标签:定位 取数据 api park from 图片 外部 问题排查 均衡
排查Spark Streaming处理耗时问题,首先将driver,executor的日志调整为DEBUG级别。分别从driver端和executor端直接查看日志是否存在Exception,Warn级别的异常日志。从日志中看到异常日志后,从Spark角度分析排查问题,基本思路分三个步骤,分别是数据读取阶段,数据处理阶段和数据输出阶段。
1、数据读取阶段,比方说从上游Kafka读取数据,工作中遇到的一些情形,
例如:Kafka所在服务器宽带限制影响了数据读取;Kafka某个节点性能(磁盘)问题影响单个节点数据拉取等。
这些情况都可以从Kafka组件的监控和服务器监控中进行问题排查
2、数据处理阶段,数据处理过程由不同算子串联起来的Stage,排查这些Stage中
a、是否有外部接口的依赖,http请求接口超时
b、Task中数据不均衡(Web UI中可以看到),同一batch的任务中,一些Task处理1条记录,一些Task处理100条记录
排查问题思路:添加宽依赖算子(repartition等),将一个Stage拆分成多个Stage,定位耗时Stage。
比如如下DAG显示,加入Stage 0耗时30s,不易判断是哪个环节出现问题。针对上面这种情况,添加宽依赖算子将DAG拆分成多个Stage,每个Stage只有一个算子,这种情况快速发现耗时Stage,针对优化即可。
如图(原始和拆分Stage的DAG)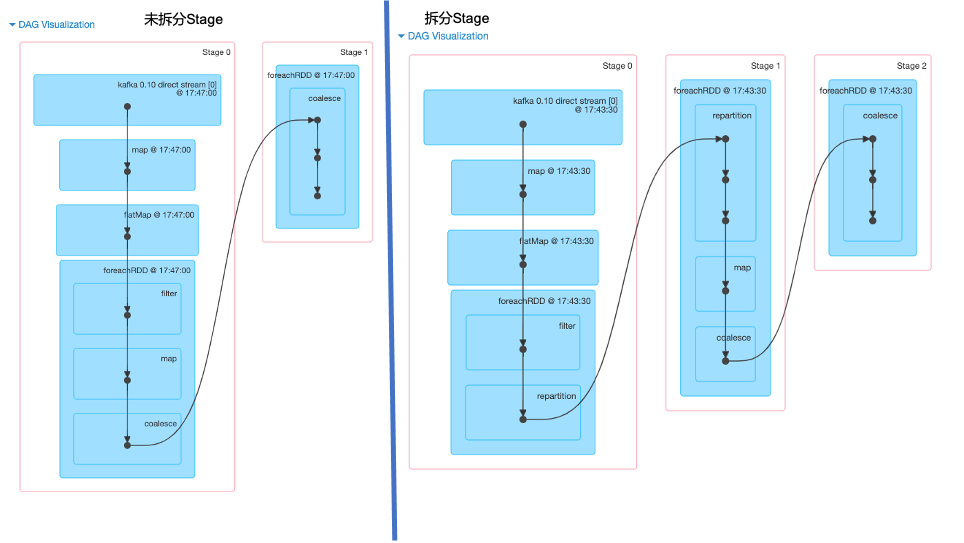
3、数据输出阶段
标签:定位 取数据 api park from 图片 外部 问题排查 均衡
原文地址:https://blog.51cto.com/10120275/2549797