标签:使用场景 应用 zookeeper 机器 提高效率 模式 解决 区分 设置
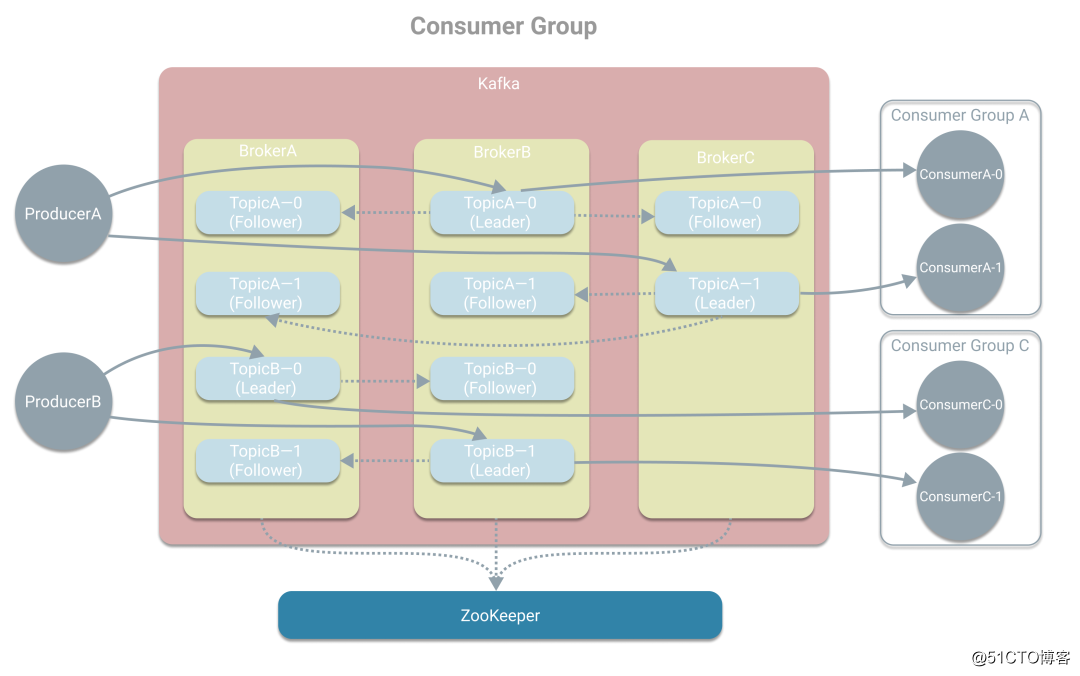
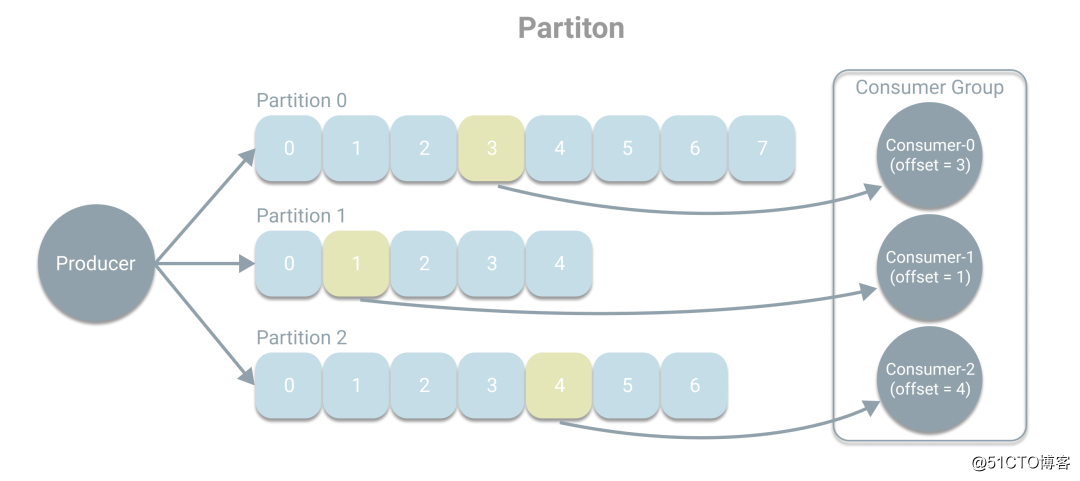
在上篇文章《消息系统概述》中对消息系统进行了介绍,本次将学习Kafka中的基本概念。首先我们回顾下在消息系统的使用场景中有三种角色分别是生产者、消息系统和消费者,其中生产者负责产生消息和发送消息到消息系统,而消息系统将为消费者提供消息用于处理,如下图。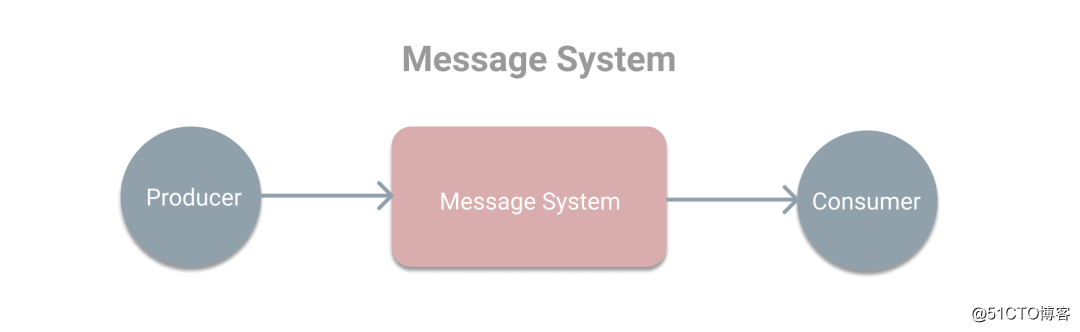
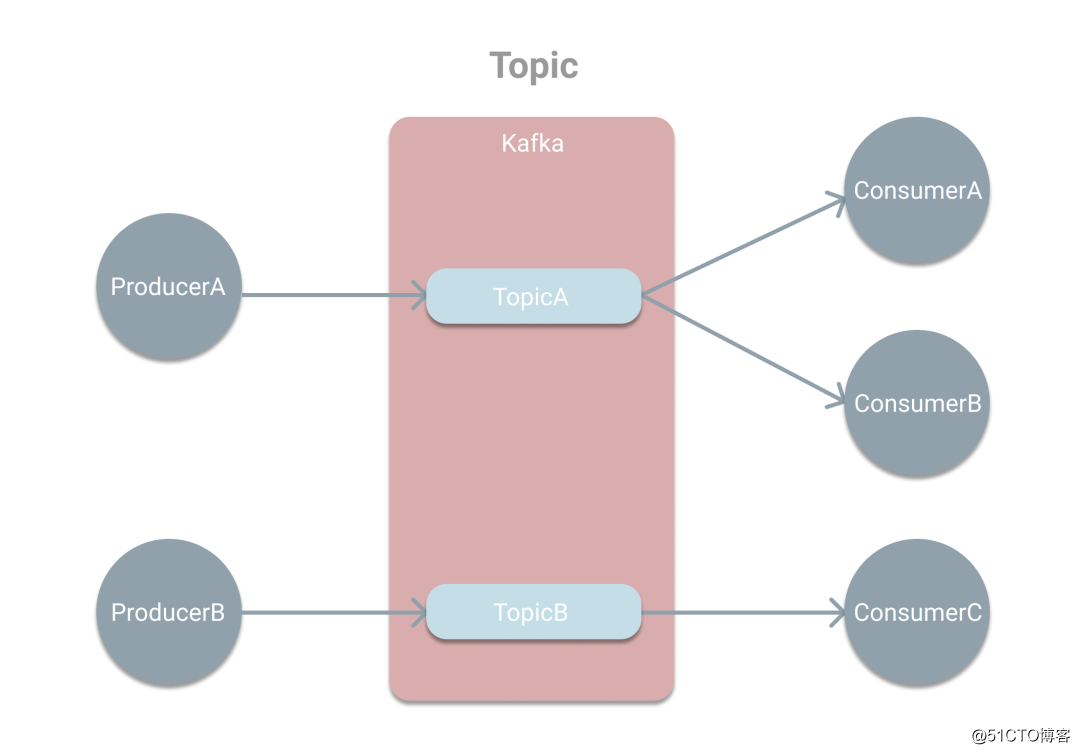
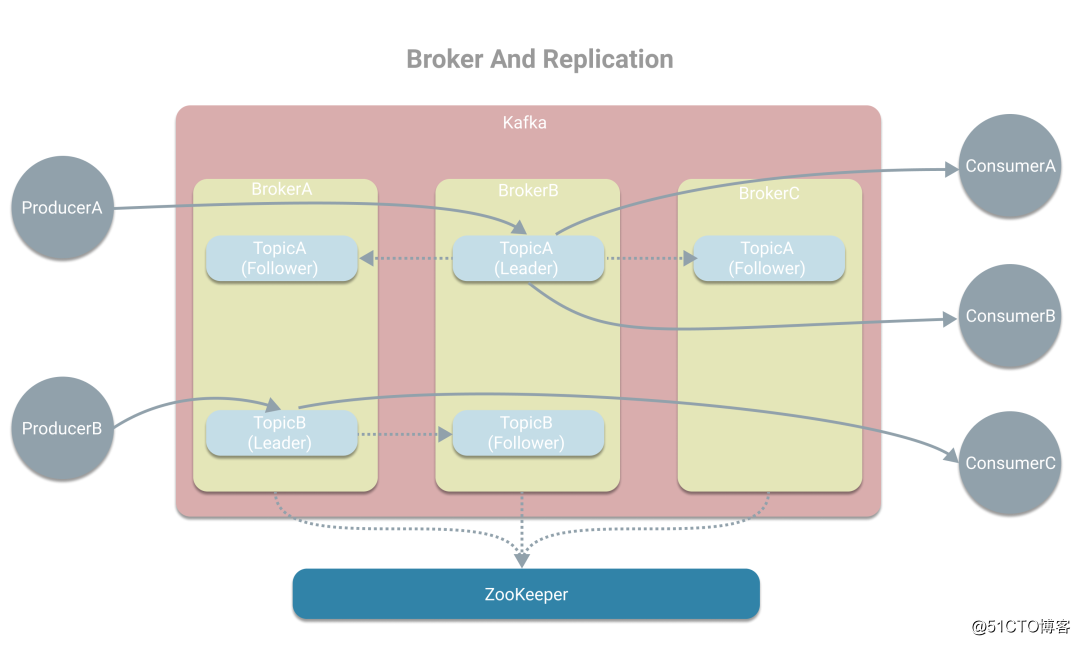
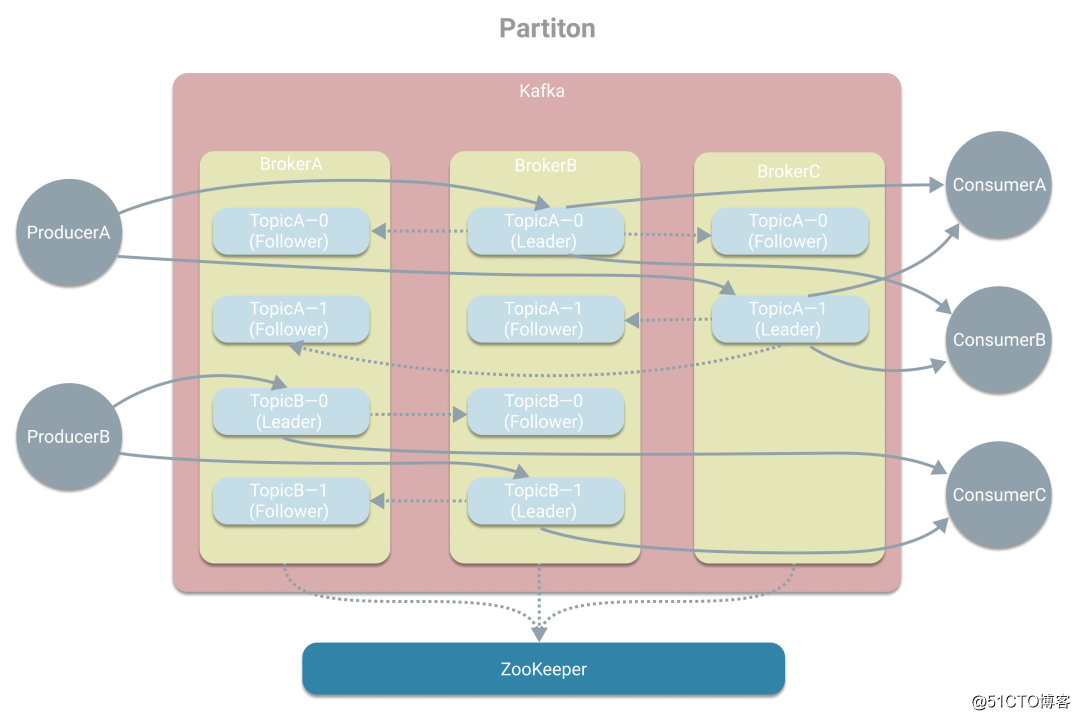
标签:使用场景 应用 zookeeper 机器 提高效率 模式 解决 区分 设置
原文地址:https://blog.51cto.com/9167833/2544262