标签:不同类 中断控制器 大量 服务器端 plane 报文 架构 使用 应用软件
交易系统开发(七)——交易延迟分析交易延迟高最常用的指标是往返延时(Round Trip Time),即交易订单从客户策略服务器发至经纪公司交易柜台,交易柜台内部处理后发往交易所,交易所确认报单后发送回报给交易柜台,再从柜台发送至客户策略机的一来一回整体链路的耗时。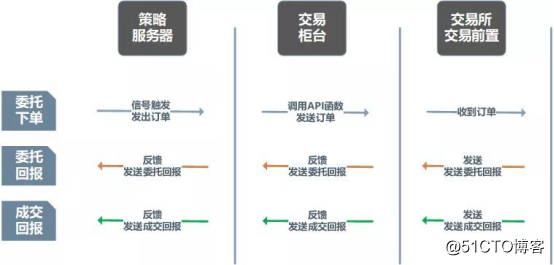
客户策略服务器至经纪公司交易柜台的延时指订单从客户策略服务器网卡发出,至经纪公司柜台服务器网卡收到之间的延时。
本阶段延时主要耗时在硬件上,受服务器、网卡及交换机的性能优劣影响较大。
策略服务器一般由客户自行采购或由客户指定配置由券商采购,柜台服务器一般由经纪公司提供,高频交易服务器一般托管在机房,布线一般由经纪公司网络工程师完成,本段延迟主要由经纪公司和客户共同决定。
交易柜台内部延迟指交易柜台网卡收到策略客户端发出的委托订单,经过前置、风控、订单、报盘等模块管理后,再调用交易所API从网卡发出所需要的耗时。
本段延时由经纪公司柜台系统,系统服务器、网卡及交易所API三部分决定。
第一部分即经纪公司柜台系统,高频交易柜台系统由专业柜台厂商提供。交易柜台系统一般有交易前置模块(提供监听及客户链接管理功能)、风控模块(对客户订单的风控管理)、订单管理模块(管理客户订单)、报盘模块(管理与交易所交易前置的链接)。
前置模块的连接处理速度,风控的逻辑计算速度,订单管理内存数据库的设计,报盘的订单快速报出,极其考验柜台厂商的技术水平。
极速交易柜台系统在考虑系统稳定性和吞吐量的同时,充分考虑了系统计算资源消耗及分配的问题,通过高时效性的计算函数,减少运行状态下的内存再分配,避免了计算资源抢占等一系列手段极大地减小了系统内部延迟。
从交易柜台服务器网卡收到策略服务器发出的订单至调用交易所API函数结束,耗时峰值已实现百纳秒级,中位数1~2微秒。
第二部分即系统服务器、网卡的性能,主要由硬件决定,服务器的主频、内存、处理器,网卡的带宽、延时都有很大影响。
通过在服务器及网卡层面的系统进行调优,能最大程度地减小延时。
第三部分即交易所API,主要由交易所技术公司决定,按照中国金融市场的监管规定,各个柜台厂商都需要调用交易所API向交易所报单。
交易所API是由交易所技术公司封装好的发布产品,底层逻辑不可见,优化空间较小。
交易所端延迟指订单从柜台系统调用交易所API从网卡发出订单后,交易所返回委托或成交报文至柜台网卡的整体耗时。
本段延时主要由服务器所在的交易所托管机房优势、市场活跃度(活跃的合约或者抢手的价位报单量大、撮合时间长、排队时间长;非活跃合约或者类似于涨跌停板这样的价位订单,报单量小、撮合时间短、排队时间少)等决定;
交易所API至交易所网络一般由交易所技术公司提供,所以这段延时主要由交易所决定,对所有投资者来说这一段都比较公平,优化空间最小。
量化交易延迟的主要环节如下:
(1)行情和订单信息网络传送延迟
交易所的实时行情数据和订单信息需要通过网络通道连接到程序化量化交易的策略交易服务器上,行情数据转路经最少的时间、深度行情,交易通道采用专用、直连的交易通道进行交易。
行情和交易的延时都要求尽可能最低.,比如为了减少数据延迟,越来越多的经纪商和服务机构要求尽量缩短自己的服务器与证券交易所计算机系统的物理距离。
硬件设备延迟:网络连接方式、交换机、路由器、数据发送优化
(2)策略服务器数据接收、处理的延迟
策略服务器使用高速服务器执行策略的架构,采用服务器多核多进程、多线程方式进行自动化交易、程序化交易、算法交易,为了追求闪电交易,使用超低延迟硬件技术进行高频交易等量化交易方式.
硬件设备延迟:策略服务器硬件(CPU处理速度、网卡、硬盘、内存、存储等)
(3)算法交易策略的延迟
设计交易策略:算法交易的核心是对股票等证券的历史行情数据进行分析,结合交易思想,设计出交易策略。
实现交易策略:交易策略编写成计算机程序,并根据股票的品种等因素确定好交易参数,将交易策略整合到交易系统。
接入行情数据:将交易系统上接行情数据,下连下单接口以报单。实际交易时,让程序根据行情的变化自动选择股票的买卖点。
自动交易:程序根据产生的买卖点来对股票进行买卖操作。
涉及延迟:开发语言、算法策略、数据库。
目前机器学习、深度学习等AI技术已经被广泛用于量化策略中的因子挖掘。
(4)金融新闻信息实时获取延迟
金融市场的信息已被诸如路透、道琼斯、彭博、汤姆逊金融等公司格式化,通过算法的解读来形成交易。
虽然理论上操作系统时钟最小可以与硬件中断处理的时间相等,但通用操作系统的时间管理一般采用粗粒度的周期性时钟中断。对操作系统而言,避免了频繁进行进程上下文切换,但也使调度的时钟延迟在最坏情况下可能等同于时钟的间隔,从而成为延迟产生的最大来源。例如,Linux缺省时钟间隔粒度为10毫秒,因此最坏情况下内核和用户空间应用程序需要使用一个时间间隔来进行调度。对于一个休眠的进程,即便唤醒条件已经触发,也许需要10毫秒的时间才能被调度执行,显然难以满足低延迟应用的要求。
通用操作系统中大量存在的非抢占式处理会对低延迟处理造成影响。即便操作系统已经使用了细粒度的时钟,而且硬件也及时地产生了一个时钟中断,但如果中断被屏蔽或者内核运行在非抢占式代码区,也会造成内核不能及时中断,应用程序依然得不到及时的调度执行,延迟可能会长达50-100毫秒。
线程调度策略也可能造成较大的延迟。即使操作系统使用了细粒度的时钟,并且使用了抢占式方式可以及时中断,但如果优先权不够,仍然无法被立刻被调度执行。实时系统领域对线程调度策略问题进行了较多的研究,其中较好的一类办法是使用按比例的实时调度器,可以按照比例对不同类型的应用线程进行调度,但前提是所有线程都是抢占式的,而且使用粒度更细的时钟。
通用操作系统一般都使用虚拟内存,因此并发执行的程序可以在运行程序时,只将运行需要的部分载入内存,从而允许程序空间的总和可以远大于实际可用的物理内存。对于时分系统来说,虚拟内存不会产生问题。但对于实时系统,页面调度与交换会造成无法容忍的不确定性延迟。
为支持实时、低延迟的应用,一些实时操作系统利用MINIX无任何页面调度与交换的特点,使用基于优先权的调度器替换MINIX操作系统原本基于循环的调度器。适合对时间粒度的要求不太高的应用。
RTLinux系统通过在Linux内核和中断控制器硬件间加上一层轻量级的虚拟机层来虚拟中断控制器和时钟,使得可以将Linux按照抢占式的方式来运行。其中操作系统内核不能直接控制中断控制器,因为虚拟机层使用宏替换了所有开、关中断和中断返回指令,所有的硬件中断均被虚拟机层捕获,然后根据中断状态判断是否需要处理该中断。由于内核比实时应用的运行优先权低,就不会对不被虚拟机捕获的实时中断造成影响。
为支持实时和低延迟的应用,RedHat公司也于2007年底推出了面向实时和高性能消息交换的RedHat MRG。MRG采用了更细粒度时钟、以信号量代替锁、减少非抢占式操作的代码、用线程处理中断、读-拷贝修改等各种技术来支持低延迟处理。根据Redhat在2009年峰会上公布的数据,配置为24GB内存、2.93gxeon四核处理器、Infiniband 4XQDR接口的MRG单机上每秒消息通信量已突破百万级。
在多核处理器成为主流后,利用多核系统并行运行多线程以最大化计算机的处理效率成为研究的热点。在并行系统中,线程被尽可能地分派到不同的核心上执行。对于不希望被其它线程打扰运行的线程,或一些访问特定资源(如内存、I/O)的线程以及一些对无需上锁的运行时资源进行管理的线程,可以利用操作系统线程关联的机制,将线程绑定到特定的处理器,加快程序的运行速度。
kernel bypass(绕过内核)是解决系统网络栈和存储栈性能瓶颈的一种方式,kernel bypass核心思想是内核只用来处理控制流,所有数据流相关操作都在用户态进行处理,从而规避内核的包拷贝、线程调度、系统调用、中断等性能瓶颈,并辅以各种性能调优手段(如:CPU pin、无锁队列),从而达到更高的性能。
DPDK(Data Plane Development Kit)是由Intel发起,主要基于Linux系统运行,用于快速数据包处理的函数库与驱动集合,可以极大提高数据处理性能和吞吐量,提高数据平面应用程序的工作效率。DPDK使用了轮询(polling)而不是中断来处理数据包。在收到数据包时,经DPDK重载的网卡驱动不会通过中断通知CPU,而是直接将数据包存入内存,交付应用层软件通过DPDK提供的接口来直接处理,节省了大量的CPU中断时间和内存拷贝时间。
SPDK(Storage Performance Development Kit)是由Intel发起,用于加速使用NVMe SSD作为后端存储的应用软件加速库,核心是用户态、异步、轮询方式的NVMe驱动。与内核态的NVMe驱动相比,可以大幅度降低延迟,同时提升单CPU核的IOPS。其架构如下: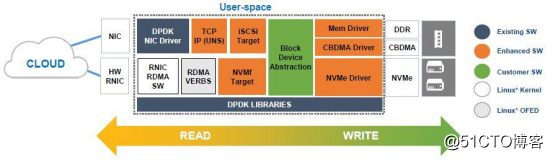
RDMA(Remote Direct Memory Access)全称远程直接数据存取,是为了解决网络传输中服务器端数据处理的延迟而产生的。RDMA通过网络把资料直接传入计算机的存储区,将数据从一个系统快速移动到远程系统存储器中,而不对操作系统造成任何影响,不需要用到多少计算机的处理功能。RDMA消除了外部存储器复制和上下文切换的开销,因而能解放内存带宽和CPU周期用于改进应用系统性能。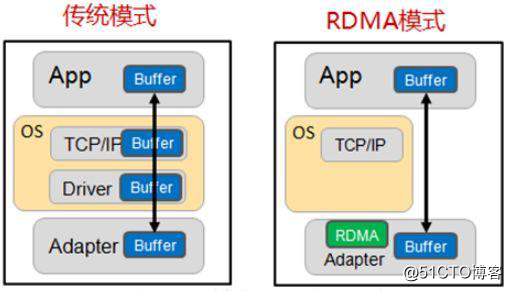
交易系统中的延时是指在一定的背景压力情况下,从接入网关发出指令,后台处理,然后在接入网关收到应答的延时。
延时是一个有实际意义的值,假设一定的背景压力,考虑的是延时的发生实在实际的生产环境中发生的,同时具体到背景压力,可能还会包含实际的业务行为分布,例如订单输入、订单删除、订单修改、订单查询等等。这些业务行为的分布,需要考虑实际生产环境中发生的比例,只有这样整个延时的测试才会比较真实和合理。
延时测试的基点是接入网关,目的是排除广域网物理链路对延时的影响,也是目前国际上发布延时的基准。
低延时意味着交易系统能够在更短的时间上响应客户的请求,那么在交易的关键路径上,必须要能够足够快的传输数据,同时关键路径上的模块必须要能够足够快的处理数据。
要控制和降低延迟,首先要能准确测量延迟,因此需要比较精确的时钟,每个机房需要配几台带GPS或原子钟的NTP服务器。即便使用NTP,同一机房两台机器的时间也会有毫秒级的差异,计算延迟的时候,两台机器的时间戳不能直接相减,因为不在同一时钟域,解决办法是设法补偿时差。另外,不仅要测量平均延迟,更重要的是要测量并控制长尾延迟,即99百分位数或99.9百分位数的延迟。
普通C++服务程序,内部延迟(从进程收到消息到进程发出消息)做到亚毫秒级并不需要特殊的优化。如果瓶颈在CPU,最有效的优化方式是强度消减,即不在于怎么做得快,而在于怎么做得少。
网络延迟分传输延迟和惯性延迟,通常局域网内以惯性延迟为主,广域网以传输延迟为主。传输延迟是传送1字节消息的基本延迟,大致跟距离成正比。传输延迟受物理定律限制,优化办法是买更好的网络设备和租更短的线路。惯性延迟跟消息大小成正比,跟网络带宽成反比,千兆网TCP有效带宽按115MB/s估算,那么发送1150字节的消息从第1个字节离开本机网卡到第1150个字节离开本机网卡至少需要10us,是无法降低的,因此可以减小消息长度。
延迟和吞吐量是矛盾的,延迟跟吞吐量的关系通常是个U型曲线,吞吐量接近0的时候延迟反而比较高,因为系统比较冷;吞吐量增加一些,平均延迟会降到正常水平;吞吐量再增大,延迟缓慢上升;吞吐量过了某个临界点,延迟开始飙升。因此需要把吞吐量控制在合理范围,保证延迟处于正常值。
延迟和资源使用率是矛盾的,做高吞吐的服务程序,恨不得把CPU和IO都跑满,资源都用完。而低延迟的服务程序的资源占用率通常低得可怜,实际上平时资源使用率低是为了准备应付突发请求,请求或消息一来就可以立刻得到处理,尽量少排队,排队意味着等待,等待意味着长延迟。消除等待是最直接有效的降低延迟的办法,依赖的是系统的冗余。
延迟和可靠传输也是矛盾的,TCP做到可靠传输的办法是超时重传,一旦发生重传,会增加几百毫秒的延迟,因此保持网络随时畅通,避免拥塞也是控制延迟的必要手段。
因此,必须避免交易时段在服务器上拷贝日志文件等操作,或是部署两张网卡,一张网卡专门用于交易,一张用于运维操作。
另一个办法是写个慢速拷贝程序,故意降低拷贝速度,每50毫秒拷贝50kB,用时间换带宽。
另外,可以编写慢速压缩程序,每100毫秒压缩100kB,花一分半钟压缩完100MB数据,分散CPU资源使用,减少对延迟的影响。
标签:不同类 中断控制器 大量 服务器端 plane 报文 架构 使用 应用软件
原文地址:https://blog.51cto.com/9291927/2536092