标签:lse 原理 活动 完成后 部署 写日志 iter cassandra ons
Hadoop namenode高可用性分析:QJM核心源代码解读HDFS namenode 在接受写操作时会记录日志,最早 HDFS 日志写本地,每次重启或出现故障后重启,通过本地镜像文件+操作日志,就能还原到宕机之前的状态,不会出现数据不一致。如果要做高可用 (HA),日志写在单个机器上,这个机器磁盘出现问题,重启就恢复不了,导致数据不一致,出现的现象就是新建的文件不存在,删除成功的还在等诡异现象。这是分布式存储系统不能容忍的。
在单机系统上是通过 WAL(write ahead log)日志来保证出问题后可恢复,在 HDFS 上对应的就是操作日志(EditLog),用于记录每次操作的行为描述。这里我们简单介绍下 editlog 的格式。
文件头:有版本号 + 一个事务头标识
文件内容
1 操作类型 - 占1个字节
2 日志长度 - 占4个字节
3 事务txid - 占8个字节
4 具体内容
5 checksum - 4个字节
文件结尾:一位事务标识
注意之前没有 journal 分布式日志时,每次 flush 日志时在该段日志后面加一个标识 INVALID_TXID,在下次 flush 时会覆盖该标识,但目前的版本去掉了这个标识
通过 editlog 能做到单机版系统的可靠性,但是在分布式环境下,要保证namenode 的高可用,至少需要两台 namemode。要做到高可用,高可靠,首先就是保证 HDFS 的操作日志 (EditLog) 有副本。但有了副本就引入了新的问题,多个副本之间的一致性怎么保证,这是分布式存储必须解决的问题。为此 Clouder 公司开发了 QJM(Quorum Journal Manager)来解决这个问题。
Journal Node 集群
Journal node 是根据 paxos 思想来设计的,只有写到一半以上返回成功,就算本次写成功。所以 journal 需要部署 3 台组成一个集群,核心思想是过半Quorum,异步写到多个 Journal Node。
editlog 写入到多个 node 的过程简单描述如下:
ActiveNamenode 写日志到 Journal Node,采用 RPC 长连接
StandbyNamenode 同步已经 Finally 日志生成镜像文件,以及 Journal Node 直接同步数据,采用 HTTP
ActiveNamenode 每接收到事务请求时,都会先写日志,这个写日志的过程,网上有好多好的文章做分析,这里只是大概说下值得我们学习的地方以及一些好的设计思想。
这个应该说是写日志的通用做法,如果每来一条日志都刷磁盘,效率很低,如果批量刷盘,就能合并很多小 IO(类似 MySQL 的 group commit)
bufCurrent 日志写入缓冲区
bufReady 即将刷磁盘的缓冲区
如果没有双缓冲区,我们写日志缓冲区满了,就要强制刷磁盘,我们知道刷磁盘不仅是写到操作系统内核缓冲区,还要刷到磁盘设备上,这是相当费时的操作,引入双缓冲区,在刷磁盘操作和写日志操作可以并发执行,大大提高了Namenode的吞吐量。
恢复数据是在 Active Namenode crash 后,standby namenode 接管后,需要变为 Active Namenode 后需要做的第一件事就是恢复前任 active namenode crash 时导致 editlog 在 journal node 的数据不一致。所以在 standby node 可以正式对外宣布可以工作时,需要让 journal node 集群的数据达到一致,下面主要分析恢复算法,恢复算法官方说是根据 multi paxos 算法。
Paxos 协议是分布式系统里面最为复杂的一个协议,网上主要都是讲概念和理论,不较少讲实践的,所以写本文也是为了更好的理 paxos。paxos 的资料网上很多,可以看登博最近分享的 ppt,讲得很通俗易懂的。
Multi Paxos 是 paxos 改进版,因为 Basic paxos 每一轮 paxos 都生成一个新的 proposal,这一般是由多点写,就像 zk Leader 选举,每个人都可以发起选举。但我们大多数分布式系统都有一个 leader,并且都是有 leader 发起 proposal,那后面就可以用第一次 proposal number,就直接执行 accept 阶段,从 qjm 这个实践里看,有点类似 RAFT 了,都有 leader 的角色。重用当前的提案编号 epoch
恢复数据过程:
1 隔离
2 选择恢复源
3 恢复
开始恢复前需要对前任隔离起来,防止他突然间复活,导致脑裂。隔离的措施是 newEpoch,重新生成一个新的 epoch,算法是通过计算所有 jn 节点中最大的一个,加 1,然后让命令 journal node 集群更新 epoch。更新后,如果前任复活,也不能向 journal node 集群写数据了,因为他的 epoch 比 journal 集群小,都会被拒绝。
生成新的 Epoch 代码如下: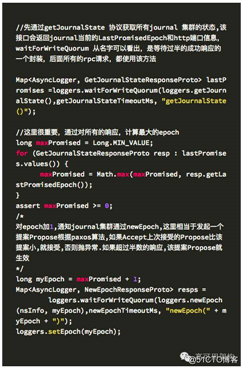
拒绝的代码如下: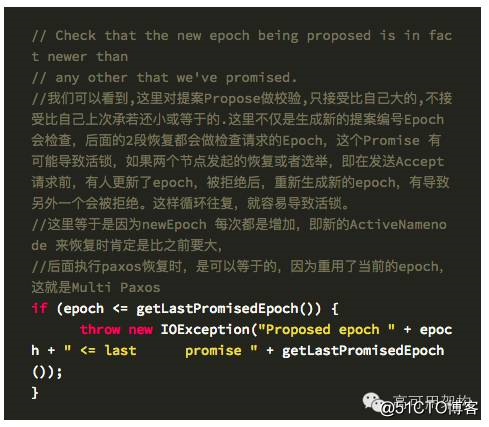
2 选择一个恢复源
隔离成功后,需要选择一个副本来恢复,每个 journal 的最新的 segment 文件不一致,因为 namenode crash 的时间不同而不同。所以需要从 journal 集群中最新的副本的信息。
隔离成功后,就开始恢复。在分布式系统,为了使各个节点的数据达成一致,经典的算法还是 Paxos,根据Paxos,分为 2 阶段分别说明如下:QJM 的两阶段对应的是 PrepareRecover 和 AccepteRecover,注意这里说是 Paxos 上文说是 Multi Paxos,区别就是 epoch 重用的。核心算法还是 Paxos。
3.1 PrepareRecovery
向所有 journal node 发送提议,并选中一个恢复的 segment,返回 segment 如下信息:
3.2 AccepteRecovery
根据 PrepareRecovery 选择的结果根据一个算法,选中一个segment,给所有的journal 发送 accept 请求,告诉他们都要和指定的 segment 达到一致,怎么样达成一致,下面会分析到。
PrepareRecover 对应 Paxos 的第一阶段,AccepteRecover 对应第二阶段
在分析具体的2PC实现之前,先上个图,了解下大概流程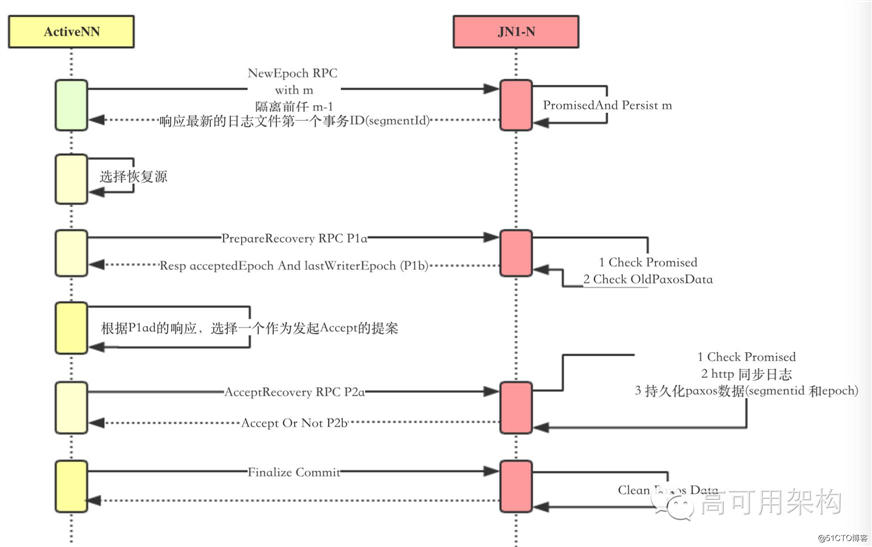
上图主要包含的流程总结如下
这里分别对每个阶段的主要行为分析如下:
PrepareRecoverRequest(P1a)
第一阶段,发起提案
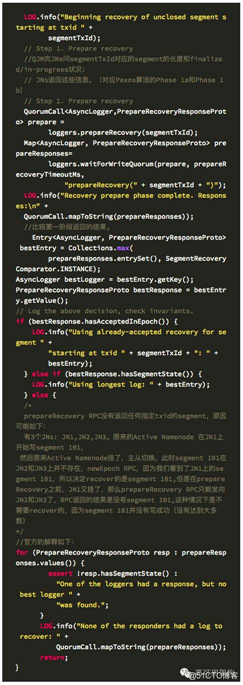
服务端 Journal(prepareResponse) P1b:
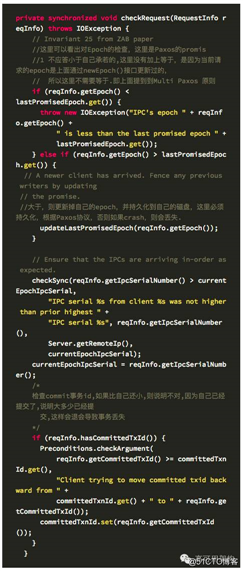
checkRequest
journal 在newEpoch,发起提案,接受提案都通过 checkRequest 来检查提案编号epoch,的合法性,并做对应的操作
选择一个 segment 来做为同步源
第一阶段准备恢复完成后,如果超过半数以上的节点返回,则需要从这些返回的日志文件segment中选择一个最合适的副本。下面就是选择算法
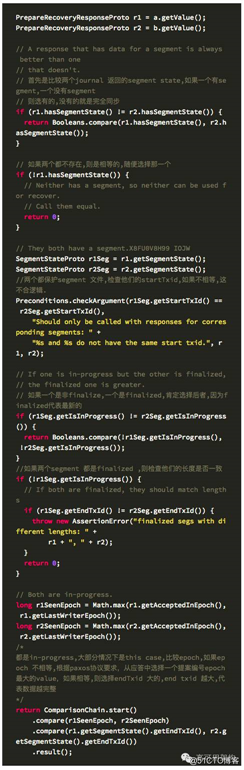
第一阶段完成即根据提案的响应从中选择一个 value,作为发起 accept 请求的提案,选择算法上面已经描述,接下来就发发起 accept 请求。
Journal接受AcceptRecovery请求(P2b)
accept 阶段需要对提案编号 epoch 检查,因为在提案阶段做了承若。

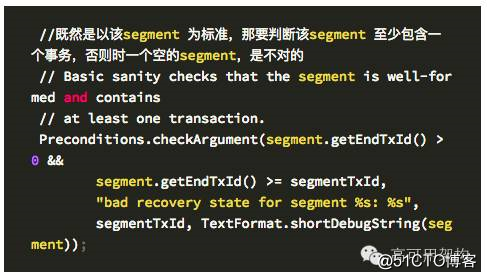
检查是否存在上次没有恢复完成的数据,即上轮 paxos 失败了,又发起了新的恢复这里是检查上轮 paxos 实例是否做完,正确退出;如果没有正常退出,则需要判断提案编号,如果本次 accept 的编号 epoch 小于上轮 paxos 的 epoch,则不对。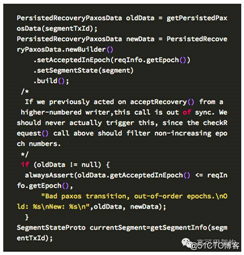
1.currentSegment is null,这种情况是 active namenode 还没有发送日志到该 journal 时就 crash了,而且是一个新的 segment
2.文件存在,但是 segment 的长度和需要恢复的 segment 长度不一致
客户端 恢复成功后,超过半数成功返回,则做 finalize
accept 成功后,做第三阶段,commit,这里是 finalize 操作,对文件进行重命名,以便被 namenode 读取

Journal Node 故障的情况
分布式日志系统,除了正常情况下的逻辑处理,更重要的是怎么容灾,如果超过一半,直接不写,因为 QJM 核心就是过半,但如果只是其中一个出现故障,是可以容忍的。
在其中一个 Journal Node Crash 的情况下, QJM 就不会往该故障的 Journal Node 发送日志流了,并标记 outOfSync 为 true, 在什么时候会重新往该节点发送数据呢?会在写新的日志文件时即 startLogSegment RPC 请求的时候,请求成功后,会检查对应的节点 outOfSync 是否为 true,如果是,则重新标记 false,让其开始接受日志,如果在写日志的过程中,有一个节点临时故障,比如网断,后面又恢复,在写新的日志文件之前, QJM 只是会发心跳给写过程中失败的节点,并带上当前的事务 ID(txid),并不立即开始写,可以想下,如果是立即就写,会出现什么情况? 至少会出现事务断层的现象,因为在出现故障期间的事务都没有写到该节点。
关于作者
彭荣新,上海欧电云信息科技有限公司架构师,个人对分布式存储,并发等底层相关的技术比较感兴趣,一直在学习的路上。
技术原创及架构实践文章,欢迎通过公众号菜单「联系我们」进行投稿。转载请注明来自高可用架构「ArchNotes」微信公众号及包含以下二维码。

长按二维码 关注「高可用架构」公众号
年底重磅:高可用架构主办 GIAC 全球互联网架构大会,推动技术架构未来,点击阅读原文进入活动报名页面。
Hadoop namenode高可用性分析:QJM核心源代码解读
标签:lse 原理 活动 完成后 部署 写日志 iter cassandra ons
原文地址:https://blog.51cto.com/14977574/2547422
