标签:定义 tor air 头信息 修改 vcc 保护 增删改查 str
7-10倍写入性能提升:剖析WiredTiger数据页无锁及压缩黑科技导语:计算机硬件在飞速发展,数据规模在急速膨胀,但是数据库仍然使用是十年以前的架构体系,WiredTiger 尝试打破这一切,充分利用多核与大内存时代来重新设计数据库引擎,达到 7 - 10 倍写入性能提升。本文由袁荣喜向「高可用架构」投稿,通过分析 WiredTiger 源代码,剖析其卓越性能的背后实现。
 袁荣喜,学霸君工程师,2015年加入学霸君,负责学霸君的网络实时传输和分布式系统的架构设计和实现,专注于基础技术领域,在网络传输、数据库内核、分布式系统和并发编程方面有一定了解。
袁荣喜,学霸君工程师,2015年加入学霸君,负责学霸君的网络实时传输和分布式系统的架构设计和实现,专注于基础技术领域,在网络传输、数据库内核、分布式系统和并发编程方面有一定了解。
在 MongoDB 新存储引擎 WiredTiger 实现(事务篇)一文中提到了 WiredTiger(简称为 WT)是为了适应现代 CPU、内存和磁盘的特性而设计的存储引擎,它的特点就是充分利用 CPU 的速度和内存的容量来弥补磁盘访问速度不足。
在介绍 WiredTiger 的数据组织前,先来看看传统数据库引擎的数据组织方式,一般存储引擎都是采用 btree 或者 lsm tree 来实现索引,但是索引的最小单位不是 K/V 记录对象,而是数据页,数据页的组织关系实现就是存储引擎的数据组织方式。
传统数据库引擎大都是设计一个磁盘和内存完全一样的数据组织方式,这个结构是固定的空间大小(innodb 的 page 是 16KB),访问它必须遵守严格的 The FIX Rules 规则:
WiredTiger 没有像传统的数据库引擎那样设计一套内存和磁盘 page 完全一致的数据组织方式,而是针对磁盘和 CPU、内存三者之间特点设计了一套独特的数据组织方式。
这种数据组织结构分为两部分:
WiredTiger 内存中的 page 是一个松散自由的数据结构,而磁盘上的 extent 只是一个变长的序列化后的数据块,这样做的目的(设计目标)有以下几点:
1.内存中的 page 松散结构可以不受磁盘存储方式的限制和 The FIX Rules 规则的影响,可以自由的构建 page 无锁多核并发结构,充分发挥 CPU 多核的能力。
2.可以自由的在内存 page 和磁盘 extent 之间实现数据压缩,提高磁盘的存储效率和减少 I/O 访问时间。
关于 WiredTiger 的压缩效率见下图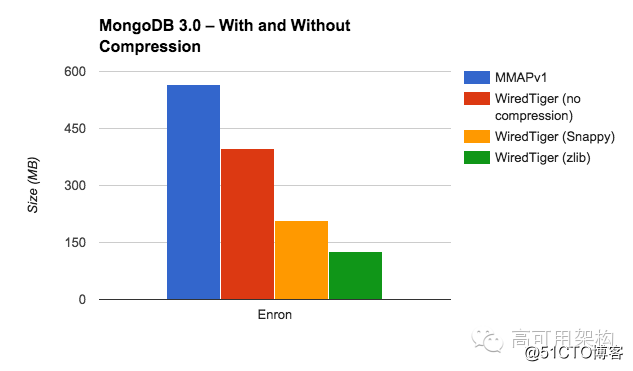
图1
Page 在 WiredTiger 引擎中起着承上启下的作用,上通索引、事务和 LRU cache,下达文件、高速缓冲和磁盘 I/O。要了解整个 WiredTiger 引擎的原理,首先要理解它的数据组织方式。
在本文中先通过一组测试样例来验证 WiredTiger 数据组织的设计目标,再分析 WiredTiger 数据组织的原理和实现。
先来看看 WiredTiger 这种数据组织的相关测试,我们在一个普通的开发机器上对 WiredTiger 的原生 API 接口进行测试,测试环境如下:
CPU: i7-4710MQ CPU @ 2.50GHz,8核
内存:4G
硬盘:1TB SATA,5400转
WT数据库配置:
Cache size: 1GB, page max size:64KB, OS page cache:1GB
Key:一个从零开始自增长的整数
Value:一个长度介于100 ~ 200的随机字符串。
测试程序先新建一张表,用 16 条线程并发向表中插入指定数量(以百万为单位)的 K/V 对,在插入完成后做一次 checkpoint 让插入的数据写入磁盘,统计这个表在磁盘上的大小和这个过程的耗时。再用 16 条线程在表中随机查询 20000 个不同 K/V 并统计查询的耗时,通过耗时可以计算出 insert 和 query 的 TPS。统计的这三个参数分别就是磁盘空间占用、写性能和读性能。
我们分别进行不压缩 extent 的测试和进行 ZIP 压缩 extent 的测试。
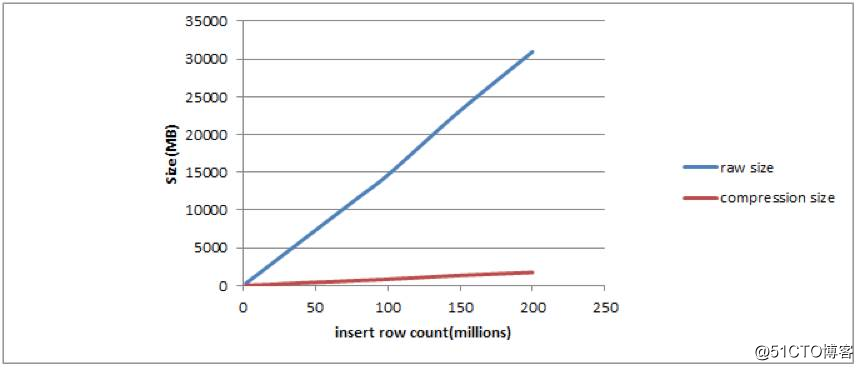
图2
从上图可以看出 2 亿条记录,没有压缩的磁盘空间 30GB,而压缩后的磁盘空间 2GB 左右。
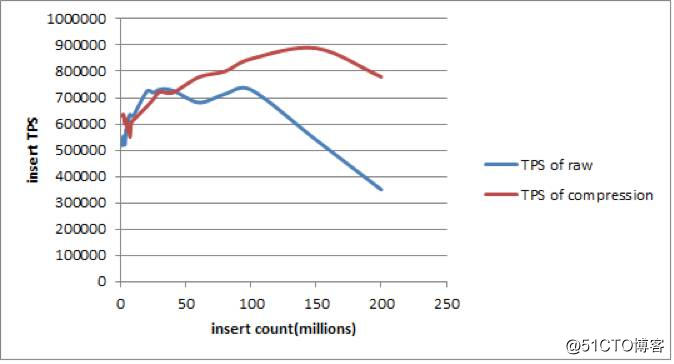
图3
从上图可以看出,写入的数据在 1亿条(14GB),压缩(518K TPS)和没压缩(631k TPS)的写性能相当。
但随着数据量增大,大量的数据在内存和磁盘间 swap,选择 extent 压缩的写性能(790K TPS)要好于没压缩的写性能(351K TPS)。
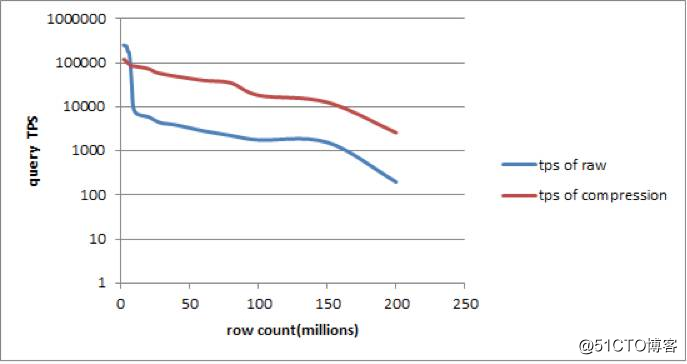
图4
从上图可以得出,在表空间文件上的数据大小没有超过 WiredTiger 的 OS_page_cache 限制时,无压缩的读性能要好于有压缩的读性能,这是因为 extent 缓冲在操作系统高速缓冲区中,当发生访问时从高速缓冲区直接获取无压缩 extent 转换成内存中的 page,只要一次内存中的结构重建即可;而压缩的 extent 需要进行解压缩后再重建,所以没有压缩的读性能更好。
如果文件数据大小超出 OS_page_cache 限制后,extent 数据要从磁盘上读取,而有压缩的 extent 占用的空间比较小,从磁盘上读取的 I/O 访问时间是小于无压缩读取的时间的,这时有压缩的读性能要好于无压缩的读性能(后面单独用一个篇幅来分析 WT 的磁盘 I/O 相关的实现)。
除了压缩优化了数据的读写,WiredTiger 内存中的无锁 page 结构也使得读写操作具有更好的并发性,才使得 WiredTiger 在非常普通机器上有如此好的表现。
通过上面的介绍已经对 WiredTiger 的数据组织基本的了解,WiredTiger 数据组织方式就是 in-memory page 加 block-extent。先来对它内存部分的 in-memory page(内存数据页,简称为 page)来做分析。
WiredTiger 引擎中的 page 分以下几类:
因为 MongoDB 主要是使用行存储,所以在这里主要分析 row leaf page 这个结构和原理,结构图如下: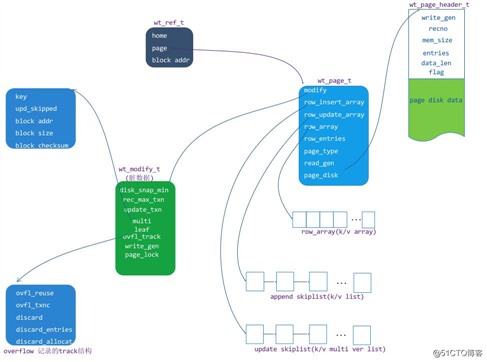
图5 点击图片可以全屏缩放
上图中主要有以下几个单元:
罗列了这么多结构,他们之间是通过什么方式来关联的呢?
我们通过一个实例来说明,假如一个 page 存储了一个 [0,100] 的 key 范围,磁盘上原来存储的行 key=2, 10 ,20, 30 , 50, 80, 90,他们的值分别是value = 102, 110, 120, 130, 150, 180, 190。
在 page 数据从磁盘读到内存后,分别对 key=20 的 value 进行了两次修改,两次修改的值是分别 402,502。对 key = 20 ,50 的 value 做了一次修改,修改后的 value = 122, 155,后有分配 insert 了新的 key = 3,5, 41, 99,value = 203,205,241,299。
那么在内存中的 page 就是如下图组织数据的: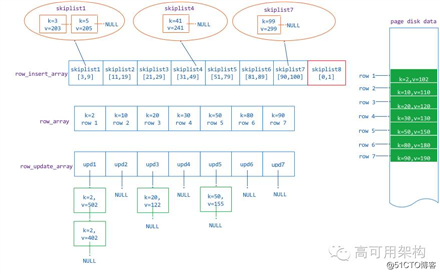
图6 点击图片可以全屏缩放
row_array 的长度是根据 page 从磁盘中读取出来的行数确定的,每个数组单元(wt_row)存储的是这个 kv row 在 page_disk_data 缓冲区偏移的位置和编码方式(这个位置和编码方式在 WT 上定义成一个 wt_cell 对象,在后面的 K/V cell章节来分析),通过这个信息偏移位置信息就可以访问到这一样在 disk_data缓冲区中的 K/V 内容值。
每一个 wt_row 对象在 row_update_array 数组中对应一个 mvcc list 对象,mvcc_list 与 wt_row 是一一对应的,mvcc list 当中存储对 wt_row 修改的值,修改的值包括值更新和值删除,是一个无锁单向链表。
相邻的两 wt_row 之间可能不是连续的,他们之间可以插入新的单元,例如 row1(key = 2) 和 row2(key=10) 可以插入 3 和 5,这两个 row 之间需要有一个排序的数据结构(WT用 skiplist 数据结构)来存储插入的 K/V,就需要一个 skiplist 对象数组 page_insert_array与row array对应。这里需要说明的是 图6 当中红色框当中的 skiplist8,它是用于存储 row1(key=2) 范围之前的 insert 数据,图6 中如果有 key =1 的数据 insert,那么这个数据会新增到 skiplist8 当中。
那么 图6 中 row 与 insert skiplist 的对应关系就是:
从上面对应 page 的整体分析来看在 WT 的 page 中,row 对象是整个 row leaf page 的关键结构,row 其实就是 K/V 位置的描述值(kv_pos),它的定义:
wt_row{
uint64 kv_pos;//这个值是在page读入内存时根据KV存储在page_disk的位置确定的
}
这个 kv_pos 的对应的数据有对应的 K/V 存储位置信息,kv_pos 表示这个 K/V 的值有三种方式,结构如下图: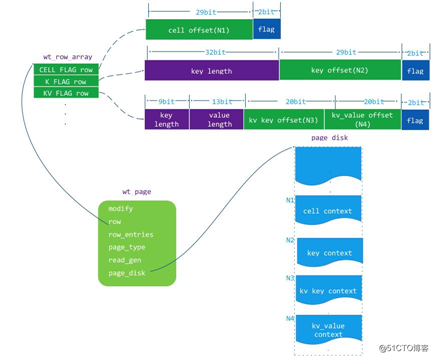
图7 点击图片可以全屏缩放
上图中的 wt_row 对应的空间上都有 2 个 bit 的 flag,这个 flag 的值:
Cell 是一个值 key 或者 value 信息被序列化后的数据块,cell 在磁盘上和在内存中内容是一致的,它是根据值(key 或者 value)内容、长度、值类型序列化构建的。在内存中 cell 是存储在 page_disk 缓冲区中,在磁盘上是存储在 extent body 上,在读取 cell 的时候需要根据 cell 数据内容进行发序列化得到一个 cell_unpack 内存结构对象,让后再根据这个 cell_unpack 对象中的内容来读取这个值(key 或者 value)。以下是它们之间的结构关系: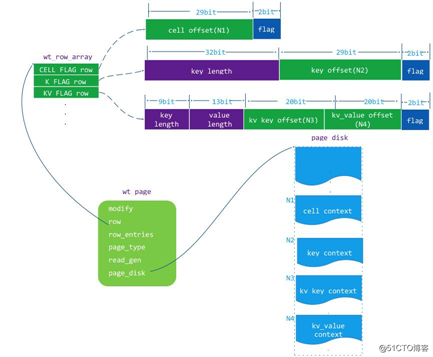
图8 点击图片可以全屏缩放
那么在 row 对象中的 CELL_FLAG row、K_FLAG row 和 KV_FLAG row 对应的值是怎么产生的呢?
其实是在 page 的数据从磁盘读到内存中时,先会对整个 page_disk 按照 cell 为单位转化成 cell_unpack,并根据 cell_unpack 中的信息构造 row 的这三种格式,这样做的目的是让能生成 K_FLAG /KV_FLAG 的 row 在每次被访问的时候不需要去做这个过程的转化,加快访问速度。
内存中的 row 对象主要是为了帮助 page 数据从磁盘上载入到内存中后建立查询索引,而 page 数据被载入内存后除了查询读以外,还会对其进行修改行为(增删改),对于修改行为 WT 并没有在 row 内存结构上进行操作,而是设计两个结构,一个是针对 insert 操作的 insert_skiplist,一个针对删改操作的 mvcc list。关于这两个对象结构与 row 之间的关系在 图6 中有过描述。在这里重点来分析它们的内部构造和运行原理。
从前面的介绍知道 page 在内存中存储新增的 k/v 时采用的是 skiplist 数据结构,在 WiredTiger 中不仅仅这个地方使用了 skiplist,在其他需要快速查询和增删的地方基本上都使用了 skiplist,了解 skiplist 的原理有利于理解 WiredTiger 的实现。
skiplist 其实是个多层链表,层级越高越稀疏,最底层是个普通的链表。 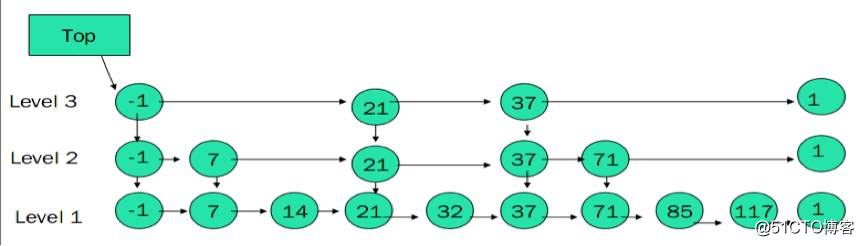
图9
skiplist 原理参看 https://en.wikipedia.org/wiki/Skip_list
skiplist 实现参看 https://github.com/yuanrongxi/wb-skiplist
WiredTiger 中 insert_skiplist 实现时是结合了它本身的 k/v 内存结构来实现的,WT 基于skiplist定义了一个 wt_insert 的 k/v 跳表单元结构,定义如下:
wt_insert{
key_offset://存储key的缓冲区偏移
key_size://key的长度
value://存储值的mvcc list的头单元,一个wt_update结构对象
next[]://skiplist的各层的下一个单元指针
key_data[]://存储key的缓冲区
}
insert_skiplist 的结构示意图: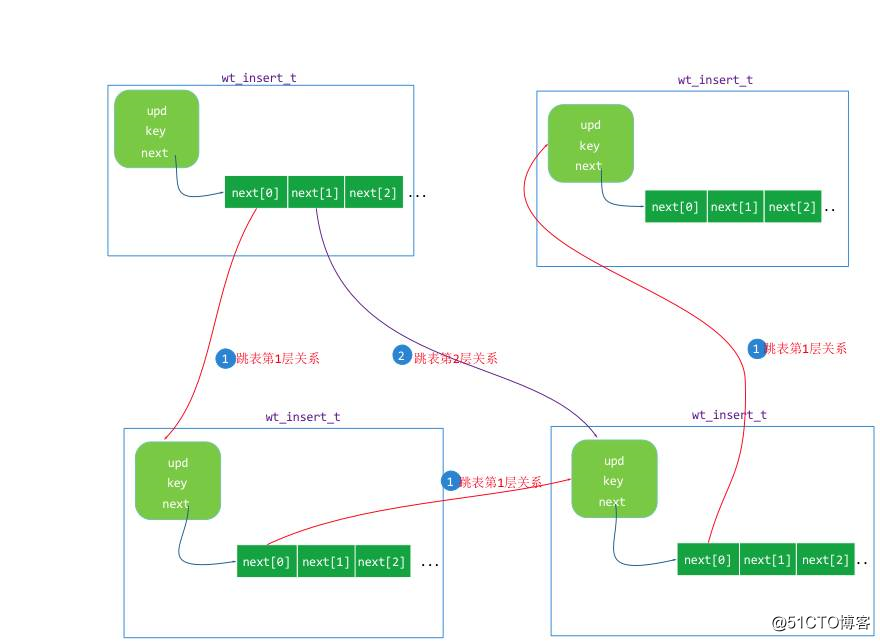
图10 点击图片可以全屏缩放
WiredTiger 为什么选用 skiplist 来作为新增记录的数据结构?主要是几个方面的考虑:
WiredTiger 引擎在 insert 一个 k/v 时,key 值是存储在 wt_insert 中,那么它的 value 存储在什么地方?
在 wt_insert 结构中有一个 wt_update 类型的 value 说明,这个结构其实就是来存储内存中各个修改版本的 value 值的链表对象,也就是提到的 MVCC list 链表。在 图6 中也有提到 row 更新的时候,会向 row_update_array 对应的 mvcc list 当中加入更新的值单元(wt_update),这个结构的定义如下:
wt_update{
txnid://产生修改的事务ID
next ptr://链表的下一个wt_update单元指针
size://value值长度
value[]://存储value的缓冲区
}
size = 0,表示这个是一个删除 k/v 的修改。
图11(mvcc list)
整个链表在平常情况下只会进行 append 操作,而且每次 append 都是在链表头的位置,这样做的目的是为了整个链表的无锁读写操作。这里涉及无锁读好理解,只要做到无锁 append 就可以做到无锁读。mvcc list 无锁 append 采用的是 CPU 的 CAS 操作来完成,大致的步骤如下:
第 2 步的判断是否有其他线程先以自己设置 list_header 的依据就是 CAS_SWAP 时 list_header 的值不是自己读取到值。关于这个过程更多的细节可以去了解GCC 编译器的 __sync_val_compare_and_swap 函数功能和实现。
WiredTiger 支持是支持超大的 K/V,key 和 value 的值最大可以到 4GB(其实不到 4G,大概是 4GB - 1KB,因为除了数据外还需要存储 page 头信息)。
WiredTiger 通过定义一种叫做 overflow page 来存储超出 leaf page 最大存储范围的超大 k/v。超大的 k/v 在 insert 到 leaf page 还是存储在 insert_skiplist 当中,只有当这个 leaf page 进行存盘的时候,WT 会对超出 page 允许的最大空间的 k/v 值用单独的 overflow page 来存储,overflow page 在磁盘文件中有自己单独的 extent。
那么什么时候在内存中会出现 overflow page 呢?在用于 overflow page 的 leaf page 从磁盘上读入内存中时会构建对应的 overflow page内存对象。overflow page 本身的结构很简单,就是一个 page_header 和一个 page_disk 缓冲区。leaf page 与 overflow page 之间通过 row cell 信息来关联,cell 里面存有这个 overflow page 的 extent address 信息。
为了对 overflow page 的快速访问,WT 定义了一个的 skiplist(extent address与overflow page内存对象映射关系)来缓存内存中的 overflow page 内存对象,对 overflow page 的读流程如下:
这里提到的 extent address 参考下面的 extent addresss 结构章节。
WiredTiger 实现松散的内存 page 结构为的就是能快速检索和修改,也使得数据在内存中的组织方式更加自由。不管是读还是修改,需要依赖 page 的页内检索,在读取或者修改某个 k/v 值前需要根据对应的 key 在 page 内部做一次检索来定位 k/v 的位置,而整个页内检索的核心参考轴是通 row_array 这个数组做二分查找来定位的。
在这里还是以 图6 来进行说明,假设需要在 图6 中查找 key=41 的值,步骤如下:
1.先通过二分法在 row_array 定位到存储 key = 41 的对象 row4
2.定位到 row4 后先匹配 row key 与检索的 key 是否匹配,如果匹配,在 row4 对应的 mvcc list(upd4)中读取可以访问的值。如果不匹配,在其对应的 insert_skiplist 进行查找
3.用 key = 41 在跳表 skiplist4 进行查找,定位到 value = 241,返回。
因为都是 row_array/insert_array/update_array 数组一一对应的查找,而且这些数组的在发生修改时也不会发生改变,所以不需要对其进行锁保护,insert_skiplist 和 mvcc list 都是支持修改时无锁读取的(这个在分析这两个结构时已经说明过),所以说整个检索过程是无锁的。
如果是增删改(insert/delete/update)操作,也是先用检索过程找到对应修改的位置,再进行对应修改。如果是 insert,或获取 wt_modify 中的 page_lock 来串行化 insert 操作,如果是对值进行 update/delete,只是在 mvcc list 无锁增加一个修改后的值即可(这个过程在上面已经分析过)。
Page 在磁盘上文件上对应的结构叫做 extent。其实它就是磁盘文件上的一块区域。
在 WT 引擎中,每一个索引对应一个文件,文件中按照 page 写入的大小和当前文件被使用的空间来确定写入的位置和写入的长度,写入的位置(offset)和写入的长度(size)被命名成 extent,并且将 extent 的位置信息(extent address)记录到一个索引空间中。
Extent 由三部分构成,他们分别是
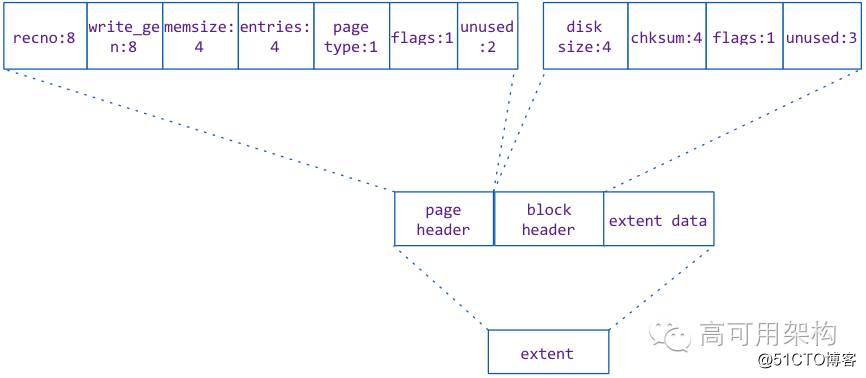
图12 点击图片可以全屏缩放
page header 在 page 的内存对象中,对应的是 page_disk 的头信息部分 wt_page_header,他们的内容是完全一致的。page header 包含当前 page 的记录实例数(entries)、page类型(row leaf page/internal page等),在 page 数据载入内存时需要用这些数据来构建 page 内存对象。
Block header 中的 checksum 是 extent data 的数据 checksum,也是 extent address 中的 checksum。用于 extent 读入内存时做合法性校验。
Extent address 用于索引 extent 的信息,它作为一个数据条目存在一个特殊的索引 extent 中(关于这个特殊的索引 extent 在后续的磁盘 I/O 篇来详细分析)。
这里主要分析下它的内部构造和定义,extent address 中有三个值:
这三个值是序列化后作为 extent address 条目存储的。
Extent data 是真正存储 page 数据的地方,它是 page 中所有 k/v cell 的集合。Page 数据从内存存入磁盘时,会将每个 k/v pair 用 cell_pack 函数转化成一个 key cell 和一个 value cell 存入序列化缓冲区中。这个缓冲区的数据写入到 extent 中就是 extent data,存储结构如下图:
图13
btree 索引管理的最小单元是 page,那么从磁盘到内存的读操作和从内存到磁盘的写操作都是以 page 为单位来读写。
在 WT 引擎中从磁盘读取一个页到内存的操作叫做 in-memory,从内存 page 写入磁盘的操作叫做 reconcile。in-memory 过程就是将 extent 从磁盘文件中读取出来转换成内存 page ,而 reconcile 操作就是将内存中的 page 转换成 extent 写入到磁盘上,reconcile 过程会造成 btree page 的分裂。
读写序列图如下: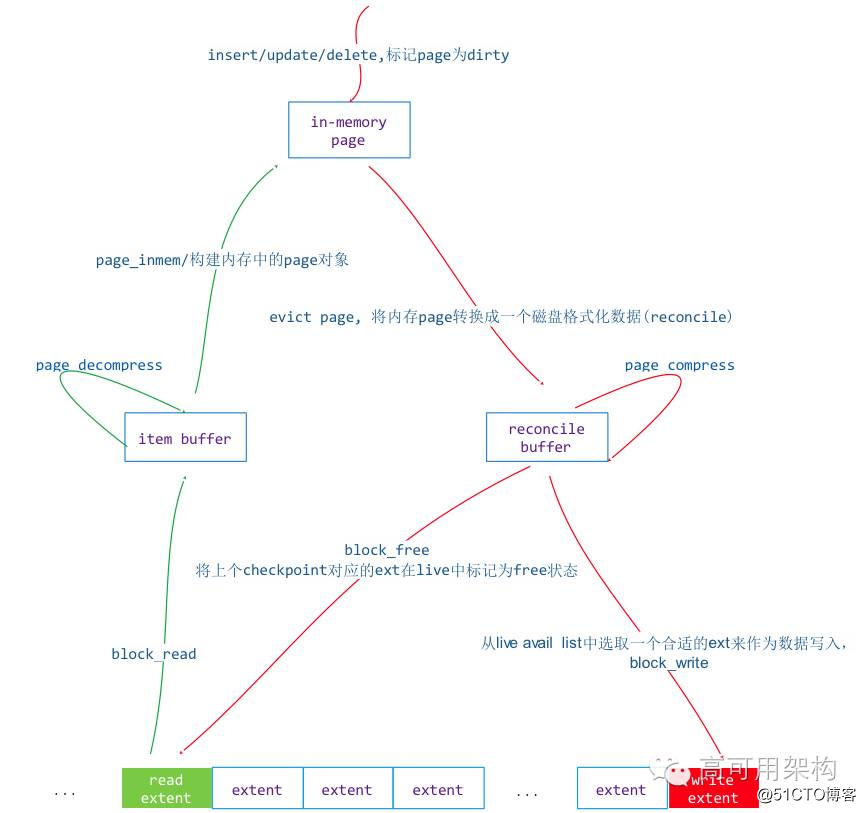
图14 点击图片可以全屏缩放
Page 的读过程是磁盘到内存的过程,步骤如下:
如果读入的 page 包含 olverflow page,overflow page 并不会在这个过程中读取到内存中,而是在访问它的时候读取到内存中的,这个过程只会读取 overflow page 对应的 extent address 作为 row 对象的内容。在 overflow page 一节分析过 overflow page 的读取过程。
写过程比较复杂,page 的写过程如果 page 的内存空间过大会对 page 做 split 操作,对于超过 page 容忍的大 K/V 会生成 overflow page。整个写过程步骤如下:
根据 btree 文件的偏移和空间状态产生一个 extent,计算 data buffer 的 checksum,并将 data buffer 填充到 extent data 当中。
根据 extent 的信息填充 block_header,将整个 externt 写入到 btree 的文件当中并返回 extent address。
通过 page 的读写过程分析知道这两个过程如果配置了压缩,就需要调用压缩解压缩操作。WT 实现压缩和解压缩是通过一个外部自定义的插件对象来实现的,下面是这个对象的接口定义
__wt_compressor{
compress_func();//压缩接口函数
pre_size_func();//预计算压缩后数据长度接口函数
decompress_func();//解压缩接口函数
terminate_func();//销毁压缩对象,有点像析构函数
};
WT 提供 LZO/ZIP/snappy 这几个压缩算法,也支持自定义压缩算法,只要按照上面的对象接口实现即可。要让 WT 支持压缩算法,需要在 WT 启动时通过 wiredtiger_open 加载压缩算法模块,例子如下:
wiredtiger_open(db_path, NULL, “extensions=[/usr/local/lib/libwiredtiger_zlib.so]”,&connection);
然后在 WT 引擎创建表时可以配置压缩启用压缩配置即可,例如:
session->create(session, “mytable”, “block_compressor=zlib”);
WT 的插件式压缩非常灵活和方便,MongoDB 默认支持 ZIP 和 snappy 压缩,在 MongoDB 创建 collection 时是可以进行选择压缩算法。
WiredTiger 引擎采用内存和磁盘上不同的结构来实现 page 的数据组织,目标还是让内存中的 page 结构更加方便在 CPU 多核下的增删查改的并发操作,精简磁盘上的 extent 结构,让磁盘上的表空间管理不受内存结构的影响。基于 extent(偏移 + 数据长度)的方式也让 WiredTiger 引擎的数据文件结构更简便,可以轻松实现数据压缩。
然而这种内存和磁盘上结构不一致的设计也有不好的地方,数据从磁盘到内存或者从内存到磁盘需要多次拷贝,中间还需要额外的内存作为这两种结构的临时缓冲区,在物理内存不足的情况下会让 swap 问题雪上加霜,性能会急剧下降,这个在测试样例里面有体现。所以要让 WiredTiger 引擎发挥好的性能,尽让配备更大物理内存给它使用。
MongoDB 3.2 版本已经将 WiredTiger 作为默认引擎,我们在使用 MongoDB 时一般不会对 WiredTiger 做配置,这可能会有些业务场景发挥不出 WiredTiger 的优势。MongoDB 在创建 collection 时可以对 WiredTiger 的表做配置,格式如下:
db.createCollection("<collectionName>", {storageEngine: {
wiredtiger: {configString:"<option>=<setting>,<option>=<setting>"}}});
不同的业务场景是可以配置进行不同的配置。
如果是读多写少的表在创建时我们可以尽量将 page size 设置的比较小 ,比如 16KB,如果表数据量不太大(<2G),甚至可以不开启压缩。那么 createCollection 的 configString 可以这样设置:
"internal_page_max=16KB,leaf_page_max=16KB,leaf_value_max=8KB,os_cache_max=1GB"
如果这个读多写少的表数据量比较大,可以为其设置一个压缩算法,例如:
"block_compressor=zlib, internal_page_max=16KB,leaf_page_max=16KB,leaf_value_max=8KB"
如果是写多读少的表,可以将 leaf_page_max 设置到 1MB,并开启压缩算法,也可以为其制定操作系统层面 page cache 大小的 os_cache_max 值,让它不会占用太多的 page cache 内存,防止影响读操作。
这些 MongoDB 的配置项都是和 WiredTiger 引擎数据组织相关的配置项,在了解 WiredTiger 的数据组织方式细节情况下,可以根据具体的业务场景调整 collection 的表配置属性。
以上是通过分析和测试 WiredTiger 源码得到的一些认识,有些细节可能会有差错,但大体是这样的工作原理。对 WiredTiger 源码感兴趣的同学戳这里 https://github.com/yuanrongxi/wiredtiger,我花了些时间对 WiredTiger-2.5.3 的源码做了分析和注释。
后续工作是对 WiredTiger 的索引(btree/LSM tree)和磁盘 I/O 相关的模块做深入的分析和测试,会不定时的把分析的心得分享出来。

MongoDB 新存储引擎 WiredTiger 实现(事务篇)
MongoDB 2015 回顾:全新里程碑式的 WiredTiger 存储引擎
对 WiredTiger 及 MongoDB 引擎设计及使用感兴趣的同学,欢迎在本文留言,介绍对 WiredTiger/MongoDB 的使用及了解,我们将邀请评论中有意向的同学与本文作者及业内相关专家在 『高可用架构—WiredTiger/MongoDB』 微信群进行交流。
技术原创及架构实践文章,欢迎通过公众号菜单「联系我们」进行投稿。转载请注明来自高可用架构「ArchNotes」微信公众号及包含以下二维码。

长按二维码 关注「高可用架构」公众号
7-10倍写入性能提升:剖析WiredTiger数据页无锁及压缩黑科技
标签:定义 tor air 头信息 修改 vcc 保护 增删改查 str
原文地址:https://blog.51cto.com/14977574/2547552