标签:政府 运行 其他 时间 结果 一点 微信 问题: img
https://mp.weixin.qq.com/s/_vqx4EXeAZ39AHAh-moGegBy 超神经
OpenAI 在发布 GPT-2 之前,估计想象不到,自己的开源行为给学界、工业界引起了轩然大波,当然这与他们的研究成果大,科研水平高也有着很大关系。
作为普通开发者,开源到底会有哪些风险和好处?本文罗列了几个开源前需要考虑的问题,以及部分作者的经验之谈。OpenAI 上周介绍了 NLP 领域内最先进的文本生成模型 GPT-2,但他们最终决定不公开全部的数据,对此给出的说法是:
「由于担心该技术被恶意应用,我们不会发布经过培训的模型。」
从 OpenAI 发布 GPT-2 ,到宣布只开源部分成果的这段时间里,引起了巨大的争议。有观点认为如果全部开源,一定会有恶意使用,甚至引发犯罪;而支持公开的言论认为不公开全部数据,会其他的科研人员对成果复现困难。
Anima Anankumar 致力于机器学习理论和应用的协调发展。 她在推特上对 OpenAI 决定发布模型的回应是:
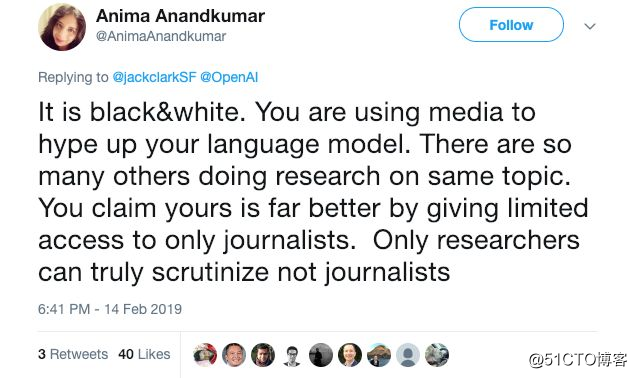
这就是一个非黑即白的问题。你们在利用媒体炒作语言模型。关于这个话题的研究有很多。你们声称研究结果效果惊人却只让记者了解个中详情。应该有知情权的是研究人员而不是记者。
Stephen Merity 对社交媒体的回应进行了总结,他感叹机器学习社区在这方面的经验不多:
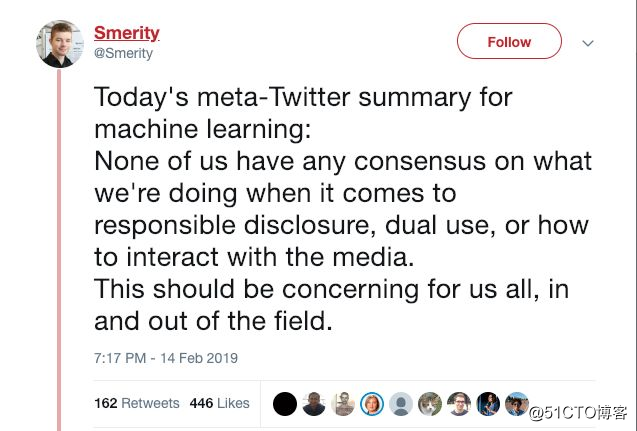
今日总结(关于 OpenAI ):在负责任的披露,双重使用或如何与媒体互动方面,我们都没有对这件事情达成任何共识。这应该是和我们每个人(无论领域内外)都息息相关的事情。
开源这个事情,相信很多人都已经从中收益。那么牵涉到我们作为独立工程师或依附于公司或机构的工程师,我们自己的模型要不要开源呢?
有人总结了一份指南,可以在你踌躇不定时,引导你往前一步去思考。
Q
是否要去考虑开源自己的模型?
当然是要!
无论最终结果如何,思考一下模型开源的可能性,不要完全回避开源。 不过,如果你的模型涉及到私密数据,一定要考虑到不法分子,可能通过反编译获取原数据的风险。
Q
如果模型全部来自公开数据集,我需要担心什么问题?
即使都来自于公开数据集,但是与其他人研究方向和目的的不同,可能会带来新的影响。
因此,需要问一个问题:即使只使用公开数据集,但不同的研究方向是否会对数据或模型会造成什么影响?
比如在阿拉伯之春期间,有些地区因为动乱导致经常封路,当地年轻人就在 Twitter 上吐槽,而有关组织,就利用监控 Twitter 上的用户的内容来分析敌对方的军事路线。
单条数据看起来可能没什么用,但一旦数据被组合起来,就有可能产生许多敏感的结果。
所以,要去考虑这个问题:模型中的数据合并起来,是否会比单个数据点更加敏感?

Q
如何评估开源后的风险?
从安全性去考虑,权衡「不开源」和「开源却被滥用」所造成的影响,哪一个更严重。 ?
要将每个策略视为「可更改的梗安全措施的成本,可能高于被保护的数据价值。比如有些信息涉及私密,但有时效性作为前提,一旦过了时效,信息就不再私密,但却依然有极大的研究价值。
因此,对于不好的安全策略也要及时舍弃,高效地识别和维护数据集价值。
此外,衡量一下模型使用的复杂程度,和坏人拿来利用的门槛来比,哪个更容易?确认过这个影响,再去决定是否开源。
在 OpenAI 的案例中,他们可能认为不开放全部模型,就足以阻止互联网上的恶意使用。
但要承认,对于不少业内人士来说,即使开放了全部模型,都不一定能复现得出论文,有心恶意利用的人也需要很大的成本。
Q
我应该相信媒体们所描述的开源的风险吗?
不。
媒体的描述总是会引导舆论,记者们想要更高的阅读量,耸人听闻的标题和观点会更吸引人。记者们可能倾向于开源,因为这样他们更容易报道,另一方面,不开源的决定可能导致怂人听闻的谣言(与 OpenAI 案例一样,开不开源都会被媒体记者们各种夸大其词)。
Q
应该相信有关部门对开源风险的意见吗?
显然也是不。
当然首先要自己确保研究是合法合理的,那些政府机构的工作人员也可能并不专业,他们可能更关心舆论的压力,正所谓「没有事,就是好事」,所以他们的观点也不是判断是否开源的关键。
不过也要像记者一样,既将政府视为重要的合作伙伴,同时也意识到彼此有不同的诉求。 
Q
应该思考应对开源后负面用例的解决方案吗?
是的!
这是 OpenAI 此次没做好的地方。如果模型能被用来创建假新闻,那么假新闻也可能被进一步的检测出来。比如创建一个文本分类任务,去更准确地区分是人类写的和 OpenAI 模型的输出。
Facebook 、微信和各类媒体网站,一直在打击假新闻和谣言上付出了很多努力, OpenAI 的这项研究明显是能提供帮助的,是否能以相关的方式检测这种模型输出,从而去对抗假新闻?
按理说,OpenAI 能在短时间内出个解决方案的,但他们没有。
Q
是否应该去注意平衡模型的负面案例和正面用例?
是。
通过发布具有积极应用的模型,比如医疗、安防、环保,很容易对社会运行的各个环节都产生贡献。
OpenAI 的另一个失败之初在于,他们的研究缺乏多样性。OpenAI 发布了的研究仅适用于英语和少数其他语言。但英语仅占全世界对话的 5% 。对于句子中的单词顺序,标准化拼写以及「单词」如何用作机器学习功能的原子单位,英语的情况可能不适用于其他语言。
OpenAI 作为科研领域的先驱,也有责任尝试其他语言类型的研究, 帮助更需要帮助的语言和地区。
Q
开源模型之前,数据要脱敏到什么程度?
建议脱敏到字段级别,最起码从字段级别开始评估。
比如我在 AWS 工作时负责的刚好是:命名实体识别服务,我就必须要考虑到:是否要将街道级地址识别为显式字段,以及是否将具体坐标映射到该地址。
这从本质上都是非常敏感的私人信息,尤其在被商业公司产品化的时候,应该考虑到。所以,在任何研究项目中都要考虑这一点:是否已经将关键数据进行脱敏?
Q
当别人都说可以开源时,我应该开源我的模型吗?
不,你应该有自己的判断力。
无论你是否同意 OpenAI 的决定,他们都是自己做出最后的决定,而不是盲目地听从网友的意见。 
增量学习 Incremental learning
增量学习是指当新增数据时,只做关于新数据引起的学习更新。增量学习能不断地从新样本中学习新的知识, 并能保存大部分以前已经学习到的知识。
它类似于人类的学习模式,是一个逐渐积累和更新过程。
传统的学习方式批量模式,是准备好所有数据,应对随时更新的数据,需要重新训练和学习,增量学习解决了这一弊端,是一种得到广泛应用的智能化数据挖掘和知识发现技术。

标签:政府 运行 其他 时间 结果 一点 微信 问题: img
原文地址:https://blog.51cto.com/14929242/2535596