标签:顺序 网站 选项 其它 独立 计算机 eric mon tps
https://mp.weixin.qq.com/s/uiP_s6ZWlAimWGfJuUQ32Q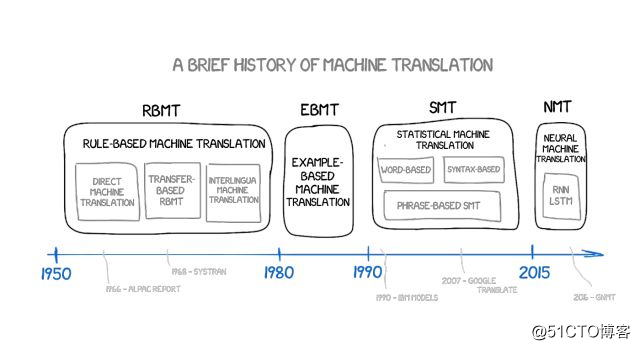
在1990年初,在IBM研究中心,一个机器翻译系统首次被展示,它对规则和语言学一无所知。它用两种语言分析了下图中的文本,并试图理解这些模式。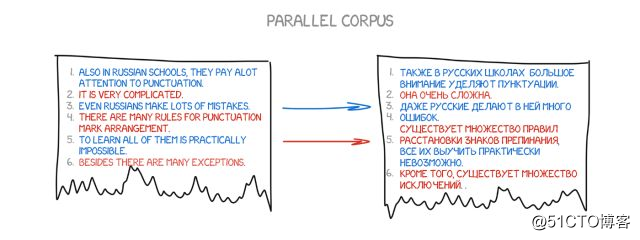
这个想法简单而美丽。在两种语言中,一个相同的句子被分成好几个词,之后再重新组合。这个操作大约重复了5亿次,例如,「Das Haus」一词被翻译成「house」vs「building」vs「construction」等等。
如果大多数时候源词(以「Das Haus」为例)被翻译成「house」,机器就会默认这个含义。注意,我们没有设置任何规则,也没有使用任何字典——所有的结论都是由机器完成,由数据和逻辑指导。翻译时机器仿佛在说:「如果人们这样翻译,我也会这样做」,于是,统计机器翻译诞生。
它的优点在于更有效、更准确,而且不需要语言学家。我们使用的文本越多,我们得到的翻译就越好。
(来自谷歌内部的统计翻译:它不仅显示该含义的使用概率,还进行了其它含义的统计)
还有一个问题:
机器如何把「Das Haus」和「building」这个词联系起来——我们怎么知道这些是正确的翻译呢?
答案是我们不知道。
一开始,机器假定「Das Haus」一词与翻译的句子中的任何单词都有同样的关联,接下来,当「Das Haus」出现在其他句子中时,与「house」的相关性会增加。这就是「单词对齐算法」,这是校级机器学习的一个典型任务。
这台机器需要两种语言的数百万个句子,来收集每个单词的相关统计信息,那如何获取这些语言信息的呢?我们决定采取欧洲议会和联合国安全理事会的会议摘要——这些摘要均以所有成员国的语言呈现,能给素材搜集节省大量时间。
在一开始,第一个统计翻译系统将句子分成单词,因为这个方法是直截了当和合乎逻辑的,IBM的第一个统计翻译模型称为「模型1」。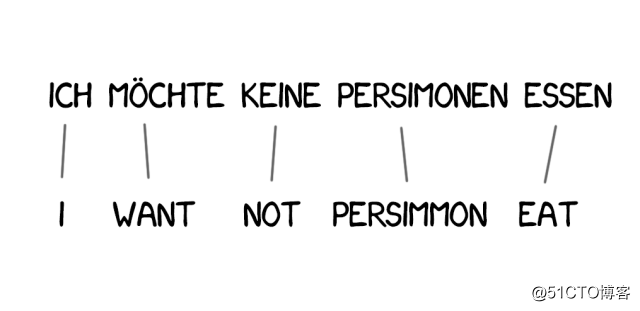
模型1:一篮子单词
模型1使用了经典的方法——分裂成单词和计数统计,但没有考虑词序,唯一的诀窍就是把一个单词翻译成多个单词。例如,「Der Staubsauger」可以变成「吸尘器」,但这并不意味着它会变成「真空吸尘器」。
模型2:考虑句子中的单词顺序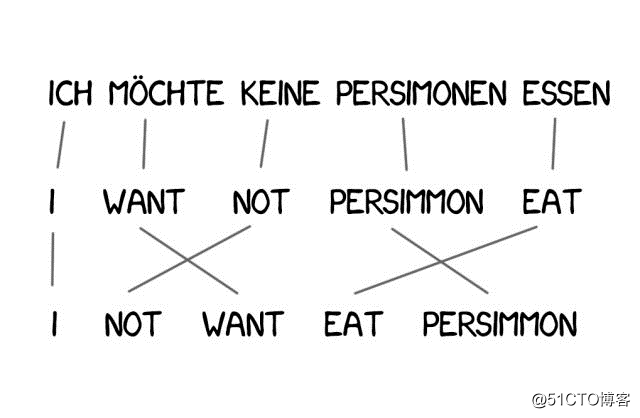
文字排列顺序的缺乏是模型 1 的主要局限,而这些在翻译过程中是非常重要的。模型 2 的出现解决了这个问题:记忆单词在输出句子中的通常位置,并在中间步骤中重新洗牌,以便翻译的更加自然。
那么,情况变好了吗?并没有。
模型3:加入新词

翻译中经常需要增加新词以完善语义,比如德文要用英文否定的时候用「do」。德文“「Ich will keine Persimonen”」翻译成英文为 「I do not want Persimmons」 。
为了解决这个问题,模型3中又在前面基础上添加了两个步骤:
模型4:词对齐
模型2 考虑了单词对齐,但对重新排序一无所知。例如,形容词通常会与名词交换位置,不管顺序如何被记住,如果不加入语法因子,很难获得精妙的翻译。因此,模型4考虑到这个「相对秩序」——如果两个词总是互换位置,模型就会知道。
模型5:修正错误
模型5 获得了更多的学习参数,并解决了单词位置冲突的问题。尽管它们具有革命意义,但基于文字的系统仍然无法处理同音异义的情况,即每个单词都以一种单一的方式被翻译出来。
不过,这些系统已不再被使用,因为它们被更高级的基于短语的翻译所取代。
该方法基于所有基于单词的翻译原则:统计、重新排序和词汇技巧。它不仅将文本分割成单词,还将其分割成短语,精确地说,这是连续的多个单词序列。
因此,机器学会了翻译稳定的词语组合,这明显提高了准确性。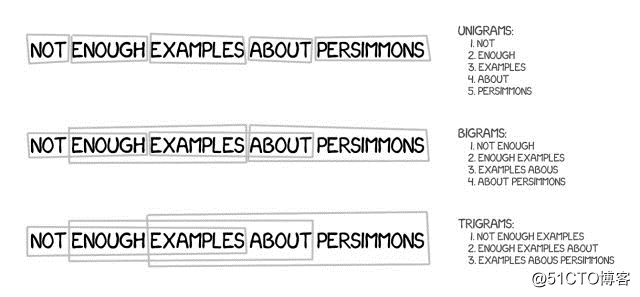
关键在于,这些短语并不总是简单的句法结构,如果有人意识到语言学和句子结构的干扰,那么翻译的质量就会显著下降。计算机语言学的先驱弗雷德里克·耶利内克(Frederick Jelinek)曾经开玩笑说过:「每次我向语言学家发起***时,语音识别器的性能就会提高。」
除了提高精确性之外,基于短语的翻译提供了更多双语文本的选项。对于基于文字的翻译,来源的精确匹配是至关重要的,因此,它很难在文学或自由翻译上贡献价值。
而基于短语的翻译没有这个问题,为了提高机器翻译水平,研究人员甚至开始用不同的语言来解析新闻网站。
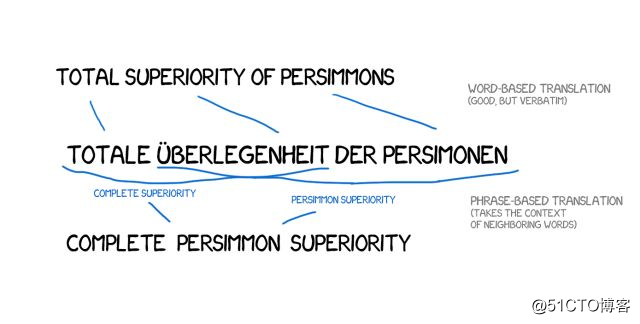
从 2006 年开始,大家几乎都在使用这种方法。谷歌翻译、Yandex、Bing 等其他一些知名的在线翻译系统在2016年之前都是基于短语的。因此,这些翻译系统翻译的结果要么完美无暇,要么毫无意义,没错,这就是短语翻译的特点。
这种基于规则的老方法总是能得出有失偏颇的结果,谷歌毫不犹豫将「three hundred」翻译成「300」,但实际上「three hundred」也有「300年」的含义,这就是统计翻译机器普遍存在的局限。
在2016年以前,几乎所有的研究都认为基于短语的翻译是最先进的,甚至将“统计机器翻译”和“基于短语的翻译”等同看待,而人意识到谷歌将掀起对整个机器翻译的革命。
这个方法也应该简短地提到。在神经网络出现之前的许多年,基于语法的翻译被认为是「未来」,但这个想法并没有成功。
它的支持者们认为可以将它与基于规则的方法合并。可以对句子进行精确的语法分析——确定主语、谓语和句子的其他部分,然后构建句子树。通过使用它,机器学习转换语言之间的句法单元,并通过单词或短语来进行翻译。这就能彻底解决“翻译误差”这个问题。
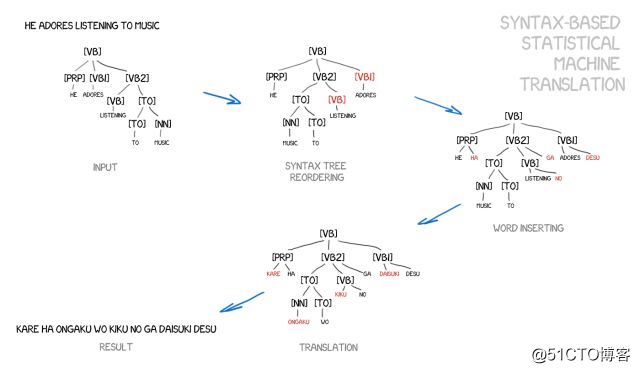
想法很美好,但现实很骨感,语法分析工作得非常糟糕,即便它的语法库问题此前已经解决了(因为我们已经有了许多现成的语言库)。
2014 年出现了一篇关于神经网络机器翻译的有趣论文,但并没有引起广泛关注,只有谷歌开始深入挖掘这一领域。两年后的 2016 年 11 月,谷歌高调宣布:机器翻译的游戏规则正式被我们改变。
这个想法跟 Prisma 中模仿著名艺术家作品风格的功能类似。在 Prisma中,神经网络被教导识别艺术家的作品风格,并由此得到的程式化图像,比如让一张照片看起来像梵高的作品。这虽然是网络的幻象,但我们认为它很美。

如果我们可以将样式转移到照片上,如果我们试图将另一种语言强加给源文本会怎样?文本将是精确的“艺术家的风格”,我们将试图在保留图像的本质的同时将其转移(换句话说,就是文本的本质)。
想像一下,如果把这种神经网络应用到翻译系统中会发生什么呢?
现在,假设源文本是特定特征的集合,这意味着你需要对它进行编码,然后让另一个神经网络用只有解码器知道的语言,将它解码回文本。它不知道这些特征的来源,但可以用西班牙语来表达。
这将是一个十分有趣的过程,一个神经网络只能将句子编码到特定的特征集合,而另一个只能将它们解码回文本。两个人都不知道对方是谁,他们每个人都只知道自己的语言,彼此陌生却能协调一致。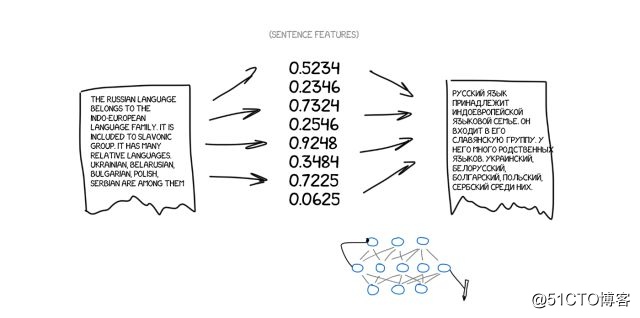
不过,这里面也存在一个问题,那就是如何找到并界定这些特征。当我们讨论狗的时候,它的特征很明显,但对于文本呢?要知道,30 年前,科学家们就已经尝试创建通用语言代码,但最终以失败告终。
然而,我们现在有了深度学习,可以很好的解决这个问题,因为它就是为此而存在。深度学习和经典神经网络之间的主要区别在于,它精确地定位了搜索这些特定特征的能力,而不考虑它们的本质。如果神经网络足够大,并且有成千上万的视频卡供它研究,就能在文本中归纳出这些特征。
从理论上讲,我们可以把从神经网络中获得的特征传递给语言学家,这样他们就可以为自己打开全新的视野。
有一个问题,什么类型的神经网络能被应用于文字的编码和解码呢?
我们知道,卷积神经网络 (CNN) 目前仅适用于基于独立像素块的图片,但文本中没有独立的块,且每个单词都依赖于它周围的环境,就像语言和音乐一样。递归神经网络 (RNN) 将提供一个最佳选择,因为它们记住了之前所有的结果——在我们的例子中是之前的单词。
而且递归神经网络如今已经得到应用,比如 iPhone 的 RNN-Siri 语音识别(它解析声音的顺序,下一个依赖于前一个),键盘的提示(记住前一个,猜测下一个),音乐产生,甚至聊天机器人。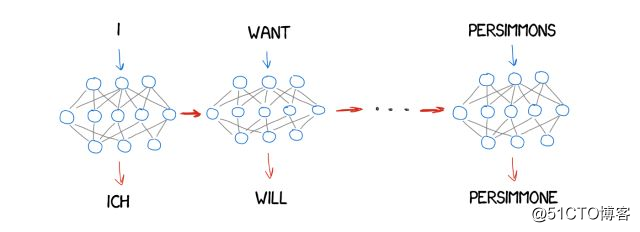
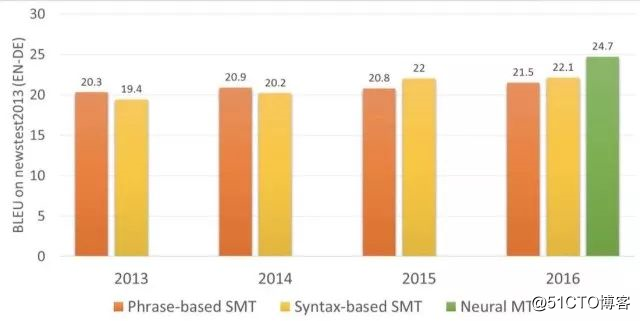
在两年的时间里,神经网络完全超越了过去 20 年的翻译。它使单词顺序错误减少了 50%、词汇错误减少了 17 %、语法错误减少了 19%。神经网络甚至学会用不同的语言来处理类似同音异意的问题。
值得注意的是,神经网络能够实现真正意义上的直接翻译,彻底扔掉词典。在进行两种非英文翻译时,不需要将英文作为中间语进行翻译,此前,如果要将俄文翻译成德文,需要先将俄文翻译成英文,在将英文翻译成德文,这样一来就会增加重复翻译的失误率。
2016 年,他们开发了名为谷歌神经机器翻译(GNMT)的系统,用于 9 种语言的翻译。它包括 8 个编码器和 8 个解码器,以及可以用于在线翻译的网络连接。
他们不仅把句子分开,而且还把单词分开,这也是他们如何处理一个罕见单词的做法。当单词不在字典里时,NMT 是没有参考的。比如翻译一个字母组 「Vas3k」,在这种情况下,GMNT 试图将单词拆分为单词块并恢复它们的翻译。
提示:在浏览器中用于网站翻译的谷歌翻译仍然使用旧的基于短语的算法。不知何故,谷歌并没有升级它,与在线版本相比,这些差异是显而易见的。
不过,目前浏览器中用于网站翻译的谷歌翻译使用的仍是基于短语的算法,不知何故,谷歌并没有在这方面升级它,不过这也让我们能够看出于传统翻译模式的区别。
谷歌在网上使用众包机制,人们可以选择他们认为最正确的版本,如果有很多用户喜欢它,谷歌就会一直用这种方式来翻译这个短语,并且用一个特殊的徽章来标记它。这对于日常的短句,如「让我们去看电影吧」或者「我在等你」这样的短句非常有用。
Yandex 在 2017 年推出了神经翻译系统,它采用的是将神经网络跟统计方法相结合的 CatBoost 算法。
这种方法能有效弥补神经网络翻译的短板——对不经常出现的短语容易出现翻译失真,在这种情况下,一个简单的统计翻译就能快速而简单地找到正确的词。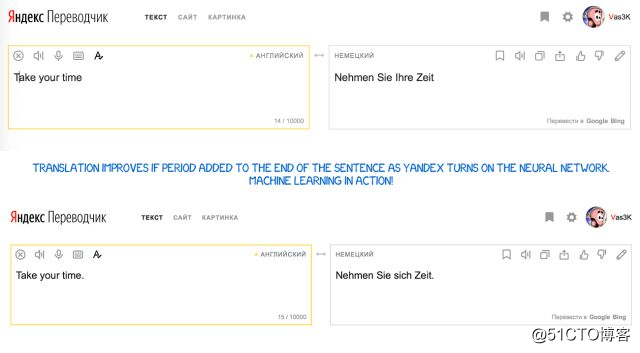
大家现在仍然对「Babel fish」这个概念感到兴奋——即时语音翻译。谷歌已经通过其 Pixel Buds 向它迈进了一步,但事实上,它肯定不完美,因为你需要让它知道什么时候开始翻译,什么时候该闭嘴听。不过这点就连 siri 都做不到。
还有一个待探索的难点:所有的学习都局限于机器学习的语料库。即使能设计再复杂的神经网络,但目前也只能局限在提供的文本中学习。人工翻译可以通过阅读书籍或文章来补充相关语料,以保证翻译结果更加准确,这就是机器翻译大比分落后于人工翻译的部分。
不过既然人工翻译能做到这一点,理论上,神经网络也能做到这一点。而且好像已经有人在尝试用神经网络实现这一功能。也就是通过它知道的一种语言,以另一种语言进行阅读以获得经验,再反哺到自己的翻译系统中备用,让我们拭目以待。

《Statistical Machine Translation》
Philipp Koehn 著
关注公众号 回复「统计机器翻译」下载 PDF 版本

机器翻译都发展60年了,谷歌为什么还把「卡顿」翻译成 Fast (下)
标签:顺序 网站 选项 其它 独立 计算机 eric mon tps
原文地址:https://blog.51cto.com/14929242/2536120