标签:比较 art hat content iter nts roc proc 推荐
这篇文章是2017年由华中师范大学发表在《Multimedia Systems》这个期刊上面的(虽然我感觉这个文章比较一般,但是他毕竟是个SCI,应该还是有点东西的;并且Google Scholar显示引用数有53)。这篇文章号称能够“give students a personalized and suitable learning service”,并且确实是最近查到的最接近我们所在做的东西的peer work。
整篇文章的思路非常直接:被推荐的对象是learning resource(实际上他们用的是Book-Crossing dataset,并且按照他们的描述,是采取了Amazon对这些书的描述数据)(所以说这个被推荐的东西就是书籍)。
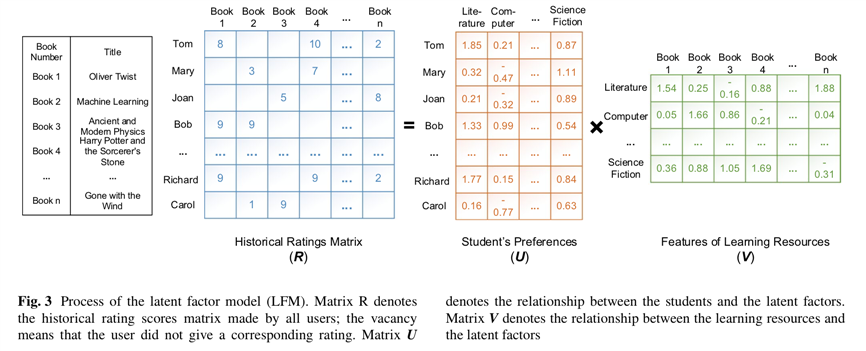
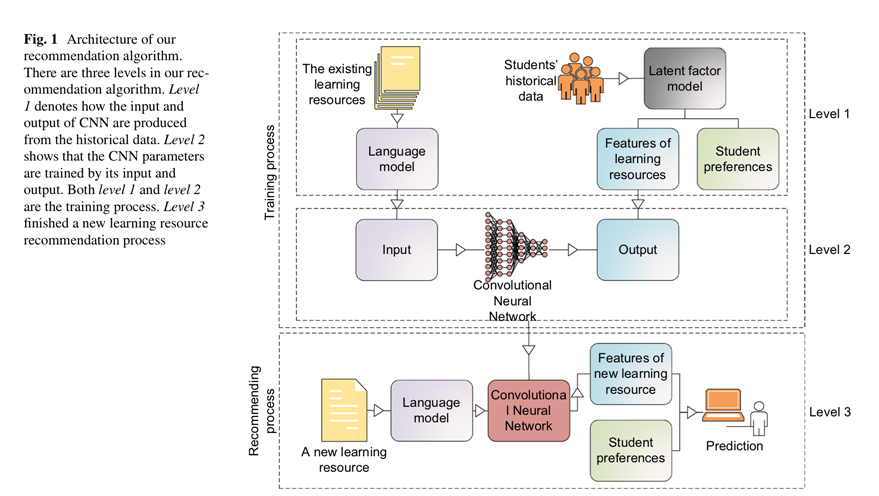
推荐系统直接采用Latent Factor Model:如上图,R矩阵为学生对书籍的rating,可以分解成U和V两个矩阵,其中U代表学生的preference,V代表书籍的feature。与传统的latent factor模型不同,在将R分解为U和V之后,论文不是从U和V的层面去生成推荐结果,而是把U作为模型的training output,用CNN接受文本输入作为training input;而文章假设学生的偏好不变,这样就可以通过在测试集上面运行CNN得到U‘,再进行U‘V=R‘,来计算error。整个模型如下图所示。
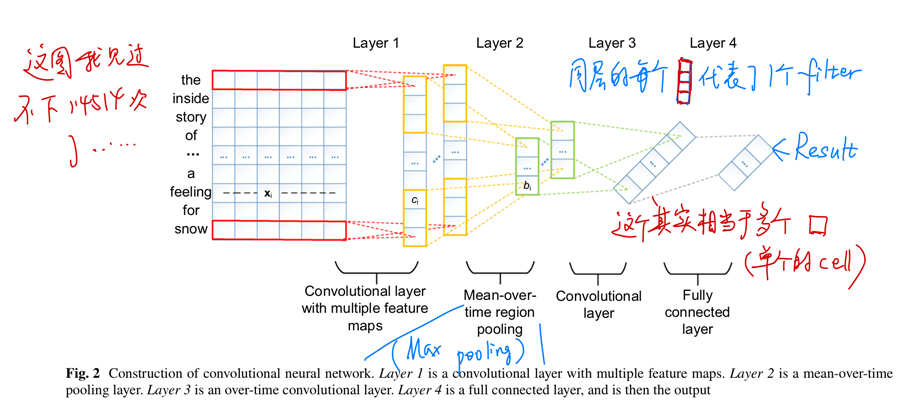
具体到细节,CNN的结构比较常见,因此也不做过多介绍;LFM因为R矩阵比较稀疏,因此采用L1 norm去作为限制条件进行优化,使用split Bregman iteration method 来进行学习。算法如下图所示。

论文认为,这个模型具有以下的创新点:1,推荐效果好(具体表现在:sparseness低,loss低,accuracy高,收敛快,训练时间短;可是不会有论文作者说自己这几个方面的表现差吧!);2,这个方法可以不仅应用于书籍,也可以通用于电影or音乐等等的推荐。
总体而言,这篇文章有一定的独到之处,对LFM的改进是有独到性的。不过,还是难以避免一般推荐系统所常见的缺陷,例如如何预测变化的用户偏好,等等。
Recommending e-learning related resources is becoming increasingly important due to higher demands of online learning systems. This paper proposes a novel text-based recommendation algorithm for those resources which is built with CNN and Latent factor model. In this model, CNN is used to predict students’ preferences towards different features of resources from their text contents, and predict students’ ratings for those resources by LFM. Experiments have shown that by applying this model, there is a noticeable improvement compared to state-of-the-art methods, in aspects of accuracy, sparseness and training cost; also, this model can also be applied to other fields such as movies or TV programs, not limited to learning resources.
In this paper, we proposed a model which makes use of CNN to predict different POIs from text description of e-learning materials, and use its output as part of LFM to produce students’ potential ratings for those materials. In our model, we use L1-norm based prior and split Bergman model to make the training process of LFM more accurate and faster. After verifying this model on public dataset, we have found that this algorithm does have advantage over traditional methods. This model is expected to bring about impact on e-learning resources, and is hoped to be extended to other fields such as movie recommendation.
论文分享:A content-based recommendation algorithm for learning resources
标签:比较 art hat content iter nts roc proc 推荐
原文地址:https://www.cnblogs.com/spadeayase/p/13874855.html