标签:值类型 like category flag inux https tom 创建 一个个
数据库是个比较大的话题,有各种各样数据库常见的关系型数据库如Mysql 、oracle、非关系型数据库,还有图数据库等。数据库性能会跟许多部分有关联,从硬件底层存储设备、操作系统、数据库配置参数、数据库架构、数据库表结构、应用层面的连接池设置、以及SQL索引等。
对Mysql数据库进行分析,首先需要了解MySql的系统架构,如下图所示:
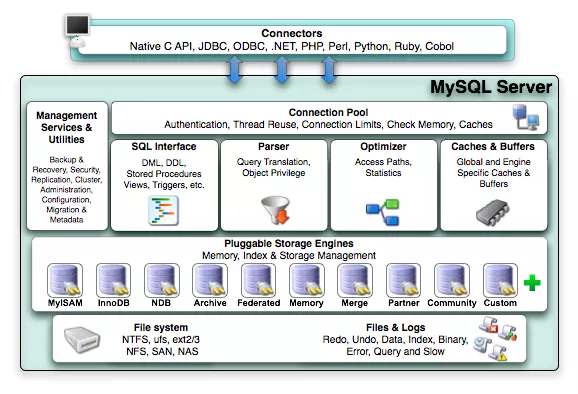
从这个架构图,来看Mysql系统架构分为应用层、MySql服务层、存储引擎层。
应用层,应用层是MySQL体系架构的最上层,它和其他client-server架构一样,主要包含:连接处理、用户鉴权、安全管理
MySQL服务层:该层是MysqlServer的核心层,提供了Mysql Server 数据库所有逻辑功能
存储引擎层
存储引擎是MySQL中具体与文件打交道的子系统,也是MySQL最有特色的地方。MySQL区别于其他数据库的最重要特点是其插件式的表存储引擎。他根据MySQL AB公司提供的文件访问层抽象接口来定制一种文件访问的机制(该机制叫存储引擎)。
物理文件包括:redolog、undolog、binlog、errorlog、querylog、slowlog、data、index等
知道数据库架构后,在性能分析时候需要知道这些模块的功能及运行逻辑,明白一个具体的sql所需要经历的过程:一个sql首先经过Connection Pool到达系统后,需要先进入Sql interface模块判断这个语句,是什么类型。然后通过Parser 模块进行语法与语义检查,并生成相应的执行计划;接着到Optimizer模块进行优化,判断走什么索引,执行顺序等,然后就到Cache中找数据,如果Caches中找不到数据的话,就得通过文件系统到磁盘中进行寻找。
了解了mysql系统架构和mysql执行过程还不够,在进行性能分析时,需要找出mysql的问题所得先了解一些基础知识和相应的监控工具。
首先需要了解的两个Schema 分别是information_schema和performance_schema,information_schema,它们保存了数据库中的所有表、列、索引、权限、配置参数、状态参数等信息。像我们常执行的show processlist;就来自于这个schema 中的 processlist 表。performance_schema提供了数据库运行时的资源消耗情况,它以较低的代价收集信息, 可以提供不少性能数据。
还有在分析mysql是需要知道的两个命令:showglobal variables ;和show global status ;前一个用来查看配置的参数值,后一个用来查询状态值。不过这些命令只是简单的罗列信息,并没有统计分析,接下来我们介绍两个个比较好的监控工具。
全局分析:mysqlreport
show status 输出的报告是用来计算性能瓶颈的参考数据,但是数据只是简单的罗列,不好一下子看出性能问题,而mysqlreport 不像show status简单的罗列数据,而是对这些参考数据加以融合计算,整理成一个个优化参考点,然后就可以根据这个优化参考点的值以及该点的衡量标准,进行对应的调整。
一、linux 环境下mysqlreport安装
步骤一:yum -y install perl-DBD-MySQL 依賴包
步骤二:yum -y install perl-DBI #依賴包
步骤三 :yum -y install mysqlreport
在linux系统上经过这三步就安装好了这个工具。接下来就可以对数据库运行状况进行分析了。
二、mysqlreport使用
使用比较简单,直接执行:
mysqlreport --user tesla --password xxx@2015 --host 127.0.0.1 --no-mycnf--flush-status --outfile ./result.txt
就可以把数据库整体情况保存到当前目录中。
具体命令参数查看
mysqlreport —help
三、mysqlreport结果分析:
数据库操作报表和查询排序报表
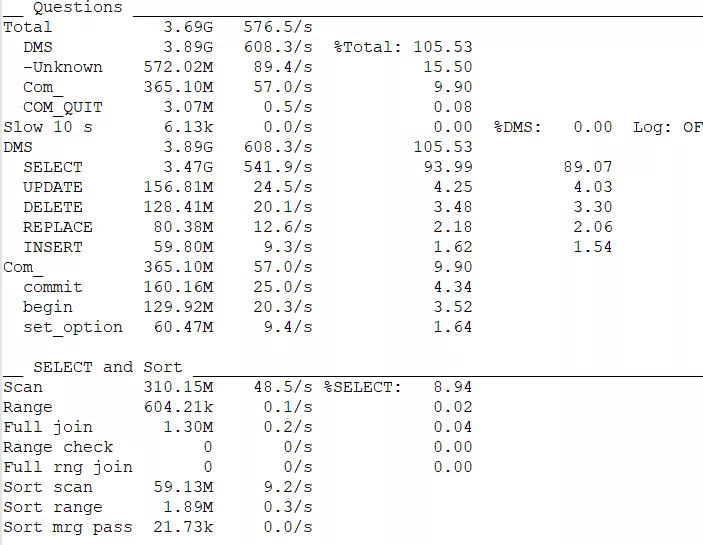
这个表反映数据库使用情况,608每秒操作量有点大,slow 这个参数挺重要,只是因为这里设置的慢查询10s太长了,正常情况下尽量设置在1s左右,这块需要对db 进行配置,把慢查询统计设置的短些。
DMS部分告诉我们这个数据库中各种 SQL 所占的比例,这个例子中,SELECT多,要做 SQL 优化的话,肯定优先考虑SELECT语句,才会起到立竿见影的效果。
这块的报表数据具有极大的参考性,一下就能看出问题的所在,这里的Scan(代表全表扫描)每秒48次执行全表扫描,实在是太多了,需要对语句进行修改,也是我们后面优化的重点内容。
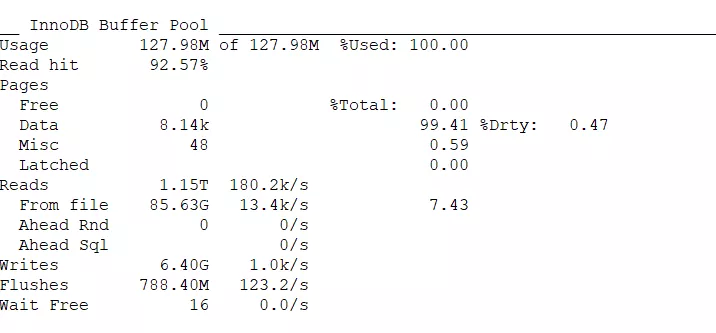
InnoDB 缓存池报表,Innodb Buffer Pool size 定义了Innodb 存储引擎的表数据和索引数据的最大内存缓存大小。这部分对MySQL来说很重要,这里使用已经达到100% 这种情况下就必须要增加Innodb缓存池了。这里的Read hit达到 92.57%,这个值越大越好,尽量达到100% 这里的值与Innodb buffer太小有关。
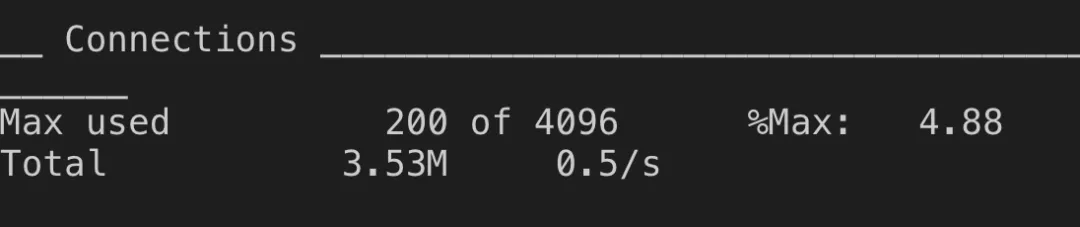
从这里可以看出数据连接还完全够用。
Waited表示有多少次查询需要等待表锁定;Immediate表示有多少次查询可以立即获得表锁定,同时后面还有一个比例
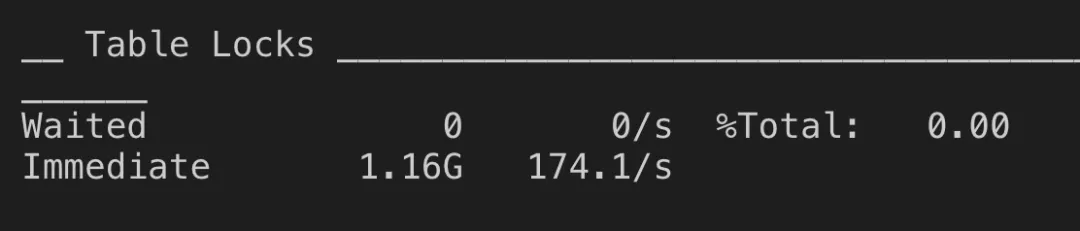
对数据库来说『等待』几乎可以肯定是一件很不好的事情,因此 Waited 的值应该要越小越好。最具有代表性的是第三个字段 (Waited 占所有 table lock 的百分比)这里是0.00%,非常好,没有发送过表锁。
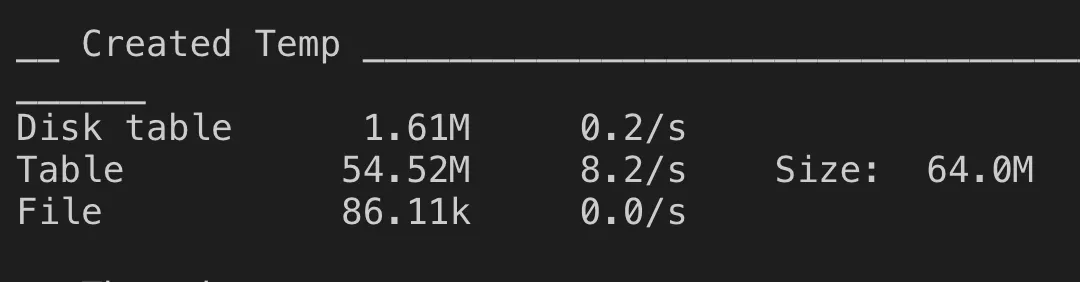
执行explain 在sql分析时出现Using temporary的状态,这意味着查询过程中需要创建临时表来存储中间数据,我们需要通过合理的索引来避免它。另一方面,当临时表在所难免时,也要尽量减少临时表本身的开销,MySQL可以将临时表创建在磁盘(Disk table)、内存(Table)以及临时文件(File)中,显然,在磁盘上创建临时表的开销最大,所以我们希望MySQL尽量不要在磁盘上创建临时表,上面分析结果来看从临时表创建在磁盘(Disktable)和临时文件(File) 上的 量级来说,还是有点偏大了,所以,可以增大tmp_table_size。
其它全局信息可以查下资料
通过mysqlreport这个工具反应的结果,有以下问题需要去解决下:
总体数据库操作达到600多每秒,对于内网系统用户不太多,操作有点太频繁,看下能够减少不必要的数据库操作。
慢查询未开启,而且设置的时间太长长达10s,通常一个语句大于100ms 可任务需要进行优化,这里需要设置较短分析下慢查询
全表扫描48.5/s 这块要分析下具体的sql写法
Innodb 缓存占用使用100% ,而且设置大小太小,需要增加缓存大小。
作为分析mysql工具的首选,因为它可以从logs、processlist、和tcpdump来分析MySQL的状况,logs包括slow log、general log、binlog。也可以把分析结果输出到文件中,或则把文件写到表中。分析过程是先对查询语句的条件进行参数化,然后对参数化以后的查询进行分组统计,统计出各查询的执行时间、次数、占比等,可以借助分析结果找出问题进行优化。
安装方法
下载 https://www.percona.com/downloads/percona-toolkit/LATEST/
安装:centos依赖包
yum -y install perl-TermReadKey perl-Time-HiResperl-IO-Socket-SSL.noarch
pt-query-digest --help
pt-query-digest分析 slow /bin log 时产生的报告逻辑非常清晰,并且数据也比较完整。执 行命令后就会生成一个报告,因为线网没开启slow log日志,这里我们分析下线网bin log日志
使用方法
对binlog日志进行转换:
mysqlbinlog --no-defaults -vv --base64-output=DECODE-ROWSmysql-bin.000818 > mysql-bin.000818.txt
pt-query-digest --type=binlog mysql-bin.000818.txt > 818.report.log
筛选出全表扫描语句
设置数据库设置开启 log_queries_not_using_indexes=on;就会输出全表扫描语句到慢查询日志当中。值得注意的是,执行时间超过long_query_time的SQL语句也将记录到slow log中,无论该SQL语句是否使用索引。
profiling的操作步骤:查看详细执行计划
步骤一 :set profiling=1; //这一步是为了打开profiling功能
步骤二 :执行语句 //执行你从慢日志中看到的语句
步骤三 :show profiles; //这一步是为了查找步骤二中执行的语句的ID
步骤四 :show profile all for query id; //这一步是为了显示出profiling的结果
修改表结构增加索引:索引名一般是表名加字段名
show index fromproject_permissions;
ALTER table project_permissions ADD INDEX idex_project (project_id);
ALTER table tableName ADD INDEX indexName(columnName)
create index 索引名 on 表名(字段名1,字段名2)
分析:执行频率非常高的语句以及全表扫描
1)
explain SELECT project_id, modified_time, name, permissions, isGroupFROM project_permissions WHERE project_id=2076;
根据执行计划和查询条件分析,需要对project_id 建立索引,建立索引后需要注意where条件中值的类型,这里需要把project_id 改成字符串,mysql隐式的将数值类型转换成了字符串类型
2)
explain SELECT id, model_name, model_type, job_id, properties,gmt_create, owner, last_execution_model, gmt_modified, published, status,module_id from mlstudio_model where job_id=13788;
数据库表记录9000条,没有增加索引,可以适当对job_id增加索引,也因为数据较小优先级比较低 ALTER table mlstudio_model ADD INDEX index_model(job_id) 有2倍性能能提升
3)
explain SELECT id, name, user_id, property, gmt_create,gmt_modified, appstatus, execution_info FROM mlstudio_deployed_notebooks WHEREappstatus in (10,140,20,120) ORDER BY gmt_modified desc;
分析及方案:数据库表记录200多条,没有增加索引,会全表扫描,优先级不太高,只不过property字段和execution_info信息数据比较大,建议如果property字段没有用到 查询语句就不指定property
4)
explain select id, algorithm_id, version, create_time, modify_time,module_id, shared, type, source_algorithm_version_id fromti_user_algorithm_version where module_id = 813;
解决方式:数据表记录目前较少 数据库字段比较短
ALTER table ti_user_algorithm_version ADD INDEX index_algorithm(module_id)
5)
explain select id, gmt_create, gmt_modified, name, type,description, checked, permission, user_id, nick_name, config_file_name,config_file_res, module_res, module_dependencies, job_type, user_coded,has_model, icon, module_jars from mlstudio_modules where module_res=0 andtype>0 and type <1001 and job_type=2;
数据记录不多,字段值相对都比较短,查询出来占据空间相对较小 625条影响较小
6)
explain SELECT id, name, type, gmt_create, owner, gmt_modified,published, status, module_id, properties from mlstudio_dataset where module_id= 229;
数据记录不多,字段值相对都比较短,查询出来占据空间相对较小 55条影响较小,对module_id加索引处理,查询很少可以不用处理
7)
explain select algorithm_id from ti_user_algorithm_favorite whereuser_id = ‘jianfehuang’ and algorithm_id = 101;
create index algorithm on ti_user_algorithm_favorite (user_id,algorithm_id);
解决方案 :创建联合索引,索引后速度有一定提升,只会查出一行记录对缓存占用小。目前数据库记录196条
8)
explain select cid, cname, cdesc, cicon, clevel, cparent, cvisible,group_concat(mid order by mname), sum(mpermission) as public_num from(select mmc.id as cid, mmc.name as cname,mmc.desc as cdesc,mmc.icon ascicon,mmc.level as clevel, mmc.parent_id as cparent,mmc.visible ascvisible,mmc.order_num as corder,mm.id asmid, mm.name as mname,mm.permission as mpermission from mlstudio_module_category mmc left joinmlstudio_modules mm on mmc.id =mm.type) as t group by cid, cname, cdesc, cicon, clevel, cparent, cvisibleorder by corder;
9)
select queuequota0_.id as id1_1_, queuequota0_.cpu as cpu2_1_,queuequota0_.gmt_create as gmt_crea3_1_, queuequota0_.gpu_map as gpu_map4_1_,queuequota0_.jizhi_business_flag as jizhi_bu5_1_, queuequota0_.memory asmemory6_1_, queuequota0_.name as name7_1_, queuequota0_.gmt_modified asgmt_modi8_1_, queuequota0_.uuid as uuid9_1_ from queue_quota queuequota0_ wherequeuequota0_.name=‘g_teg_teslaml_appgroup04’;
分析全表扫描:目前数据表比较小 ,数据量才155条,对性能影响较小,如果预期后面数据量变大,考虑增加索引。
10)
select task0_.id as id1_0_, task0_.admin_group as admin_gr2_0_,task0_.alert_group as alert_gr3_0_, task0_.business_flag as business4_0_,task0_.gmt_create as gmt_crea5_0_, task0_.creator as creator6_0_,task0_.description as descript7_0_, task0_.flag as flag8_0_, task0_.modifier asmodifier9_0_, task0_.name as name10_0_, task0_.project_id as project11_0_,task0_.props as props12_0_, task0_.type as type13_0_, task0_.gmt_modified as gmt_mod14_0_,task0_.view_group as view_gr15_0_ from tj_task task0_ where task0_.project_idin (1157 , 1913 , 2078);
分析全表扫描:目前太极任务数据表比较小 ,数据量才9条,对性能影响较小,如果预期后面数据量变大,考虑增加索引。
慢查询随着某个工程下工作流越多越慢,性能影响很大
select flow_id,max(id * 1000 + status) % 1000 as last_user_drive_status frommlstudio_execution_jobflow where (drive_type = 1 or drive_type is null) andproject_id in (24529) group by flow_id
存在问题扫描大量数据,拷贝到临时表,在执行文件排序。
修改为:
select f.flow_id,f.status from mlstudio_model_flowt inner join mlstudio_execution_jobflow f on t.last_jobflow_id=f.id where t.project_id in (24529)
MySQL调优之innodb_buffer_pool_size大小设置
查询线上配置:
sql> show global variables like ‘innodb_buffer_pool_size’;
sql> show global status like ‘Innodb_buffer_pool_pages_data’;
sql> show global status like ‘Innodb_page_size’;
sql> show global status like ‘Innodb_buffer_pool_pages_total’;
内网查询数据结果:
Innodb_buffer_pool_pages_total | 8191
Innodb_buffer_pool_pages_data | 8116
Innodb_page_size | 16384
innodb_buffer_pool_size | 134217728
调优参考计算方法:
val =Innodb_buffer_pool_pages_data / Innodb_buffer_pool_pages_total * 100%
val > 95% 则考虑增大 innodb_buffer_pool_size, 建议使用物理内存的75%
val < 95% 则考虑减小 innodb_buffer_pool_size, 建议设置为:Innodb_buffer_pool_pages_data * Innodb_page_size * 1.05 / (102410241024)
内网计算出来:8116/8190=99% 需要加大这个数据
数据库配置修改: 测试环境修改的/etc/my.cnf
1、开启慢查询日志,慢查询记录为1秒 ,这个对数据库性能有1%的影响,可以开启一段时间收集一段时间数据后关闭
slow_query_log = ON
long_query_time = 1
2、Innodb缓存增大
innodb_buffer_pool_size = 2G #设置2G
3、临时表目前64M 需要加大
tmp_table_size = 256M;
max_heap_table_size = 256M;
本文简单介绍了数据库优化的相关方法,通过两个工具全局分析:mysqlreport对show status 这些参考数据加以融合计算,整理成一个个优化参考点,然后就可以根据这个优化参考点的值以及该点的衡量标准,进行对应的调整。
pt-query-digest 工具,可以从logs、processlist、和tcpdump 来分析MySQL的状况,logs包括slow log、general log、binlog,可以借助分析结果找出问题进行优化。通过这两个工具可以在数据库配置层,对mysql进行相对比较优化的配置还可以找出性能比较慢的语句,通过profiling 详细分析sql执行的过程进行优化。
本文由博客一文多发平台 OpenWrite 发布!
标签:值类型 like category flag inux https tom 创建 一个个
原文地址:https://www.cnblogs.com/tencentdb/p/13864720.html