标签:linux 活动 img 监控系统 业务 mamicode 定义 inux cdn
从5台服务器到两地三中心:魅族系统运维架构演进之路(含PPT)导读:高可用架构 8 月 20 日在深圳举办了『互联网架构:从 1 到 100』为主题的闭门私董会研讨及技术沙龙,本文是覃军分享的魅族运维架构演进历程。 覃军,现任职于魅族 Flyme 平台研发部运维平台,负责 Flyme 基础平台系统运维工作,经历服务器数百到数千的发展规模。对魅族的基础网络,系统部署交付及资源运营成本核实方面有深入的了解,目前负责的 IaaS 平台服务器规模超过 6000 台,有效支撑 Flyme 系统的基础服务及游戏运行。
覃军,现任职于魅族 Flyme 平台研发部运维平台,负责 Flyme 基础平台系统运维工作,经历服务器数百到数千的发展规模。对魅族的基础网络,系统部署交付及资源运营成本核实方面有深入的了解,目前负责的 IaaS 平台服务器规模超过 6000 台,有效支撑 Flyme 系统的基础服务及游戏运行。
魅族的互联网业务起步得比较早, 2011 年就开始,到 2014 年真正转变为一家移动互联网公司。从 2014 年开始,魅族互联网业务呈现爆发式增长,截至 2015 年底,Flyme 注册用户突破 3000 万,应用商店超过 100 万款应用,总下载量超过 100 亿,营收能力同比增长 12 倍。伴随着业务的高速发展,运维面临的挑战也越来越大,碰到的问题也越来越多,同时运维架构在不断的完善变更。
这几年我们主要围绕质量、效率、流程、成本维度对运维工作进行优化,慢慢的由运维转变为技术运营,提高自身的价值。
问题
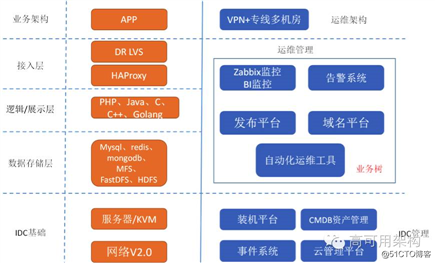
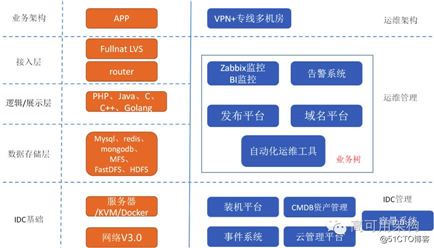
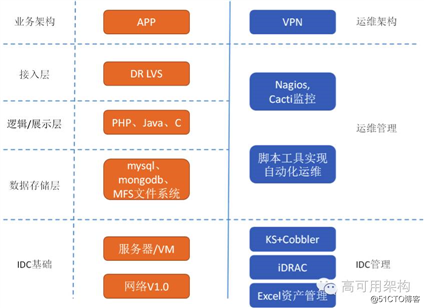
魅族的整体架构还是跟多数互联公司一样,采用多级分层模式,目前所有的业务全部有高可用方案,应用或 DB 至少 2 台以上。当然,具体业务要复杂很多,以上只是抽象出简单层面。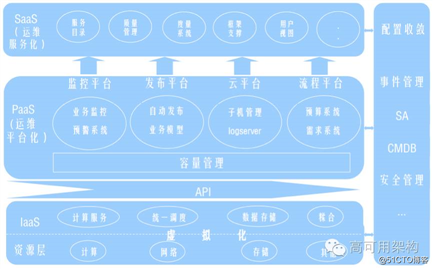
(点击图片可放大浏览)
魅族的运维平台和技术平台开发了很多实用的系统,这些系统组成了整体的运维体系。在自动化方面,我们也是摸着石头过河,根据实际出发,找出痛点,归纳整理出需求,并考虑如何实现。我们的思路是定义优先级,任务分解,先做最容易的,最能提高效率点,再做整合,通过各个子系统的整合,慢慢形成适合自己的自动化运维框架。
接下来给大家介绍下我们的监控系统,魅族基础系统层监控采用的 zabbix,这也是当前规模比较适合的一套监系统。 zabbix 是基于 Web 界面提供分布式系统监视以及网络监视功能的企业级开源解决方案。 zabbix 能监视各种网络参数,保证服务器系统的安全运营;并提供灵活的通知机制以让系统管理员快速定位/解决存在的各种问题。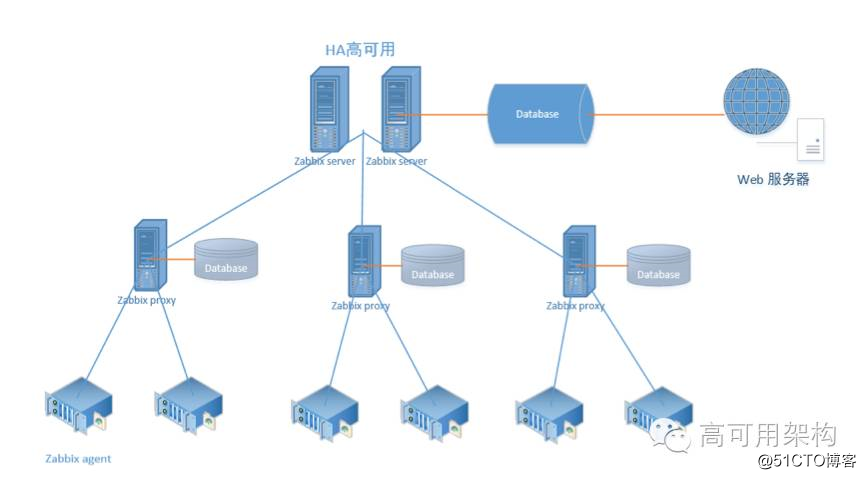
(点击图片可放大浏览)
我们采用的是 server-proxy-client 架构,其中 proxy 是 server、 client 之间沟通的一个桥梁, proxy 本身没有前端,而且其本身并不存放数据,只是将 agentd 发来的数据暂时存放,而后再提交给 server 。对监控模板标准化,针对不同的组定义不同的模板,每个组的运维/开发人员接收自己负责业务的告警。在 zabbix 后台定义匹配的动作,通过 hostname 匹配,当修改 CMDB 的状态为“运营中”, agent 就会根据 CMDB 主机的业务树自动上报分组并添加到 server 端,减轻了原来手动添加监控的工作量。同时 zabbix 会拉 CMDB 里面的主机数据进行比对,发现哪些主机未添加成功并定时发邮件给相应运维人员处理,保证了监控覆盖率。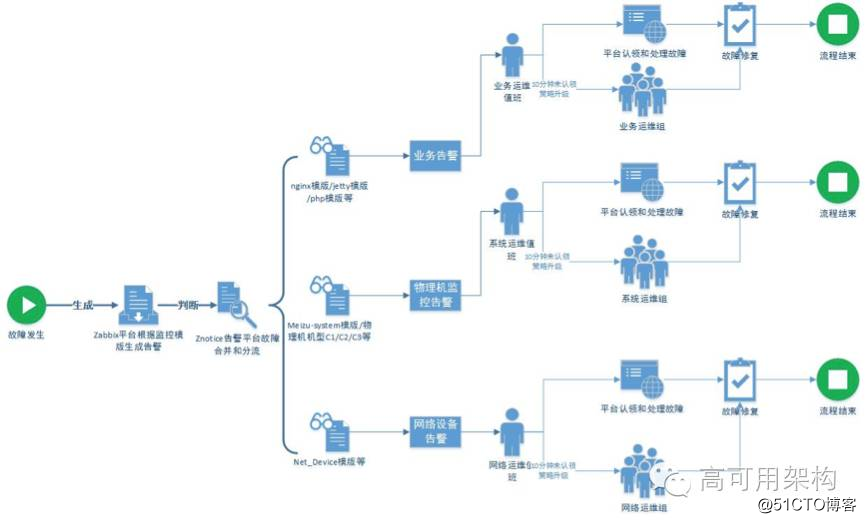
统一告警平台
(点击图片可放大浏览)
通过 zabbix 告警信息接入统一告警平台,实现告警信息收敛。通过预先设定的不同级别场景下的不同阈值,进行批量告警收敛,避免瞬时突发告警对用户造成困扰,按业务模块进行批量收敛。
1)在 zabbix 中配置 trigger 的 severity 的值,并配置 action 的 Default message 的内容
2)在统一告警平台中配置服务的故障分发功能
在告警平台上配置升级策略,每个升级策略配置配置不同的接收告警的方式,配置不同的接收人。然后在服务管理中配置故障分发,根据发送消息中 severity 的值进行匹配,匹配 Warning 和 High 两个级别的故障进行分发。
通过以上机制,原来每天由 zabbix 发出 5000 多条短信降低为现在的 800 多条,有效的减低短信成本。
去年我们出现过 net.netfilter.nf_conntrack_max 值设置未生效的问题, iptables 处于打开状态,导致 kvm 宿主机在大流量和高并发量的情况下网卡容易丢包,影响多个业务的稳定性。最后通过检查宿主机内核参数 net.netfilter.nf_conntrack_max 是否设置为 655350,关闭 iptables 解决。我们意识到在 OS 层,要做定制化和标准化,通过巡检系统发现非标准机器,定时整改。
系统对时任务、 selinux 状态、 iptables 状态、 eth0 网卡链路状态、 eth1 网卡链路状态、 bonding 模式、网卡命名、 yum 源配置文件、 yum 源配置文件内容、 DNS 配置、 MFS 挂载检测
检测拥有 root 权限用户、检测当前空口令用户、 passwd 文件读写权限、 shadow 文件读写权限、 group 文件读写权限、拒绝 .rhosts 文件存在、打开 tcp_syncookies、缓解 syn flood ***、防止 syn ***优化、单用户启动密码
net.netfilter 检测、 nf_conntrack 检测
(点击图片可放大浏览)
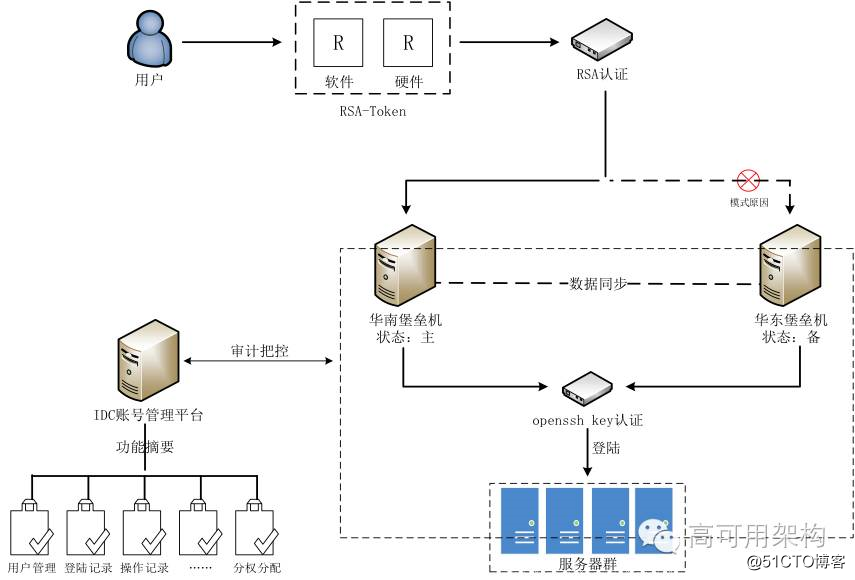
我们的堡垒机体系是通过 RSA Token + 堡垒机模式实现角色管理与授权审批、信息资源访问控制、操作记录和审计、系统变更和维护控制。避免了登录账号管理混乱、运维权限划分不明、认证方式过于简单、对运维过程没有监控措施、对研发人员的运维次数没有合理的运维统计方式。
服务器的引入、生产、运营、利旧、退役的生命周期闭环,需要高效的自动化流程支撑。通过流程设计建立每个流程的模型,一般每个流程都要涉及到多个部门角色和系统,需要确定关键环节、职责分工、系统间接口,为了降低流程开发成本,需要考虑原子流程 - 组合流程 - 业务流程的分级实现模式。
(点击图片可放大浏览)
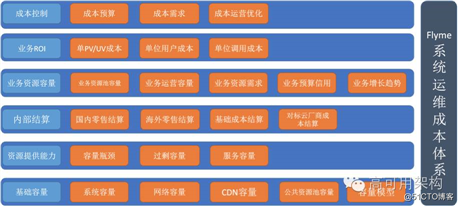
通过建立内部营收体系,能更有效的量化各业务的投入产出比,为领导决策提供依据。魅族主要通过成本控制、业务 ROI、业务资源容量、内部结算、资源提供能力、基础容量几个方面实现。
建立精准的预算模型,根据业务量预估资源,包括机柜、 CDN、带宽、专线、服务器、网络设备、短信、安全服务、人力成本等。前期深入到业务,了解业务资源需求是否合理,对需求进行评估审核,控制不合理需求。同时借助容量系统对线上资源进行优化。
统计各业务的单 PV / UV 成本、单用户成本、单位调用成本,生成报表,环比同比比较,促进各业务线关注投入产出比。
考察业务资源池容量,业务运营容量,了解业务资源需求,对各业务申请资源进行信用考核,根据业务发展趋势进行预留。
参考云厂商进行国内、海外定价,核算基础成本,对标云厂商进行结算,提高服务能力。
建立容量模型,分析各业务容量瓶颈,过量容量,服务容量,在成本和业务需求的双重约束下,通过配置合理的服务能力使组织的 IT 资源发挥最大效能。
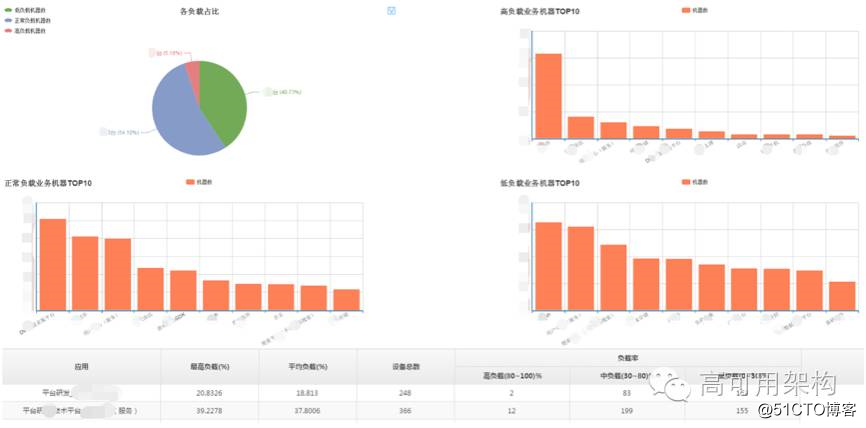
(点击图片可放大浏览)
对于海量规模的互联网业务来说,稍微优化就能节省大量成本,所以已成本导向的驱动力是最大的。
(点击标题可直接阅读)
本文及本次沙龙相关 PPT 链接如下,也可点击阅读原文直接下载
https://pan.baidu.com/s/1geTJtZX
想更多了解高可用架构沙龙内容,请关注「ArchNotes」微信公众号以阅读后续文章。关注公众号并回复 城市圈 可以更及时了解后续活动信息。转载请注明来自高可用架构及包含以下二维码。

从5台服务器到两地三中心:魅族系统运维架构演进之路(含PPT)
标签:linux 活动 img 监控系统 业务 mamicode 定义 inux cdn
原文地址:https://blog.51cto.com/14977574/2547430