想,保证按照优先级加载,如果用户自己编写一个名为java.lang.Object的类,放到自己的Classpath中,没有这种优先级保证,应用程序类加载器就把这个当作Object加载到了内存中,从而会引发一片混乱,而凭借这种双亲委派机制,先一路向上委托,启动类加载器去找的时候,就把正确的Object加载到了内存中,后面再加载自行编写的Object的时候,是不会加载运行的。
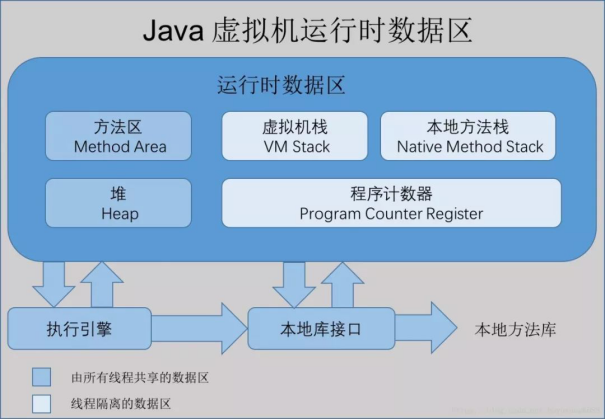
运行时数据区分为虚拟机栈,本地方法栈,堆区,方法区和程序计数器。其中方法区和堆是所有线程共享的数据区,虚拟机栈、本地方法栈和程序计数器是每条线程私有的数据区。
程序计数器是一块非常小的内存空间。可以看做事当前线程执行字节码文件的行号指示器,每个线程都有一个独立的程序计数器,因此程序计数器是线程私有的一块空间。此外,程序计数器是Java虚拟机规定的唯一不会发生内存溢出(OOM)的区域;
Java虚拟机栈也是线程私有的,每个方法执行都会创建一个栈帧,局部变量就存放在栈帧中,还有一些其他的动态链接、操作数栈,返回地址等。通常会有两个错误会跟这个有关系,一个是StackOverFlowError,一个是OOM(OutOfMemoryError)。前者是因为线程请求栈深度超出虚拟机所允许的范围,后者是因为动态扩展栈的大小的时候申请不到足够的内存空间。而前者提到的栈深度,也就是刚才说到的每个方法会创建一个栈帧,栈帧从开始执行方法压入Java虚拟机栈,执行完的时候弹出栈。当压入栈帧太多了,就会报出这个StackOverflowError。
一个栈帧对应Java代码中的一个方法,当线程执行到一个方法时,就代表这个方法对应的栈帧已经进入虚拟机栈并且处于栈顶的位置,每一个方法从被调用到执行结束,就对应了一个栈帧从入栈到出栈的过程。
本地方法栈与虚拟机栈的区别是,虚拟机栈执行的是Java的方法,本地方法栈执行的是本地方法(Native Method),其他基本上一致,在HotSpot中直接把本地方法栈和虚拟机栈合二为一。
方法区主要用于存储虚拟机加载的类信息、常量、静态变量,以及编译器编译后的代码等数据。在jdk1.7及其之前,方法区是堆一个“逻辑部分”(一片连续的堆空间),但为了与堆做区分,方法区还有个名字叫”非堆,也有人用”永久代“(HotSpot对方法区的实现方法)来表示方法区。
从jdk1.7已经开始准备”去永久代“的规划,jdk1.7的HotSpot中,已经把原本放在方法区中的静态变量、字符串常量池等移到堆内存中,(常量池除字符串常量池还有class常量等),这里只是把字符串常量池移动到堆内存中;在jdk1.8中,方法区已经不存在,原方法区中存储的类信息、编译后的代码数据等已经移动到了元空间(MateSpace)中,元空间并没有处于堆内存上,而是直接占用的本地内存(NativeMemory),元空间的大小仅受本地内存限制,但可以通过-XX:MetaSpaceSize和-XX:MaxMetaSpaceSize来指定元空间大小。
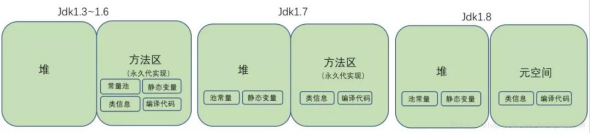
去永久代的原因有:
字符串在永久代中,容易出现性能问题和内存溢出。
类及方法的信息等比较确定其大小,因此对于永久代的大小指定比较困难,太小容易出现永久代溢出。太大则容易出现老年代溢出。
永久代会为垃圾回收(GC)带来不必要的复杂度,并且回收效率偏低。
堆和方法区一样(确切来说JVM规范中方法区就是堆的一个逻辑分区),就是一个所有线程共享的,存放对象和数组的区域,也是GC的主要区域。其中又可以细分为新生代,老年代。新生代占堆空间的1/3,老年代占2/3。新生代又可以细分为一个Eden区,两个Survivor区(From,To),它们默认的比例Eden:From:To=8:1:1。
Eden中存放的是通过new或者newInstance方法创建出来的对象,绝大多数都是很短暂的。征程情况下经历一次GC后,存活的对象会转入到其中一个Survivor区,然后再经历默认15次的GC,就转入老年代,这是常规状态下,再Survivor区已经满了的情况下,JVM会依据担保机制将一些对象直接放入老年代。
执行引擎包含即时编译器(JIT)和垃圾回收器(GC),对即时编译器我们简单介绍一下,主要重点在于垃圾回收器,关于垃圾回收的东西很多,会单独的讲一下。
看到这个东西的存在可能有些人会感到疑问,不是通过javac命令就能把java代码编译成字节码文件了吗?这个即时编译器又是干嘛的?
我们需要明确一个概念就是,计算机实际上只认识0和1,这种由0和1组成的命令集称之为”机器码“,而且会根据平台不同而有所不同,可读性和可移植性极差。我们的字节码文件包含的并不是机器码,不能由计算机直接运行,而需要JVM”解释“执行。JVM将字节码文件中所写的命令解释成一个个计算机操作命令,再通知计算机运行;
JIT并不是Java虚拟机规范定义中必须存在的,但它又是JVM性能重要的影响因素之一。
再上面的内容里,提到了HotSpot这么一个名字,它是我们一直使用这款虚拟机的名称。HotSpot中文意思是“热点”,而HotSpot VM的特点之一也就是可以探测并优化热点代码,JIT就是它的优化方式。
HotSpot通过计数器以及其他方式,监测到某些方法或者某些代码块执行的频率很高,就会将其编译成为平台相关的机器码,甚至于在保证结果的情况下通过优化执行顺序等方式进行优化,这种机器码的执行效率比解释执行要高出很多。而编译完成后,会通过“栈上替换”等方式进行动态的替换,比如循环执行,循环一次JIT的计数器就+1,到了阈值的时候就开始变扭重复执行的代码,同时为了不影响系统的运行,原来的解释执行仍然继续,直到在第N次循环时,编译完成,会在N+1次执行前替换成编译后的机器码执行。
计数器分为两种,一种方法调用计数器,一种回边计数器。
方法计数器就是用于统计方法的直接调用,而回边计数器用于循环代码的技术。检测的是频率,所以它们的计数值不会一直累加,而是在一定时间段内叠加,而超过时间段还没有达到阈值,就减半。这个减半称为“热度衰减”,而这个时间段被称为“半衰周期”。
但编译称为机器码需要时间,会导致JVM启动时间边长,内存消耗也会增加,所以需要根据实际情况权衡,在启动时附加命令选择执行模式。
用native修饰的,不能和abstract共同使用的,不显示方法体但却是用非Java语言实现方法体的方法。
例如Object中的getClass()方法
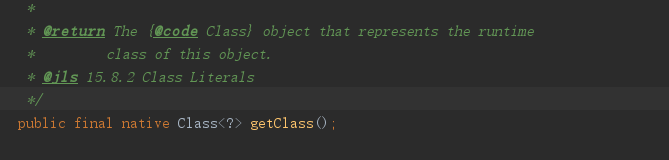
一个Native Method就是一个Java调用非Java代码接口。该方法的实现由非Java语言实现,比如C。定义一个native方法时,并不提供实现体,因为由非Java实现。
本地接口的作用是融合不同的编程语言为Java所用。
有时Java应用需要与Java外面的环境交互,这是本地方法存在的主要原因。Java需要与一些底层系统比如操作系统或某些硬件交换信息,本地方法正是这样一种交流机制,它为我们提供了一个非常简洁的接口,而且我们无需去了解Java应用外的复杂细节。
JVM并非一个真实的操作系统,需要依赖具体的操作系统去实现。通过本地方法,可以利用Java实现了jre的与底层系统的交互。
标签:设置 加载 内存分配 文件后缀名 阶段 经历 情况下 很多 载器
原文地址:https://www.cnblogs.com/cqy1026/p/13561110.html