标签:分组 region 设计 exp 验证 通讯 情况下 原创文章 方式
跨机房微服务高可用方案:DerbySoft路由服务设计与实现导读:在微服务中,当服务跨多个公有云的可用区时候,我们采用什么样的服务访问策略以及保障其高可用?本文是 DerbySoft 架构师朱攀在高可用架构群的分享,介绍微服务中路由服务的设计。
 朱攀,德比软件架构师,2007 年 2 月加入德比软件。主要负责数据对接平台的架构和实现。作为德比软件早期员工,从无到有的主导了德比软件数据对接平台的架构设计和实现,完成了对接平台多个版本的架构改进和升级。期间设计并实现了很多必要的基础设施和服务,如内部的 RPC 框架 derbysoft-rpc,路由服务 Router,分布式存储服务 DStorage,网关服务 DGateway 等,主要编程语言 Golang,Scala,Java。目前主要关注的方向在基础架构、微服务、大数据等。
朱攀,德比软件架构师,2007 年 2 月加入德比软件。主要负责数据对接平台的架构和实现。作为德比软件早期员工,从无到有的主导了德比软件数据对接平台的架构设计和实现,完成了对接平台多个版本的架构改进和升级。期间设计并实现了很多必要的基础设施和服务,如内部的 RPC 框架 derbysoft-rpc,路由服务 Router,分布式存储服务 DStorage,网关服务 DGateway 等,主要编程语言 Golang,Scala,Java。目前主要关注的方向在基础架构、微服务、大数据等。
我来自德比软件 (DerbySoft),今天跟大家介绍我们做的微服务架构中的路由服务。德比软件是一家旅游行业 B2B 公司,为全球酒店集团及其分销渠道提供数据对接服务,构建全球旅游分销网络( GDN)。目前, 公司拥有全球超过 20 万家酒店数据,每天处理 10 亿 + API 调用,每月处理 500 万 + 间夜的订单。服务的客户包括全球重要地区的顶级分销渠道,在线旅行社,垂直搜索引擎,批发商以及众多大型旅游经销商(如: booking.com, Expedia, Google, Ctrip 等)。
先来看看我们的数据对接平台的一个总体架构图: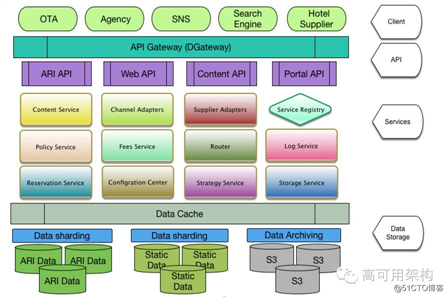
(点击图片可放大浏览)
系统架构不是今天分享的重点,下文主要跟大家交流一下中间服务层中的路由服务( Router)。
微服务化之后,系统面临的一个突出问题是服务虽小,但是数量极多,如果这些服务全部在一个可用区内,服务之间的依赖还比较好管理,可以做服务自动注册和发现来实现依赖管理,但是如果服务分布在很多可用区域,尤其是跨国跨地区的可用区之间的依赖和调用,管理起来就比较麻烦。
下面是我画的一个服务之间的示范依赖图,实际情况的依赖可能会比图示更复杂: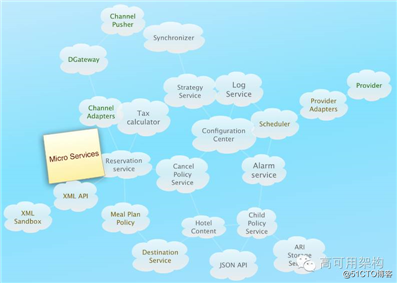
如果这些服务部署分布在不同国家或地区的可用区里,它们之间的依赖调用就更难管理了,另外,跨可用区服务之间的调用还需要考虑安全认证问题。我们内部的通讯协议是 TCP,自研的 RPC 框架 derbysoft-RPC( 多语言实现 ),序列化采用 Protocol Buffers,各个服务采用的主要编程语言有 Golang, Scala, Java 等,每个服务开不同的特殊端口,所有的服务都部署在 AWS 的 EC2 上,如果服务跨区域调用,访问权限配置也是一件麻烦的事情。
下面是引入路由服务之后的服务依赖图: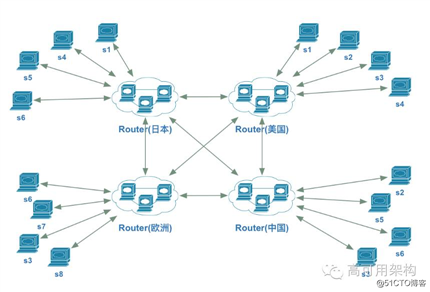
(点击图片可放大浏览)
引入路由之后,所有的服务只和路由通讯,服务之间不再相互依赖,每个服务只需要依赖并维护自己所在的可用区的路由节点,路由会找到调用的服务目的地,绝大部分情况下,它在本区域内就能找到相应的服务,不需要跨区,这取决于服务的部署情况,关键的服务为了提高响应速度,每个可用区都需要部署,这种情况除非本可用区的服务挂了,否则不会出现跨区访问;有些服务不是那么重要,可能只会在某个或某几个可用区部署,这时候就也可能会出现服务跨可用区调用。
同时也解决了 API 访问安全问题,具体做法是:每个可用区建立一个 VPC,所有的服务都在 VPC 内, VPC 内的 API 调用可忽略安全验证,跨 VPC 路由节点之间用安全组来限制 IP 白名单访问,只允许路由节点可以跨可用区访问其他 VPC 内的路由节点,服务访问路由或者路由访问服务都必须在同一个 VPC 用内网地址访问。
路由服务需要实现的主要功能描述:
请求的消息头 (header) 包含以下主要信息:
简单介绍一下里面主要有几个重要字段,服务类型 uri 是各个服务提供者自定义的,服务需求方 source 和服务的提供方 destination,是为了提供一个服务分组的概念,有些服务可能功能相似,它可以在一组,这样可以简化我们的路由表配置。服务响应时间超过 timeout 的值会直接返回超时错误,最大路由次数 routers 是为了防止路由无限次的转发请求找目标服务。
下面是一个路由表的路由规则设计:
router.region1=host:port,host:port //可用区 1 的路由节点地址
router.region2=host:port,host:port //可用区 2 的路由节点地址
router.next=router.region1;router.region2 //下一站路由
source.destination.uri = host1:port1,host2:port2;host3:port3,host4:port4@router.region2
destination.uri = host5:port5,host6:port6@router.region3
uri = host7:port7,host8:port8
先说说“=”前面的 key, key 可以是请求 header 里的 source + destination + uri 的组合,也可以是 destination + uri 的组合,也可以是 uri,组合出来的 key 越长,路由查找时优先级越高, key 还可能是某个可用区的路由节点,每个路由表里面会存储所有可用区的路由节点,“ router.*”表示的是不同可用区的路由节点,“ router.next”表达的是下一站路由。“=”后面是服务地址,最简单的表达可以是 IP 地址+端口号,“ @”后面表示的是这个 IP 属于哪个可用区,如果没有“ @”,表示这个 IP 跟当前路由在同一个可用区;还可以有更复杂一点的表达,有些服务可能好几个可用区都有,这时用“ ;”分隔不同可用区的服务地址,写在前面的,优先级更高,最前面一般配置的是当前路由的可用区或离当前路由比较近的可用区,若当前面可用区的服务不可用,则会将请求转发到后面配置的服务地址的路由。路由服务接收到一个请求后,会用 header 里的信息生成相应的 keys,再根据 key 的优先级查找目的地服务地址,如果找到,则根据规则转发请求,若没找到,则按规则转发请求到“ router.next”配置的路由节点。
路由规则举例:
router.tokyo=54.23.20.245:9999,54.23.20.246:9999
router.oregon=44.20.22.1:9999,44.20.22.2:9999
router.next= router.tokyo;router.oregonbr/>ctrip.hilton.hotel_reservaion_book=10.0.0.3:6001,10.0.0.4:6002;10.1.0.3:6001,10.1.0.4:6002@router.oregon
hilton.hotel_reservaton_cancel=10.1.0.3:6001,10.1.0.4:6002@router.oregon
hotel_policy_tax=10.0.2.1:5005,10.0.3.2:5005
假设以上面路由规则为当前路由的路由表内容,举几个例子来说明一下路由服务的工作原理:
假设一个请求 header 里的 souce = ctrip, destination = hilton, uri = hotel_reservaion_book,路由接收到这个请求后,会生成一个优先级最高的 key = ctrip.hilton.hotel_reservation_book,用这个 key 去路由表查找服务,匹配到了“ 10.0.0.3:6001,10.0.0.4:6002;10.1.0.3:6001,10.1.0.4:6002@router.oregon”,这时路由会优先把请求根据负载均衡策略转发到 10.0.0.3:6001,10.0.0.4:6002 中的某一个,如果 10.0.0.3:6001,10.0.0.4:6002 的服务都不可用,则会转发请求到另一个可用区 router.oregon 的路由节点 44.20.22.1:9999,44.20.22.2:9999 中的一个,由 router.oregon 的路由服务根据其路由表来查找可用服务。
假设一个请求 header 里的 souce = ctrip, destination = hilton, uri = hotel_reservaion_cancel,路由接收到这个请求后,会生成一个优先级最高的 key = ctrip.hilton.hotel_reservation_cancel,用这个 key 去路由表查找服务,结果是没匹配到相应服务,接着会丢掉 source 降优先级生成另一个 key = hilton.hotel_reservation_cancel,匹配到了“ 10.1.0.3:6001,10.1.0.4:6002@router.oregon”,这时路由转发请求到另一个可用区 router.oregon 的路由节点,由 router.oregon 的路由服务根据其路由表来查找可用服务。
假设一个请求 header 里的 souce = ctrip, destination = hilton, uri = hotel_policy_tax,路由接收到这个请求后,会生成一个优先级最高的 key = ctrip.hilton.hotel_policy_tax,用这个 key 去路由表查找服务,结果是没匹配到相应服务,接着会丢掉 source 降优先级生成另一个 key = hilton.hotel_policy_tax,结果还是没有匹配的相应服务,然后会再丢掉 destination 再降优先级生成另一个 key = hotel_policy_tax,匹配到了“ 10.0.2.1:5005,10.0.3.2:5005”,这时路由会根据负载均衡的情况转发请求到其中一个节点上。
假设一个请求 header 里的 souce = ctrip, destination = hilton, uri = hotel_policy_child,路由接收到这个请求后,会生成一个优先级最高的 key = ctrip.hilton.hotel_policy_child,用这个 key 去路由表查找服务,结果是没匹配到相应服务,接着会丢掉 source 降优先级生成另一个 key = hilton.hotel_policy_child,结果还是没有匹配的相应服务,然后会再丢掉 destination 再降优先级生成另一个 key = hotel_policy_child,结果还是没有匹配的服务,最后路由就会用 key = router.next,匹配到了“ router.tokyo;router.oregon”,这时路由会根据根据优先级将请求转发到 router.tokyo 的路由节点。
路由服务本身是高可用的,它只依赖一个路由表,对路由表的依赖我们用了一个配置服务去解决,同一个可用区的所有路由节点共用一个路由表,所有路由节点会向配置中心同步路由表信息并缓存在本机内存中,如果路由表发生变化,所有的路由节点都会更新到。 因为路由有转发功能,所以路由服务也会提供一些类似 RPC 客户端的高可用特征,如:缓存连接、服务故障检测、负载均衡,客户端快速失败。这些都是 RPC 的客户端特性,路由作为一个请求中转服务,也要提供这些基本功能。
特别需要注意的地方,要避免路由表中错误的路由规则导致路由转发死循环而无限消耗资源。请求里 routers 的值是为了快速结束转发,如果请求里面没有设置 routers 的值,则默认值是 3,也就是每个请求路由转发最多不超过 3 次, 3 次以上直接返回路由查找失败。
Q&A
提问:路由规则如何维护?
朱攀:每个可用区的各个服务节点会向配置服务中心注册,配置服务会修改路由表,然后同步到各个路由节点。配置服务的角色类似一个注册中心,负责维护路由表信息。
提问:一个服务需要加一个机器的话,要做什么工作?比如加一个负载机。
朱攀:需要向配置服务注册,配置服务会根据负载机注册的服务,修改路由表,将其加入到相应服务的负载均衡的序列里。
提问:路由是在客户端还是独立的服务单元?
朱攀:路由是独立的服务。
提问:本地的路由如果挂了呢?
朱攀:这种情况很少发生,因为本地路由节点有多个,提供了很大程度的冗余,如果路由节点不可用客户端会很快监测到,除非整个可用区不可用了,比如日本可用区遭遇原子弹袭击,这时候就可能失去了一个可用区的所有服务。但是如果服务部署在各可用区分布的合理,所有服务在其他可用区都有冗余,对客户来说影响还是极小的。
提问:路由会不会成为瓶颈?
朱攀:一般情况不会,路由服务性能很好,同一个可用区内,正常情况路由耗时在 3 毫秒以内,路由服务理论上是可以无限扩容的。
提问:如果跳到下面的时候,指定服务区不可用,会跳到另一个区域,时间和链路会不会很长?
朱攀:请求的 head 里会有超时设置和路由次数限制,一般限制在 3 次,最大不超过 5 次,时间是可控的。极端情况下跳的链路可能会比较长,经过的每一个服务节点,都会记录耗时,并在 response 中返回,超过 timeout 设定值客户端会返回超时。
提问:假如从北京跳到东京,东京的服务没有了,可能新加坡有这个服务,你是如何去选择的呢?
朱攀:如果在路由中配置了新加坡作为服务的备选 LB,则会优先选择新加坡作为跳转,如果没有配置新加坡作为服务的备选,每个路由表会配置一个默认的下一个路由节点,请求会转发到这个默认的路由节点,由这个路由节点再次根据消息头生成 key 查找可用的服务节点。默认的下一跳路由节点是写死在路由表中的,可以配置多个下一跳路由节点保证高可用。
(点击标题可直接阅读)
对上述路由设计有问题或建议欢迎留言。技术原创文章欢迎通过公众号菜单「联系我们」进行投稿。投稿方向包括技术架构类文章、新技术及新实践等。通过的文章会在高可用架构公众号、微博、今日头条等多个媒体发表。投稿需同意相关文章在高可用架构首发。转载请注明来自高可用架构「ArchNotes」微信公众号及包含以下二维码。
跨机房微服务高可用方案:DerbySoft路由服务设计与实现
标签:分组 region 设计 exp 验证 通讯 情况下 原创文章 方式
原文地址:https://blog.51cto.com/14977574/2547428