标签:定义 scrapy 实现 基本 pat spider rtp src crawl
https://docs.scrapy.org/en/latest/topics/commands.html (官方文档)
1.scrapy startproject hello
此时会生成一个hello工程,同时生成一个srapy.cfg配置文件和一个同名文件夹
2.srapy genspider quote quotes.toscrape.com
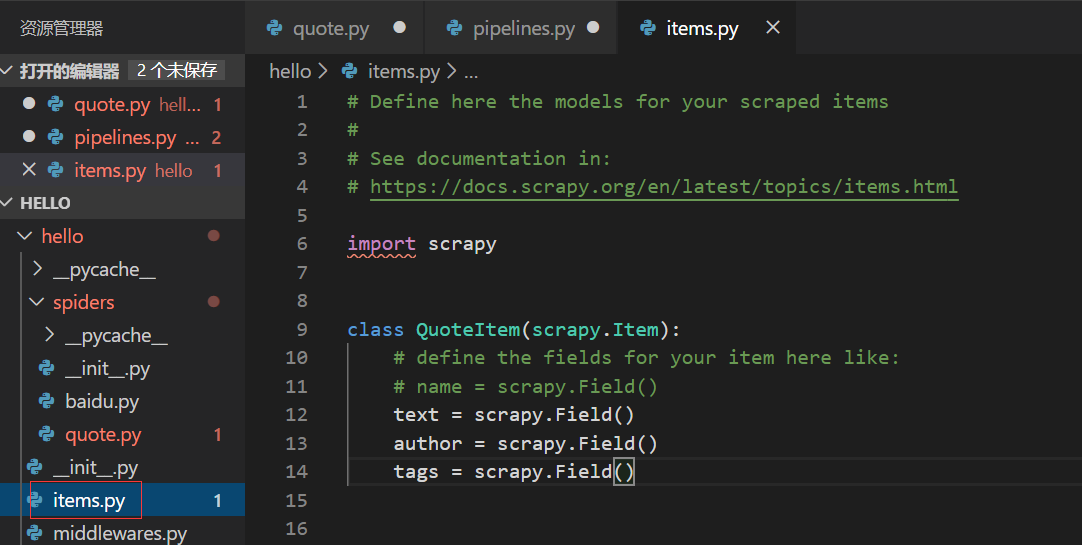
items.py,定义了保存数据时的数据结构
middlewares.py,处理中间件,可以处理request,response等
pipelines.py,可以
settings.py,配置信息
quote.py,主要代码实现在该spider中
3.spider crawl quote (quote为创建的spider,注意不要带.py后缀)
爬取网页并解析,输出结果到屏幕
spider crawl quote -o quotes.json
将结果输出到json文件中
同时还支持其他文件方式的保存,如:quotes.csv,quotes.marshal,quotes.xml
spider crawl quote -o ftp://username:pass@ftp.example.com/path/quotes.csv
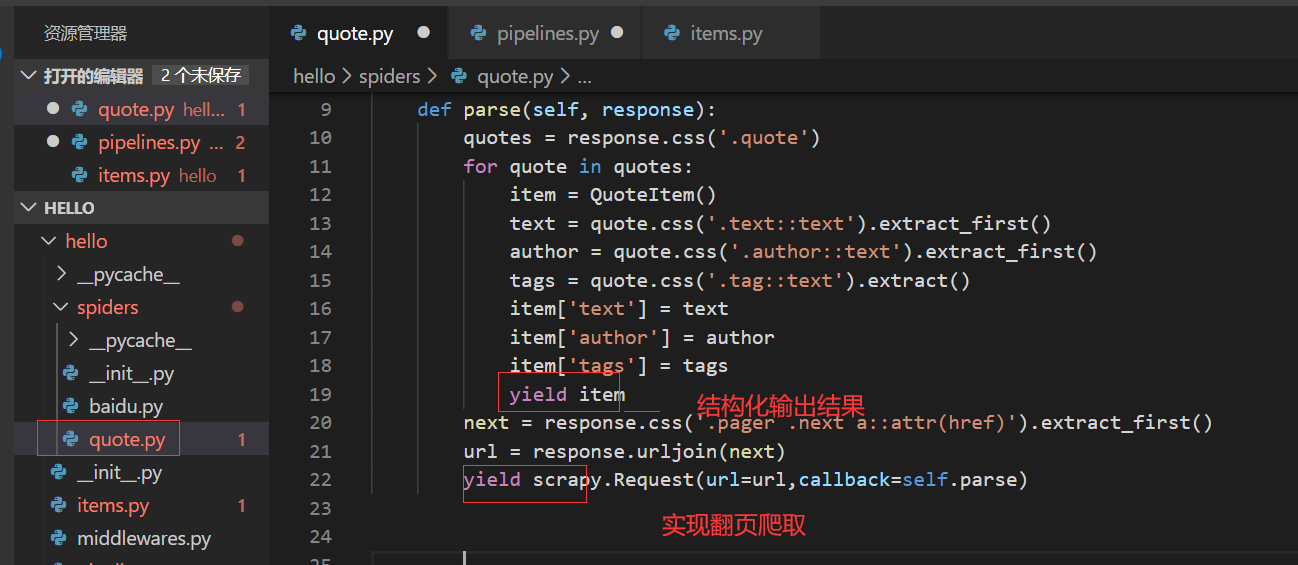
4.spider介绍

标签:定义 scrapy 实现 基本 pat spider rtp src crawl
原文地址:https://www.cnblogs.com/tingshu/p/13977546.html