标签:指针 情况 子页面 Mysql引擎 并且 磁盘io 内存 center 设置

B+树是为磁盘和存储工具设计的一种数据结构,它是一种平衡查找树,它在查找,插入、修改方面的时间复杂度都稳定为 O(logn)
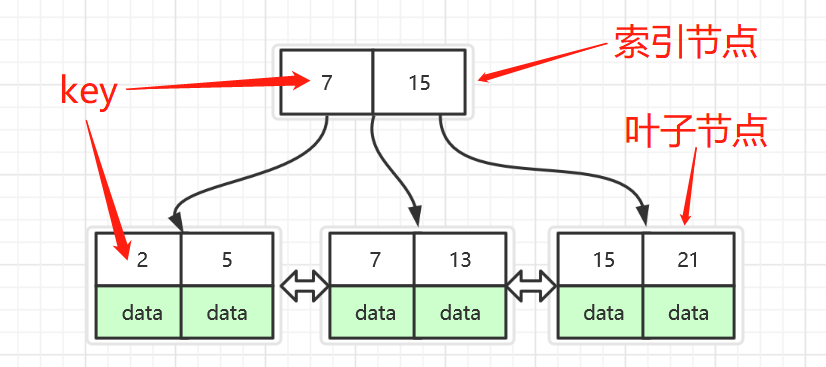
B+树节点是一组按照key有序的元素,B+树包含两种类型的节点,一种是索引节点,一种是叶子节点
索引节点也叫内部节点,索引节点只包含key,不包含data, 节点的 key是升序排列的,对于指定的索引节点key来说,它左子树上所有的key都小于它的key,它右子树上所有的key都大于等于它的key
叶节点上存储的是主键和数据(key和data), 所有的叶节点都在同一高度上,节点按key 从小到大并且通过指针使得彼此链接,这样,所有的叶节点组成了一个双向有序链表,叶节点这样做的好处是在不访问索引的情况下能顺序检索数据,也能很好的支持范围查询的快处理
阶数为 m 的B+树,每个索引节点最多有 m 个子节点,每个索引节点页面最多存储 m - 1 个索引key
所有索引节点的子节点数在 Math.ceil(m / 2) 和 m 之间
B +树之所以称为平衡树,是因为从根节点到叶节点的每条路径都具有相同的长度。平衡树意味着所有对单个值的搜索都需要从磁盘读取相同数量的页面。
B+树使用填充因子来控制页面的分裂和合并,设置数据占用页面空间的百分比,目的是为后面的数据预留一部分页空间,当有新数据时,可以放到预留的页空间中,避免分页的发生
默认的填充因子是50%,对于一棵m阶的B+树,填充因子是 m/2
B+树常用操作涉及到查询、插入、删除、范围查询, 为了便于说明,下面所有操作的例子中的B+树无特殊说明都是5阶树
每个页面最多有4个key,大于等于5个时就需要分裂或者旋转合并
填充因子默认是50%,页面中已经使用了的数量为2表示填充因子为50%,同理,小于2时候表示填充因子小于50%,大于2时候表示填充因子大于50%
B+树的索引节点是有序的,查询单个key的话直接用二分查找定位到目标叶子页面,在目标叶子页面中顺序遍历,找到目标key,则返回叶子页面中目标key对应的数据
B+树的插入操作完成以后,有以下几种情况
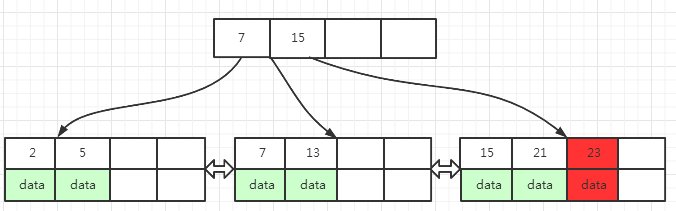
这种情况插入操作步骤最少,根据key把数据插入到叶节点已经排序的位置上即可,下图中是插入key为 23的数据,23会插入到包含 15, 21 的叶子页面中,插入之后叶子页面没有满,不用处理页面分裂的情况
步骤:
(1):叶节点页面分裂成两个页面
(2): 把中间行数据的key按顺序加入到上一层的索引页中
(3): 所有小于中间行数据key的数据放到左叶子页面
(4): 所有大于等于中间行数据key的数据放到右叶子叶面
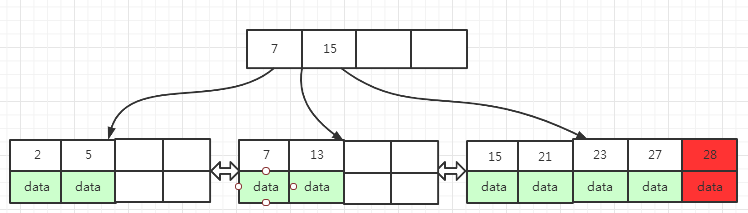
往图(2) 的B+树中插入key为28的数据,这条数据会插入到包含15,21,23,27的叶子页面中,插入之后,该页面数据已满,必须要分裂成如下所示的两个页面:
| 左叶子页面 | 右叶子页面 |
|---|---|
| 15,21 | 23,27,28 |
中间行数据key为:23,放到上一层的索引页面中15的后面,下面图(3)是插入key为28的结果
步骤:
(1):叶节点页面分裂成左右两个叶子页面
(2): 把中间行数据的key按顺序加入到索引页中
(3): 所有小于中间行数据key的数据放到左叶子页面
(4): 所有大于等于中间行数据key的数据放到右叶子页面
(5): 上面步骤(2)执行之后,索引页面满了,分裂成左右两个索引页
(6): 所有小于索引页中间的key的放到左边索引页
(7): 所有大于索引页中间的key的放到右边索引页
(8): 把索引页中间的key放到更高一层的索引页
如果步骤(8)执行之后,更高一层的索引页满了,继续执行(5)-(8)步骤
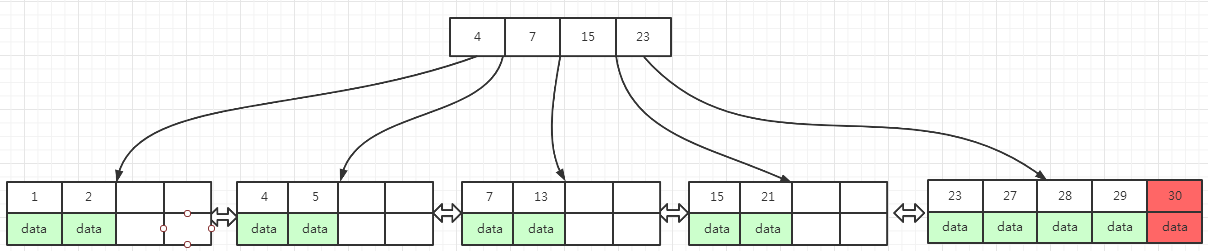
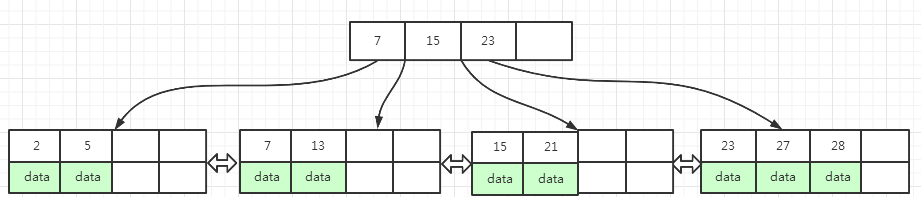
图(4) 的B+树插入key为30的数据,这条数据会插入到 23, 27, 28, 29 的叶子页面中,插入之后,该页面数据已满,必须要分裂成如下所示的两个页面:
| 左叶子页面 | 右叶子页面 |
|---|---|
| 23,27 | 28,29,30 |
中间行数据key为:28,放到索引页面中23 的后面
28 放到索引页面23的后面之后,索引页变成了4, 7, 15, 23, 28 , 这时索引页也满了,分裂成如下所示的三个页面 :
| 左索引页 | 右索引页 | 更高一层索引页 |
|---|---|---|
| 4,7 | 23,28 | 15 |
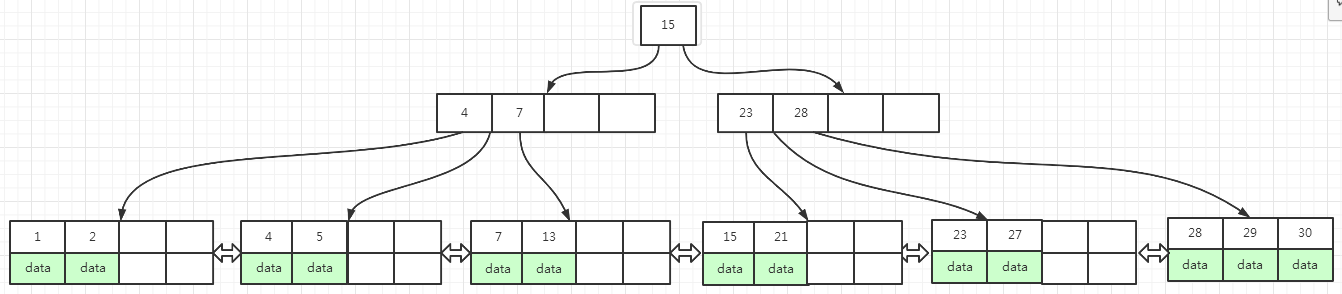
下面图(5)为插入key为30数据之后,叶子页面和索引页面分裂之后的结果:
B+树的插入操作会有页面分裂的情况,页面分裂就会有产生磁盘IO,相对内存,磁盘 IO 要慢得多,所以为了减少磁盘IO操作,就要尽可能的减少页面分裂,充分利用页面空间,因此B+树提供了旋转操作
旋转操作的应用场景: B+树叶子页面空间已经满了,但是它的左右兄弟页面没有满
叶子页面空间满了,B+树会优先检查左右兄弟叶子页面是否能容纳数据,当左右兄弟页面空间都满了时,才会考虑页面分裂
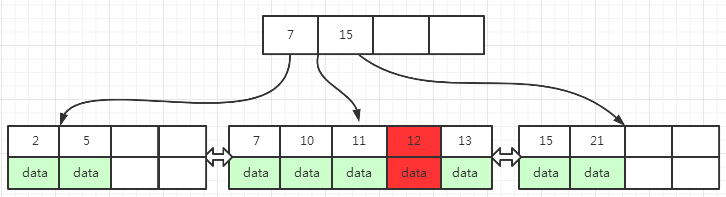
图(6)中,插入key为12的数据,叶子页面空间满了,这时B+树先检查左兄弟页面是否有多余的空间,通过旋转,把key分别为 7, 10, 11, 12, 13的叶子中的 7 移动到左兄弟页面中,移动完成之后,左兄弟的key变成了 2, 5, 7
同时,叶子中key为7的数据在上层索引页中也有记录,所以需要把上层索引页中key为7修改为 10,修改之后上层索引key分别为 10, 15 ,最终的结果如下图(7)所示
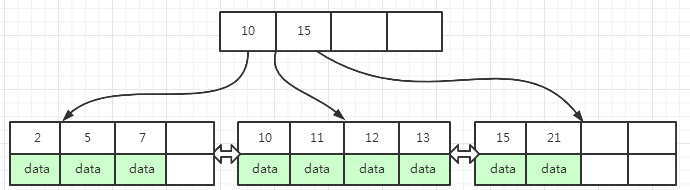
叶子页面插入新数据之后,页面空间已满,原本页面时需要分裂的,但是通过把当前页面上的数据移动到能容纳数据的兄弟页面中,减少了一次页分裂,也即减少了一次磁盘IO操作
B+树的删除操作完成以后,有以下几种情况
这种情况直接删除节点,页面会把删除节点的位置标记为空,以便存放后续其他的数据,同时,如果删除的key出现在上层的索引页面中,需要用叶子页面中被删除节点的下一个节点key去替换它
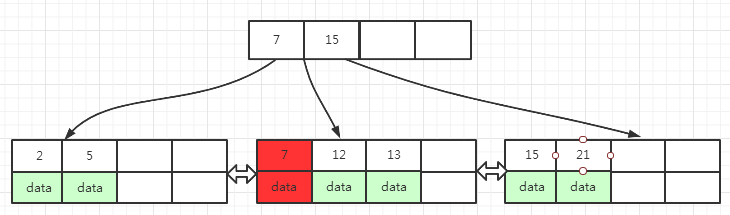
图(8)中 7是待删除的节点,删除7后,叶子页面填充因子刚好等于50%,因为被删除的7在上层的索引页面中出现了相同的key,所以需要用叶子页面中下一个key,也就是12替换上层索引页面中的7,最终的结果如下面图(9)所示:
叶子页面填充因子小于50%的时候,为了维持B+树的平衡,会有页面数据转移和合并的操作
当一个叶子页面填充因子小于50%,左右兄弟页面存在填充因子大于50%的时候,可以把兄弟页面中的数据转移到当前页面中,上一层索引页面中因叶子页面数据转移受影响的索引key也需要做相应的处理
如果左右兄弟页面的填充因子都大于50%时,转移任何一边页面数据到当前页面都可以,虽然选择不同的页面转移数据后,B+树的形态不一样,但是最终都是满足B+树特点的
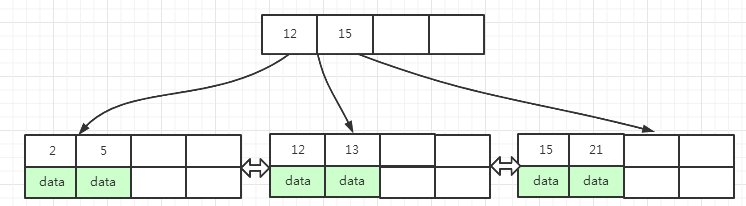
上面图(10)中,删除key为16的数据 ( 图中红色标识的区域 ),删除之后,原来key为15, 16的叶子页面变成了 15 ,页面只剩下一个key
此时页面的填充因子小于50%,左兄弟页面填充因子大于50%,满足页面数据转移的条件
把左兄弟页面 (key为 7, 12, 13 )中的 13 转移到当前页面中
转移之后,两个页面key数量刚好等于填充因子,左兄弟页面key变为 7, 12,当前页面的key变为 13, 15
当前页面中最小key值由原来的 15 变成了 13,为了保持B+数的平衡,需要把当前页面上一层的索引页面中key为15替换为13, 最终的结果如下面图(11)所示 :
上面说明了从兄弟页面转移数据到当前页面,现在我们来看下当前页面数据量小于填充因子的时候,如何合并到兄弟页面中
当一个叶子页面填充因子小于50%,左右兄弟页面存在填充因子等于50%的时候,可以把这个叶子页面合并到左右兄弟页面中,上一层索引页面中因叶子页面数据合并受影响的索引key也需要做相应的处理
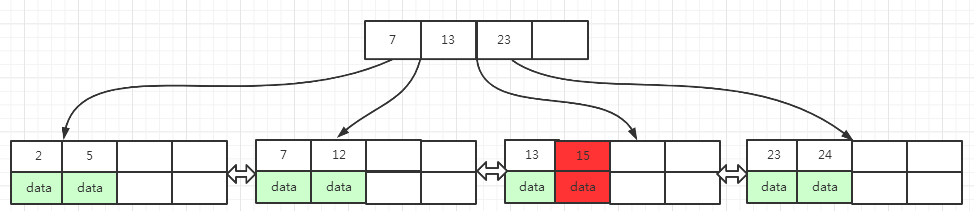
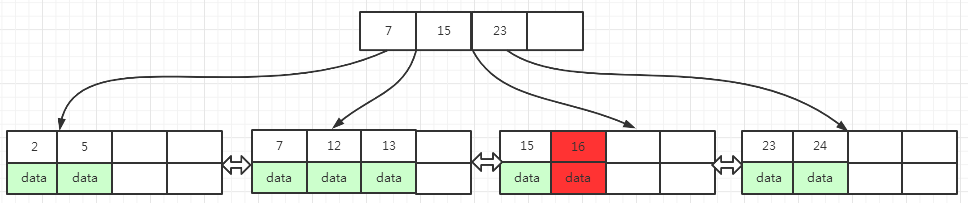
在图(12)中,执行删除key为15的操作(图中红色区域),15位于key为 13, 15 的页面中,删除15之后,当前页面key变成了 13, 只剩下一个key了
此时,当前页面填充因子小于50%,左右兄弟节点填充因子等于50%,所以无法从兄弟页面转移key数据到当前页面,但满足当前页面数据合并到兄弟页面的条件
左右兄弟页面都满足当前页面数据合并过去,选择任一兄弟页面都可以,虽然选择不同兄弟页面,会导致B+树的形态也不一样,但最终都是让B+树维持平衡,这里我们选则合并到左兄弟页面
15 被删除了之后,当前页面只剩下key为 13 的数据了
它合并到左兄弟页面之后, 当前页面为空,需要移除上一层索引页面中指向当前页面的索引key 13, 移除13的索引key之后, 索引页面key由原来的 7, 13, 23 变成 7, 23
合并之后,左兄弟页面key由原来的 7, 12 变成 7, 12, 13
最终的结果如下面 图(13) 所示 :
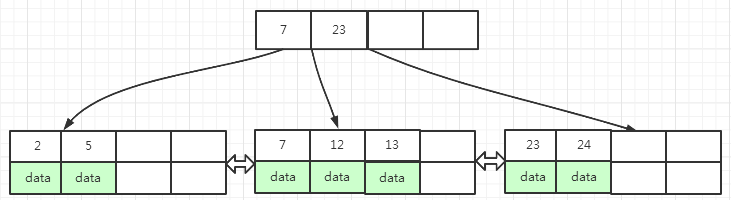
当叶子页面和索引页面填充因子都小于50%的时候,叶子页面和索引页面都会有数据转移或者合并的操作
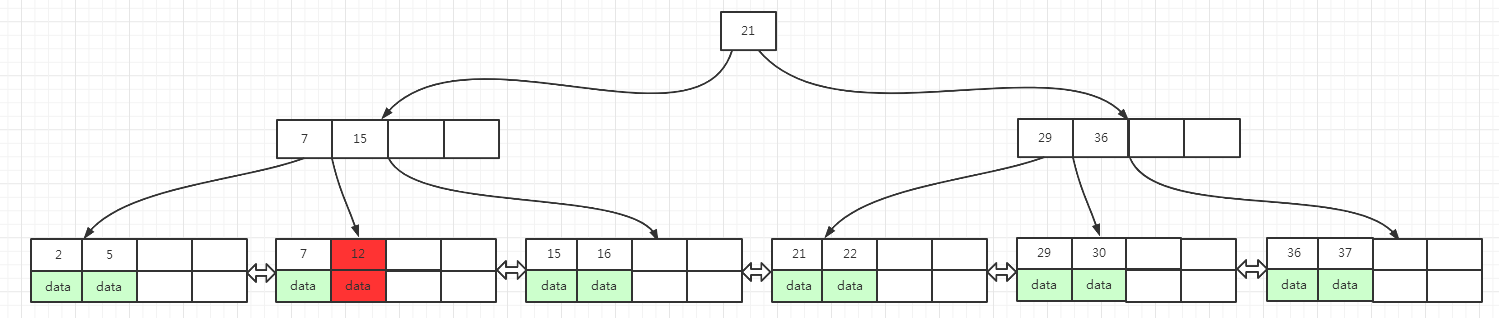
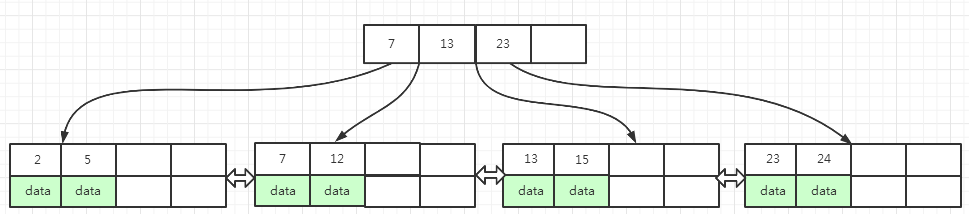
在图(14)中,执行删除叶子页面中key为12的数据(图中红色区域),12 位于key为 7, 12 叶子页面中,删除 12 之后,当前叶子页面变成了 7,只剩下一个key了
当前叶子页面左右兄弟页面填充因子都是50%,所以满足合并的条件,合并到左兄弟页面或右兄弟页面都可以,这里我们选择合并到左兄弟页面
当前叶子页面中key为 7 的数据合并到左兄弟页面之后,当前叶子页面没数据了,而左兄弟页面key变成了 2, 5, 7
为了保持B+树的平衡,指向当前叶子页面的上一层索引页面中,需要删除key为 7 的索引key, 删除key为7的索引后,索引页面key变成了 15, 这时该索引页面填充因子小于50%,右兄弟页面填充因子等于50%,满足合并的条件
但是,索引页面数据合并到右兄弟页面之后,根节点的左子树就为空了,为了保持B+树的平衡,根页面数据需要合并到下一层的索引页面中
最后的结果如下面图(15)所示 :

B+树的叶子节点是按照key从小到大的顺序组成的一个双向链表,所以B+树非常适合范围查询(这里说的范围是B+树中索引节点的key的范围)
使用二分查找首先确定范围查询的起始key所在的叶子节点的位置,然后顺序遍历叶节点链表,直到叶节点key大于范围查询结束key,查询停止
一颗 m 阶的B+树,索引节点存储的是索引信息,为了计算方便,这里假设一个索引key信息 8 字节,一个磁盘页面大概 4K,那么一个磁盘页面能容纳的索引数量为: 4 * 1024 / 8 = 512,此时 m 就等于 512
当B+树高度为2时,最多能容纳 512 (512的1次方) 个索引信息
当B+树高度为3时,最多能容纳 26万 (512的2次方)个索引信息
当B+树高度为4时,最多能容纳 1.3亿 (512的3次方)个索引信息
当B+树高度为5时,最多能容纳 687亿 (512的4次方)个索引信息
从上面的数据可以看到,B+树高度为5时,
能容纳 687 亿个索引信息,可以非常够用了
在实际的应用当中,B+树的根节点都是缓存在内存中的,树的最底层时叶子节点
所以针对高度为5的B+树,查找一条指定key值的数据最多只需要3次磁盘IO就能定位到具体的叶子页面,当树高度为4时,最多只需要2次磁盘IO就能定位到具体的叶子页面
B+树主要用于磁盘和存储工具,著名的MySQL引擎 InnoDB 索引的数据模型使用的就是 B+ 树
当数据超过一定的量级的时候,为了快速检索数据而设置的索引信息也会变得非常庞大,而且这部分索引信息只能存储在磁盘中,B+树能从磁盘中快速检索到需要的数据,并且时间复杂度稳定在O(logn)
标签:指针 情况 子页面 Mysql引擎 并且 磁盘io 内存 center 设置
原文地址:https://www.cnblogs.com/wanng/p/13894205.html