标签:pil 控制 启动 zook water expand temp 部分 opera
https://www.yuque.com/cdhongit/wzu20x
由于传统数据库的成熟以及广泛的应用,目前大多数场景下数据管理与分析系统都是建立在关系型数据库基础之上的,数据的采集、加工、处理都是在关系型数据库总完成的。要实现大数据的处理与分析还需要把数据从关系型数据库导入 Hadoop 平台,利用 Hadoop 平台强大的数据处理能力来分析数据。处理完成后的数据再把结果导入关系型数据库中,以方便数据的决策利用。这就设计到数据的互导问题。
Sqoop 由 SQL 与 Hadoop 组合而成,是基于 Hadoop 的数据传输和迁移工具。主要用于在关系型数据库、Hadoop、数据仓库、NoSQL系统中传递数据。通过 Sqoop 我们可以很方便地将数据从关系型数据库中导入到HDFS、Hive、HBae,或者将数据从 HDFS 中导出到关系型数据库。
Sqoop 的底层实现是 MapReduce,所以Sqoop 依赖于 Hadoop,数据是并行导入**的**。Sqoop充分利用了 MapReduce 的并行特点,以批处理的方式加快数据的传输,同时也借助 MapReduce 实现了容错。
Sqoop 数据迁移工具Sqoop 的安装与部署Sqoop 简单使用Sqoop导入数据准备sqoop-import 语法和相关参数导入emp表的所有字段导入至 HDFS导入 MySQL 数据到 HiveSqoop导出sqoop-export导出 HDFS 数据到 MySQL导出表时指定字段与分隔符
到
解压到安装目录,并创建软连接 sqoop。
[root@node01 local]# tar -zxvf sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz -C /usr/local/
[root@node01 local]# ln -s sqoop-1.4.7.bin__hadoop-2.6.0 sqoop
这里要使用到 mysql 与 hive ,故需把 mysql 的 驱动程序 mysql-connector-java-5.1.46.jar 与 hive 的 相关组件包 hive-exec-2.3.3.jar 拷贝到 Sqoop 的依赖库lib下。
[root@node01 lib]# cp hive-exec-1.2.1.jar /usr/local/sqoop/lib/
配置Sqoop环境变量,在 Sqoop 安装目录的 conf 子目录下,系统已经提供了一个环境变量文件模板sqoop-env-template.sh,使用 cp 操作复制一个副本,并改名为 sqoop-env.sh,修改sqoop-env.sh (可选,一般安装了Hadoop、HBase、Hive后可不配置此文件)
[root@node01 sqoop]# cd conf/
[root@node01 conf]# cp sqoop-env-template.sh sqoop-env.sh
[root@node01 conf]# vim sqoop-env.sh
#Set path to where bin/hadoop is available
export HADOOP_COMMON_HOME=/usr/local/hadoop
?
#Set path to where hadoop-*-core.jar is available
export HADOOP_MAPRED_HOME=/usr/local/hadoop
?
#set the path to where bin/hbase is available
#export HBASE_HOME=
?
#Set the path to where bin/hive is available
export HIVE_HOME=/usr/local/hive
?
#Set the path for where zookeper config dir is
#export ZOOCFGDIR
添加环境变量,并重新加载
[root@node01 lib]# vim /etc/profile
## SQOOP_HOME
export SQOOP_HOME=/usr/local/sqoop
export PATH=$PATH:$SQOOP_HOME/bin
?
[root@node01 lib]# source /etc/profile
测试 环境配置
[root@node01 local]# sqoop version
Warning: /usr/local/sqoop/../hbase does not exist! HBase imports will fail.
Please set $HBASE_HOME to the root of your HBase installation.
Warning: /usr/local/sqoop/../hcatalog does not exist! HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your HCatalog installation.
Warning: /usr/local/sqoop/../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
20/09/04 14:31:41 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7
Sqoop 1.4.7
git commit id 2328971411f57f0cb683dfb79d19d4d19d185dd8
Compiled by maugli on Thu Dec 21 15:59:58 STD 2017
启动的时候,有相关的警告信息,我们可以配置bin/configure-sqoop 文件,先注释对应的相关语句,当然也可以不用管。
## Moved to be a runtime check in sqoop.
#if [ ! -d "${HBASE_HOME}" ]; then
# echo "Warning: $HBASE_HOME does not exist! HBase imports will fail."
# echo ‘Please set $HBASE_HOME to the root of your HBase installation.‘
#fi
?
## Moved to be a runtime check in sqoop.
#if [ ! -d "${HCAT_HOME}" ]; then
# echo "Warning: $HCAT_HOME does not exist! HCatalog jobs will fail."
# echo ‘Please set $HCAT_HOME to the root of your HCatalog installation.‘
#fi
?
#if [ ! -d "${ACCUMULO_HOME}" ]; then
# echo "Warning: $ACCUMULO_HOME does not exist! Accumulo imports will fail."
# echo ‘Please set $ACCUMULO_HOME to the root of your Accumulo installation.‘
#fi
#if [ ! -d "${ZOOKEEPER_HOME}" ]; then
# echo "Warning: $ZOOKEEPER_HOME does not exist! Accumulo imports will fail."
# echo ‘Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation.‘
#fi
再次使用 sqoop 就没有相关警告了,可以通过 sqoop help 查看相关导入导出命令
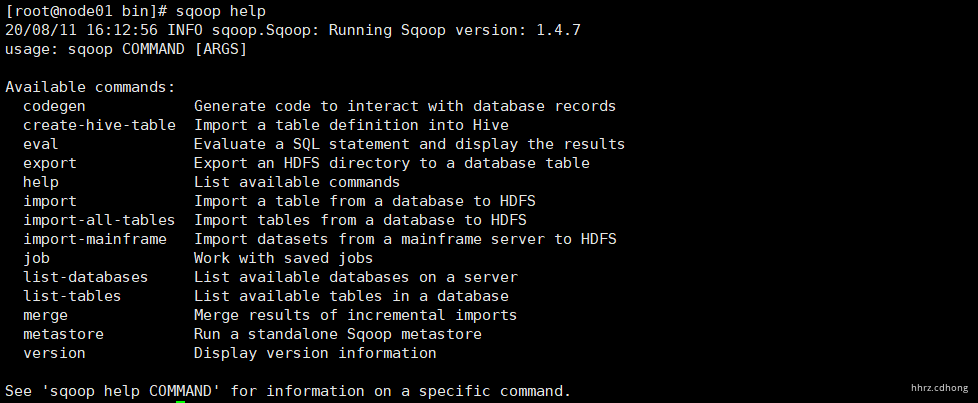
| 命令 | 说明 |
|---|---|
create-hive-table |
生成与关系数据库表的表结构对应的HIVE表 |
**export** |
从hdfs中导数据到关系数据库中 |
**import** |
将数据库表的数据导入到HDFS中 |
import-all-tables |
将数据库中所有的表的数据导入到HDFS中 |
list-databases |
打印出关系数据库所有的数据库名 |
list-tables |
打印出关系数据库某一数据库的所有表名 |
version |
显示sqoop版本信息 |
通过 sqoop help 命令可以查看使用 对应命令 list-databases 来完成对应功能,并确定需要那些参数。
[root@node01 ~]# sqoop help list-databases;
使用 Sqoop 获取指定 URL 下的所有数据库
[root@node01 bin]# sqoop list-databases --connect jdbc:mysql://node01:3306?useSSL=false --username root --password root
20/09/06 14:12:36 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7
20/09/06 14:12:36 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead.
20/09/06 14:12:37 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.
information_schema
hive
mysql
performance_schema
sys
Sqoop 提供了多种工具以完成数据迁移,常用的工具包括 sqoop-import、sqoop-export。
在 MySQL 中新建一个sqoop_db 数据库,并创建两张表 emp 和 dept。
CREATE DATABASE sqoop_db;
USE sqoop_db;
DROP TABLE IF EXISTS `dept`;
CREATE TABLE `dept` (
`DEPTNO` int(2) NOT NULL,
`DNAME` varchar(14) DEFAULT NULL,
`LOC` varchar(13) DEFAULT NULL,
PRIMARY KEY (`DEPTNO`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of dept
-- ----------------------------
INSERT INTO `dept` VALUES (‘10‘, ‘ACCOUNTING‘, ‘NEW YORK‘);
INSERT INTO `dept` VALUES (‘20‘, ‘RESEARCH‘, ‘DALLAS‘);
INSERT INTO `dept` VALUES (‘30‘, ‘SALES‘, ‘CHICAGO‘);
INSERT INTO `dept` VALUES (‘40‘, ‘OPERATIONS‘, ‘BOSTON‘);
-- ----------------------------
-- Table structure for `emp`
-- ----------------------------
DROP TABLE IF EXISTS `emp`;
CREATE TABLE `emp` (
`EMPNO` int(4) NOT NULL,
`ENAME` varchar(10) DEFAULT NULL,
`JOB` varchar(9) DEFAULT NULL,
`MGR` int(4) DEFAULT NULL,
`HIREDATE` date DEFAULT NULL,
`SAL` int(7) DEFAULT NULL,
`COMM` int(7) DEFAULT NULL,
`DEPTNO` int(2) DEFAULT NULL,
PRIMARY KEY (`EMPNO`),
KEY `FK_DEPTNO` (`DEPTNO`),
CONSTRAINT `FK_DEPTNO` FOREIGN KEY (`DEPTNO`) REFERENCES `dept` (`DEPTNO`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of emp
-- ----------------------------
INSERT INTO `emp` VALUES (‘7369‘, ‘SMITH‘, ‘CLERK‘, ‘7902‘, ‘1980-12-17‘, ‘800‘, null, ‘20‘);
INSERT INTO `emp` VALUES (‘7499‘, ‘ALLEN‘, ‘SALESMAN‘, ‘7698‘, ‘1981-02-20‘, ‘1600‘, ‘300‘, ‘30‘);
INSERT INTO `emp` VALUES (‘7521‘, ‘WARD‘, ‘SALESMAN‘, ‘7698‘, ‘1981-02-22‘, ‘1250‘, ‘500‘, ‘30‘);
INSERT INTO `emp` VALUES (‘7566‘, ‘JONES‘, ‘MANAGER‘, ‘7839‘, ‘1981-04-02‘, ‘2975‘, null, ‘20‘);
INSERT INTO `emp` VALUES (‘7654‘, ‘MARTIN‘, ‘SALESMAN‘, ‘7698‘, ‘1981-09-28‘, ‘1250‘, ‘1400‘, ‘30‘);
INSERT INTO `emp` VALUES (‘7698‘, ‘BLAKE‘, ‘MANAGER‘, ‘7839‘, ‘1981-05-01‘, ‘2850‘, null, ‘30‘);
INSERT INTO `emp` VALUES (‘7782‘, ‘CLARK‘, ‘MANAGER‘, ‘7839‘, ‘1981-06-09‘, ‘2450‘, null, ‘10‘);
INSERT INTO `emp` VALUES (‘7788‘, ‘SCOTT‘, ‘ANALYST‘, ‘7566‘, ‘1987-04-19‘, ‘3000‘, null, ‘20‘);
INSERT INTO `emp` VALUES (‘7839‘, ‘KING‘, ‘PRESIDENT‘, null, ‘1981-11-17‘, ‘5000‘, null, ‘10‘);
INSERT INTO `emp` VALUES (‘7844‘, ‘TURNER‘, ‘SALESMAN‘,‘7698‘, ‘1981-09-08‘, ‘1500‘, ‘0‘, ‘30‘);
INSERT INTO `emp` VALUES (‘7876‘, ‘ADAMS‘, ‘CLERK‘, ‘7788‘, ‘1987-05-23‘, ‘1100‘, null, ‘20‘);
INSERT INTO `emp` VALUES (‘7900‘, ‘JAMES‘, ‘CLERK‘, ‘7698‘, ‘1981-12-03‘, ‘950‘, null, ‘30‘);
INSERT INTO `emp` VALUES (‘7902‘, ‘FORD‘, ‘ANALYST‘, ‘7566‘, ‘1981-12-03‘, ‘3000‘, null, ‘20‘);
INSERT INTO `emp` VALUES (‘7934‘, ‘MILLER‘, ‘CLERK‘, ‘7782‘, ‘1982-01-23‘, ‘1300‘, null, ‘10‘);
sqoop-import 语法和相关参数import 工具提供(从 RDBMS 到 HDFS) 导入单个表的功能,表的每一行都在 HDFS 中对应一条单独的记录,距离可以存储为文本、Avro 或 SequenceFile 格式。
$ sqoop import [generic-args] [import-args]
sqoop-import 参数包括通用参数、导入控制参数、输出格式控制参数、Hive参数。 可以使用 help 查询 导入命令相关参数。
[root@node01 ~]# sqoop help import
通用参数 --connect <jdbc-url> : 指定JDBC连接串 --username <username> : 用户名 --password <password> : 密码 --password-file: 包含密码的文件
导入控制参数 --append :追加数据至已存在的HDFS数据集 --columns<col,col,col…> :指定导入的列 -e,--query<statement> :执行SQL语句,查询结果将被导入 --table<table-name> :读取的表名 --target-dir<dir> :将导入的HDFS目录,用于单表路径指定
--warehouse-dir :将导入的HDFS目录,用于多表路径指定
--where<where express> :条件过滤
--delete-target-dir :如果目录存在则删除目录
-m,--num-mappers :导入时并行map任务数量
-z,--compress :启用压缩
--mapreduce-job-name<name> :作业名称
输入格式控制参数 --input-enclosed-by<char> :设置输入字符包围符 --input-escaped-by<char> :设置输入转义符 --input-fields-terminated-by<char> :设置输入字段分隔符 --input-lines-terminated-by<char> :设置输入行分隔符
输出格式控制参数 --fields-terminated-by<char> :设置字段分隔符 --lines-terminated-by<char> :设置行分隔符
Hive 参数 --create-hive-table :自动创建Hive表 --hive-database<database-name> :设置Hive数据库名 --hive-import :导入RDBMS表至Hive --hive-overwrite :如果数据存在则覆盖 --hive-partition-key :分区键 --hive-partition-value :分区值 --hive-table<table-name> :指定导入Hive的表
[root@node01 bin]# sqoop import --connect jdbc:mysql://node01:3306/sqoop_db?useSSL=false --username root --password root --table emp --target-dir /sqoop/import/emp --delete-target-dir -m 1
--table:指定要操作的数据表。
-m:指定导入数据的并行度,sqoop 默认并行度是4,此处我们设置为1,在HDFS 上最终输出的文件个数就是并行度的个数。
--target-dir:指定导入的 HDFS 地址,如果不指定,默认的路径是 /usr/用户名/表名。
--delete-target-dir :如果导出的目录已存在则删除目录 ,防止HDFS 报错。
sqoop 默认从关系型数据库中导入数据到
HDFS的分隔符是逗号。
在 HDFS Web 端查看
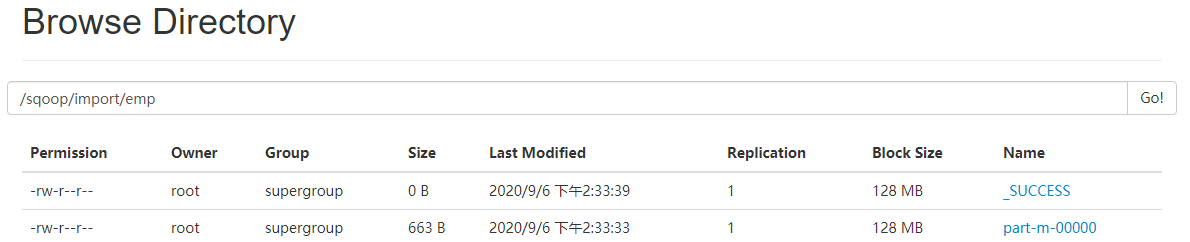
使用 HDFS 命令查询具体信息** **
[root@node01 bin]# hadoop fs -text /sqoop/import/emp/part* 7369,SMITH,CLERK,7902,1980-12-17,800,null,20 7499,ALLEN,SALESMAN,7698,1981-02-20,1600,300,30 7521,WARD,SALESMAN,7698,1981-02-22,1250,500,30 7566,JONES,MANAGER,7839,1981-04-02,2975,null,20 7654,MARTIN,SALESMAN,7698,1981-09-28,1250,1400,30 7698,BLAKE,MANAGER,7839,1981-05-01,2850,null,30 7782,CLARK,MANAGER,7839,1981-06-09,2450,null,10 7788,SCOTT,ANALYST,7566,1987-04-19,3000,null,20 7839,KING,PRESIDENT,null,1981-11-17,5000,null,10 7844,TURNER,SALESMAN,7698,1981-09-08,1500,0,30 7876,ADAMS,CLERK,7788,1987-05-23,1100,null,20 7900,JAMES,CLERK,7698,1981-12-03,950,null,30 7902,FORD,ANALYST,7566,1981-12-03,3000,null,20 7934,MILLER,CLERK,7782,1982-01-23,1300,null,10
将 MySQL数据导入到 Hive 的执行原理:先将 MySQL数据导入到HDFS 上,然后再使用 load 函数将 HDFS 的文件加载到 Hive 表中。
注意:需要再 Sqoop\lib 包下加入 Hive 的相关组件包
# Caused by: java.lang.ClassNotFoundException: org.apache.hadoop.hive.conf.HiveConf 把 hive 下的组件包拷贝到 sqoop 的lib 依赖包下 [root@node01 lib]# cp hive-common-2.3.3.jar hive-exec-2.3.3.jar /usr/local/sqoop/lib/ [root@node01 sqoop_data]# sqoop import --connect jdbc:mysql://node01:3306/sqoop_db?useSSL=false --username root --password root --table emp --delete-target-dir -m 1 --hive-import --create-hive-table --hive-database wise_db --hive-table sqoop_emp 20/09/06 14:39:44 INFO hive.HiveImport: Loading data to table wise_db.sqoop_emp 20/09/06 14:39:46 INFO hive.HiveImport: Table wise_db.sqoop_emp stats: [numFiles=1, totalSize=663] 20/09/06 14:39:46 INFO hive.HiveImport: OK 20/09/06 14:39:46 INFO hive.HiveImport: Time taken: 2.517 seconds 20/09/06 14:39:47 INFO hive.HiveImport: Hive import complete. 20/09/06 14:39:47 INFO hive.HiveImport: Export directory is contains the _SUCCESS file only, removing the directory.
--hive-import :表示将数据导入到 Hive 中。
--create-hive-table:表示是否自动创建 hive 表。
--hive-database :指定导入的 Hive 数据库。
--hive-table :指定要导入的 Hive 表名称。
[root@node01 lib]# hive hive (default)> use wise_db; hive (wise_db)> show tables; hive (wise_db)> select * from sqoop_emp; OK 7369 SMITH CLERK 7902 1980-12-17 800 NULL 20 7499 ALLEN SALESMAN 7698 1981-02-20 1600 300 30 7521 WARD SALESMAN 7698 1981-02-22 1250 500 30 7566 JONES MANAGER 7839 1981-04-02 2975 NULL 20 7654 MARTIN SALESMAN 7698 1981-09-28 1250 1400 30 7698 BLAKE MANAGER 7839 1981-05-01 2850 NULL 30 7782 CLARK MANAGER 7839 1981-06-09 2450 NULL 10 7788 SCOTT ANALYST 7566 1987-04-19 3000 NULL 20 7839 KING PRESIDENT NULL 1981-11-17 5000 NULL 10 7844 TURNER SALESMAN 7698 1981-09-08 1500 0 30 7876 ADAMS CLERK 7788 1987-05-23 1100 NULL 20 7900 JAMES CLERK 7698 1981-12-03 950 NULL 30 7902 FORD ANALYST 7566 1981-12-03 3000 NULL 20 7934 MILLER CLERK 7782 1982-01-23 1300 NULL 10 Time taken: 2.881 seconds, Fetched: 14 row(s)
导出 HDFS 数据到 MySQL 上,在导出数据 (表) 前需要先创建待导出表的结构,如果待导出的表在数据库中不存在,则报错;如果重复导出表,则表中的数据会重复。
使用 sqoop 导出操作,开发人员可以通过 sqoop 的 help 命令查看该操作应如何使用。
通用参数
--connect <jdbc-uri> :指定 JDBC 连接串
--password <password> :密码
--username <username> :用户名
导出控制参数
--batch :使用批处理模式执行基础语句
--columns <col,col,col...> :指定列名,注意需要与 HDFS 中数据的列数与类型匹配
--direct :使用直接导出快速路径
--export-dir <dir> :指定HDFS上的文件路径。注意:每运行一次上述代码,就会重新插入数据到MySQL中。
-m,--num-mappers <n> :导出时并行map任务数量
--table <table-name``> :指定要导入到RDBMS上的哪个表
输入文件参数配置
--input-fields-terminated-by <char> :设置输入字段分隔符
--input-lines-terminated-by <char>:设置输入行分隔符
输出文件参数配置
--fields-terminated-by <char> :设置字段分隔符
--lines-terminated-by <char> :设置行分隔符
由上述代码可以发现,这些参数大部分与 import 参数类似,它们的不同之处将通过下面的示例进行说明。
在 MySQL 数据库中创建要导出的表,并直接根据 emp 表 创建导出表的结构。
mysql> use sqoop_db; mysql> create table emp2 as select * from emp where 1=2; mysql> select * from emp2; Empty set (0.00 sec)
导出 HDFS 中 /sqoop/import/emp 中的数据至 MySQL。
[root@node01 ~]# sqoop export --connect jdbc:mysql://node01:3306/sqoop_db?useSSL=false --username root --password root --table emp2 --fields-terminated-by ‘,‘ --lines-terminated-by ‘\n‘ --export-dir /sqoop/import/emp/ -m 1
--fields-terminated-by 与 --lines-terminated-by 参数指定数据行和列的分隔符。
--export-dir :指出将要导出的 HDFS 数据目录。注意:每运行一次上述代码,数据就会追加一次到数据库中。
mysql> select * from emp2; +-------+--------+-----------+------+------------+------+------+--------+ | EMPNO | ENAME | JOB | MGR | hiredate | SAL | COMM | DEPTNO | +-------+--------+-----------+------+------------+------+------+--------+ | 7369 | SMITH | CLERK | 7902 | 1980-12-17 | 800 | NULL | 20 | | 7499 | ALLEN | SALESMAN | 7698 | 1981-02-20 | 1600 | 300 | 30 | | 7521 | WARD | SALESMAN | 7698 | 1981-02-22 | 1250 | 500 | 30 | | 7566 | JONES | MANAGER | 7839 | 1981-04-02 | 2975 | NULL | 20 | | 7654 | MARTIN | SALESMAN | 7698 | 1981-09-28 | 1250 | 1400 | 30 | | 7698 | BLAKE | MANAGER | 7839 | 1981-05-01 | 2850 | NULL | 30 | | 7782 | CLARK | MANAGER | 7839 | 1981-06-09 | 2450 | NULL | 10 | | 7788 | SCOTT | ANALYST | 7566 | 1987-04-19 | 3000 | NULL | 20 | | 7839 | KING | PRESIDENT | NULL | 1981-11-17 | 5000 | NULL | 10 | | 7844 | TURNER | SALESMAN | 7698 | 1981-09-08 | 1500 | 0 | 30 | | 7876 | ADAMS | CLERK | 7788 | 1987-05-23 | 1100 | NULL | 20 | | 7900 | JAMES | CLERK | 7698 | 1981-12-03 | 950 | NULL | 30 | | 7902 | FORD | ANALYST | 7566 | 1981-12-03 | 3000 | NULL | 20 | | 7934 | MILLER | CLERK | 7782 | 1982-01-23 | 1300 | NULL | 10 | +-------+--------+-----------+------+------------+------+------+--------+ 14 rows in set (0.16 sec)
标签:pil 控制 启动 zook water expand temp 部分 opera
原文地址:https://www.cnblogs.com/shijingwen/p/13682031.html