标签:token tco range 一起 art 释放 cluster 开源 支付
参考:
https://blog.csdn.net/paul_wei2008/article/details/19355681
https://blog.csdn.net/ygl19920119/article/details/88342523
https://blog.csdn.net/l_bestcoder/article/details/79368530
https://blog.csdn.net/chao_19/article/details/51764150
分布式服务框架:
–高性能和透明化的RPC远程服务调用方案
–SOA服务治理方案
-Apache MINA 框架基于Reactor模型通信框架,基于tcp长连接
Dubbo缺省协议采用单一长连接和NIO异步通讯,
适合于小数据量大并发的服务调用,以及服务消费者机器数远大于服务提供者机器数的情况
分析源代码,基本原理如下:
1、面试题
说一下的dubbo的工作原理?注册中心挂了可以继续通信吗?说说一次rpc请求的流程?
2、面试官心里分析
MQ、ES、Redis、Dubbo,上来先问你一些思考的问题,原理(kafka高可用架构原理、es分布式架构原理、redis线程模型原理、Dubbo工作原理),生产环境里可能会碰到的一些问题(每种技术引入之后生产环境都可能会碰到一些问题),系统设计(设计MQ,设计搜索引擎,设计一个缓存,设计rpc框架),
当然比如说,hard面试官,死扣,结合项目死扣细节,百度(深入底层,基础性),阿里(结合项目死扣细节,扣很深的技术底层),小米(数据结构和算法)。
那既然开始聊分布式系统了,自然重点先聊聊dubbo了,毕竟dubbo是目前事实上大部分公司的分布式系统的rpc框架标准,基于dubbo也可以构建一整套的微服务架构。但是需要自己大量开发。
当然去年开始spring cloud非常火,现在大量的公司开始转向spring cloud了,spring cloud人家毕竟是微服务架构的全家桶式的这么一个东西。但是因为很多公司还在用dubbo,所以dubbo肯定会是目前面试的重点,何况人家dubbo现在重启开源社区维护了,未来应该也还是有一定市场和地位的。
既然聊dubbo,那肯定是先从dubbo原理开始聊了,你先说说dubbo支撑rpc分布式调用的架构是啥,然后说说一次rpc请求dubbo是怎么给你完成的,对吧。
(1)dubbo工作原理
第一层:service层,接口层,给服务提供者和消费者来实现的
第二层:config层,配置层,主要是对dubbo进行各种配置的
第三层:proxy层,服务代理层,透明生成客户端的stub和服务单的skeleton
第四层:registry层,服务注册层,负责服务的注册与发现
第五层:cluster层,集群层,封装多个服务提供者的路由以及负载均衡,将多个实例组合成一个服务
第六层:monitor层,监控层,对rpc接口的调用次数和调用时间进行监控
第七层:protocol层,远程调用层,封装rpc调用
第八层:exchange层,信息交换层,封装请求响应模式,同步转异步
第九层:transport层,网络传输层,抽象mina和netty为统一接口
第十层:serialize层,数据序列化层
工作流程:
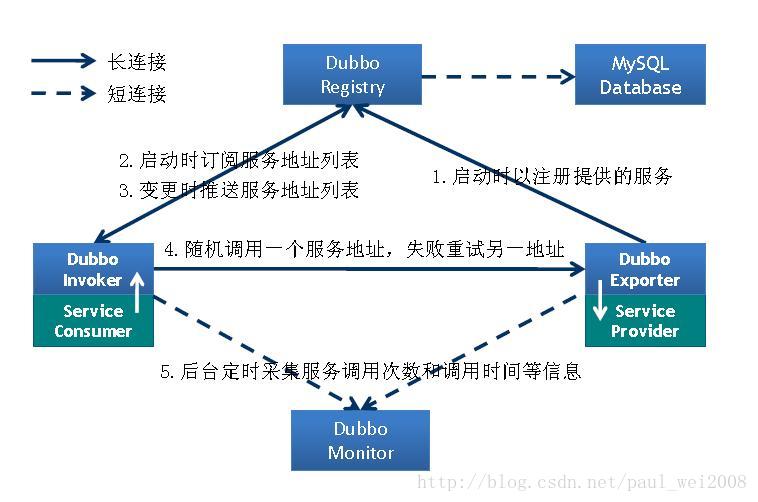
1)第一步,provider向注册中心去注册
2)第二步,consumer从注册中心订阅服务,注册中心会通知consumer注册好的服务
3)第三步,consumer调用provider
4)第四步,consumer和provider都异步的通知监控中心

dubbo的工作原理.png
(2)注册中心挂了可以继续通信吗?
可以,因为刚开始初始化的时候,消费者会将提供者的地址等信息拉取到本地缓存,所以注册中心挂了可以继续通信。
(3)Dubbo的执行流程:
项目一启动,加载配置文件的时候,就会初始化,服务的提供方ServiceProvider就会向注册中心注册自己提供的服务,当消费者在启动时,就会向注册中心订阅自己所需要的服务,如果服务提供方有数据变更等,注册中心将基于长连接的形式推送变更数据给消费者。
默认使用Dubbo协议:
连接个数:单连接
连接方式:长连接
传输协议:TCP
传输方式:NIO异步传输
序列化:Hessian二进制序列化
适用范围:传入传出参数数据包较小(建议小于100K),消费者比提供者个数多,单一消费者无法压满提供者,尽量不要使用dubbo协议传输大文件或超大字符串
使用场景:常规远程服务方法调用
从上面的适用范围总结,dubbo适合小数据量大并发的服务调用,以及消费者机器远大于生产者机器数的情况,不适合传输大数据量的服务比如文件、视频等,除非请求量很低。
(4)Dubbo的安全性如何得到保障:
a.在有注册中心的情况下,可以通过dubbbo admin中的路由规则,来指定固定ip的消费方来访问
b.在直连的情况下,通过在服务的提供方中设置密码(令牌)token,消费方需要在消费时也输入这 个密码,才能够正确使用。
Dubbo添加服务ip白名单,防止不法调用
(5)Duubo中如何保证分布式事务?
一般情况下,我们尽量将需要事务的方法放在一个service中,从而避开分步式事务。
Dubbo底层是基于socket: Socket通信是一个全双工的方式,如果有多个线程同时进行远程方法调用,这时建立在client server之间的socket连接上会有很多双方发送的消息传递,前后顺序也可能是乱七八糟的,server处理完结果后,将结果消息发送给client,client收到很多消息,怎么知道哪个消息结果是原先哪个线程调用的?
答:使用一个ID,让其唯一,然后传递给服务端,再服务端又回传回来,这样就知道结果是原先哪个线程的了。
(6)Dubbo的心跳机制:
目的:
维持provider和consumer之间的长连接
实现:
dubbo心跳时间heartbeat默认是1s,超过heartbeat时间没有收到消息,就发送心跳消 息(provider,consumer一样),如果连着3次(heartbeatTimeout为heartbeat*3)没有收到心跳响应,provider会关闭channel,而consumer会进行重连;不论是provider还是consumer的心跳检测都是通过启动定时任务的方式实现;
Dubbo的zookeeper做注册中心,如果注册中心全部挂掉,发布者和订阅者还能通信吗?
可以通信的,启动dubbo时,消费者会从zk拉取注册的生产者的地址接口等数据,缓存在本地。每次调用时,按照本地存储的地址进行调用;
注册中心对等集群,任意一台宕机后,将会切换到另一台;注册中心全部宕机后,服务的提供者和消费者仍能通过本地缓存通讯。服务提供者无状态,任一台 宕机后,不影响使用;服务提供者全部宕机,服务消费者会无法使用,并无限次重连等待服务者恢复;
挂掉是不要紧的,但前提是你没有增加新的服务,如果你要调用新的服务,则是不能办到的。
当网站规模很小时,采用单一应用框架,把所有的服务集中在一个应用中,但随着网站规模增大,单一应用框架会越来越难维护。
2、垂直应用架构
把应用垂直的拆分开来,拆分成如支付、查询等垂直模块,每个模块都有从顶层显示层到底层数据持久层的业务逻辑,每个模块都是一个独立的子系统。虽然在一定程度上降低了开发成本和维护成本,但是会导致许多底层业务逻辑代码的重复。
3、分布式应用架构
把核心的业务抽离出来,作为独立的服务,供上层消费者调用。
这种架构就可以用到Dubbo框架,Dubbo是一个RPC(Remote Procedure Call Protocal)框架,用于实现SOA架构,在分布式情况下可以远程调用其他服务器暴露的方法。
1、如何做到透明化的调用远程服务?
采用JDK动态代理技术或CGLib字节码生成(asm)技术。一般都采用JDK动态代理,因为代码易维护。当调用生产者类的服务时,其实调用的是代理类的方法,代理类中执行了通信的业务逻辑,并且获得最后的执行结果。
2、消息的数据结构
服务调用者请求消息:接口名、方法名、参数类型及参数值、超时时间、RequestID
服务生产者返回消息:返回值、状态码、RequestID
RequestID:因为消息的发送与接收是异步的,为了辨别返回的消息属于哪个请求。
3、序列化方式
序列化就是将数据结构或对象转化为二进制串的过程,只有转换成了二进制串才能进行网络传输。
要考虑通用性、性能以及可扩展性。dubbo采用hessian。
4、通信方式
基于NIO。
5、发布服务
ZooKeeper提供了服务的注册于自动发现功能,服务提供者的增加、删除对调用者来说是透明的。还提供心跳机制来检测服务提供者是否还存在。
一、Duboo基本概念解释
Dubbo是一种分布式服务框架。 Webservice也是一种服务框架,但是webservice并不是分布式的服务框架,他需要结合F5实现负载均衡。因此,dubbo除了可以提供服务之外,还可以实现软负载均衡。它还提供了两个功能Monitor 监控中心和调用中心。这两个是可选的,需要单独配置。
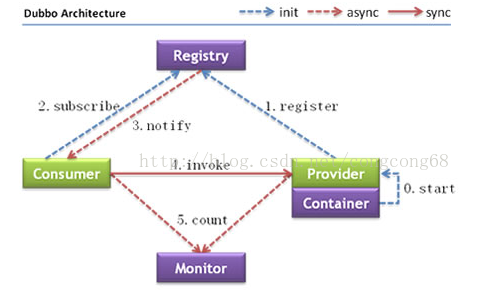
Dubbo的计数架构图如下:
我们解释以下这个架构图:
Consumer服务消费者,Provider服务提供者。Container服务容器。消费当然是invoke提供者了,invoke这条实线按照图上的说明当然同步的意思了,多说一句,在实际调用过程中,Provider的位置对于Consumer来说是透明的,上一次调用服务的位置(IP地址)和下一次调用服务的位置,是不确定的。这个地方就是实现了软负载。
服务提供者先启动start,然后注册register服务。
消费订阅subscribe服务,如果没有订阅到自己想获得的服务,它会不断的尝试订阅。新的服务注册到注册中心以后,注册中心会将这些服务通过notify到消费者。
Monitor这是一个监控,图中虚线表明Consumer 和Provider通过异步的方式发送消息至Monitor,Consumer和Provider会将信息存放在本地磁盘,平均1min会发送一次信息。Monitor在整个架构中是可选的(图中的虚线并不是可选的意思),Monitor功能需要单独配置,不配置或者配置以后,Monitor挂掉并不会影响服务的调用。
二、dubbo原理
本篇博客的内容总体上比较抽象,如果一个想马上使用dubbo的同学来说,读这篇博客效果不太好,本篇博客没有写怎么使用、配置dubbo,接下来,我再令写一篇dubbo入门包含demo的博客。
I、初始化过程细节:
上图中的第一步start,就是将服务装载容器中,然后准备注册服务。和Spring中启动过程类似,spring启动时,将bean装载进容器中的时候,首先要解析bean。所以dubbo也是先读配置文件解析服务。
解析服务:
1)、基于dubbo.jar内的Meta-inf/spring.handlers配置,spring在遇到dubbo名称空间时,会回调DubboNamespaceHandler类。
2)、所有的dubbo标签,都统一用DubboBeanDefinitionParser进行解析,基于一对一属性映射,将XML标签解析为Bean对象。
源码截图:
在ServiceConfig.export 或者ReferenceConfig.get 初始化时,将Bean对象转会为url格式,将所以Bean属性转成url的参数。
然后将URL传给Protocol扩展点,基于扩展点的Adaptive机制,根据URL的协议头,进行不同协议的服务暴露和引用。
暴露服务:
a、 只暴露服务端口
在没有使用注册中心的情况,这种情况一般适用在开发环境下,服务的调用这和提供在同一个IP上,只需要打开服务的端口即可。
即,当配置 or
ServiceConfig解析出的URL的格式为:
Dubbo://service-host/com.xxx.TxxService?version=1.0.0
基于扩展点的Adaptiver机制,通过URL的“dubbo://”协议头识别,直接调用DubboProtocol的export()方法,打开服务端口。
b、向注册中心暴露服务:
和上一种的区别:需要将服务的IP和端口一同暴露给注册中心。
ServiceConfig解析出的url格式为:
registry://registry-host/com.alibaba.dubbo.registry.RegistryService?export=URL.encode(“dubbo://service-host/com.xxx.TxxService?version=1.0.0”)
基于扩展点的Adaptive机制,通过URL的“registry://”协议头识别,调用RegistryProtocol的export方法,将export参数中的提供者URL先注册到注册中心,再重新传给Protocol扩展点进行暴露:
Dubbo://service-host/com.xxx.TxxService?version=1.0.0
引用服务:
a、直接引用服务:
在没有注册中心的,直连提供者情况下,
ReferenceConfig解析出的URL格式为:
Dubbo://service-host/com.xxx.TxxService?version=1.0.0
基于扩展点的Adaptive机制,通过url的“dubbo://”协议头识别,直接调用DubboProtocol的refer方法,返回提供者引用。
b、从注册中心发现引用服务:
此时,ReferenceConfig解析出的URL的格式为:
?registry://registry-host/com.alibaba.dubbo.registry.RegistryService?refer=URL.encode(“consumer://consumer-host/com.foo.FooService?version=1.0.0”)
基于扩展点的Apaptive机制,通过URL的“registry://”协议头识别,就会调用RegistryProtocol的refer方法,基于refer参数总的条件,查询提供者URL,如:
Dubbo://service-host/com.xxx.TxxService?version=1.0.0
基于扩展点的Adaptive机制,通过提供者URL的“dubbo://”协议头识别,就会调用DubboProtocol的refer()方法,得到提供者引用。
然后RegistryProtocol将多个提供者引用,通过Cluster扩展点,伪装成单个提供这引用返回。
三、远程调用细节:
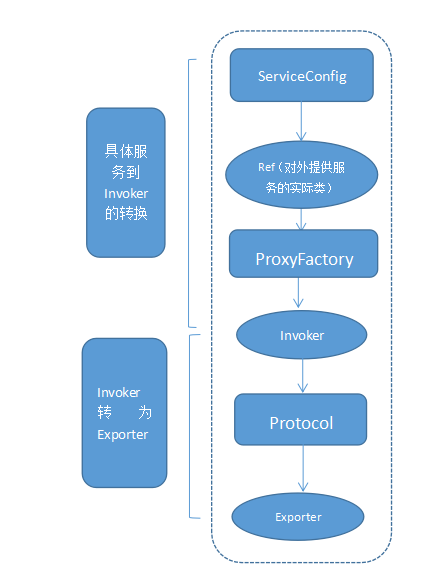
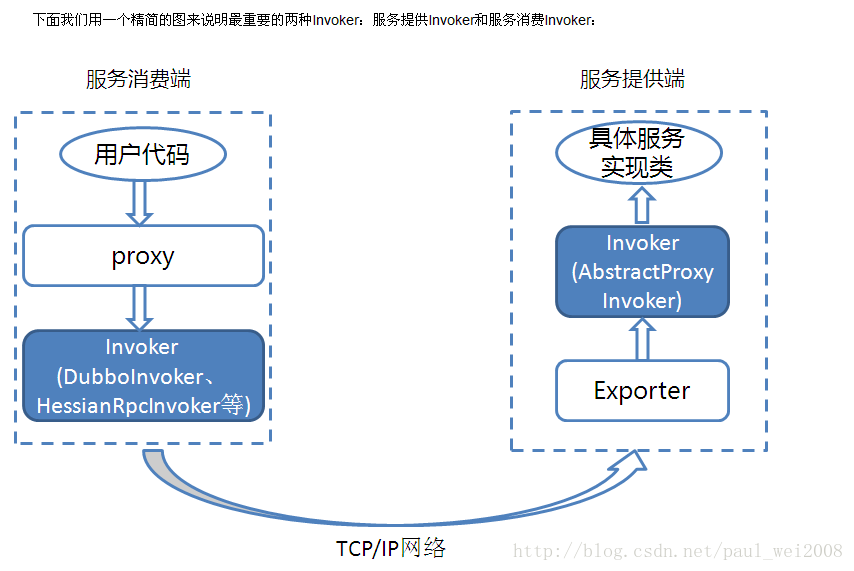
服务提供者暴露一个服务的详细过程:
上图是服务提供者暴露服务的主过程:
首先ServiceConfig类拿到对外提供服务的实际类ref,然后将ProxyFactory类的getInvoker方法使用ref生成一个AbstractProxyInvoker实例,到这一步就完成具体服务到invoker的转化。接下来就是Invoker转换到Exporter的过程。
Dubbo处理服务暴露的关键就在Invoker转换到Exporter的过程,下面我们以Dubbo和rmi这两种典型协议的实现来进行说明:
Dubbo的实现:
Dubbo协议的Invoker转为Exporter发生在DubboProtocol类的export方法,它主要是打开socket侦听服务,并接收客户端发来的各种请求,通讯细节由dubbo自己实现。
Rmi的实现:
RMI协议的Invoker转为Exporter发生在RmiProtocol类的export方法,他通过Spring或Dubbo或JDK来实现服务,通讯细节由JDK底层来实现。
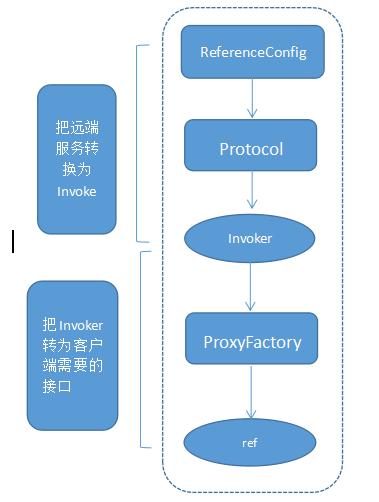
服务消费者消费一个服务的详细过程
上图是服务消费的主过程:
首先ReferenceConfig类的init方法调用Protocol的refer方法生成Invoker实例。接下来把Invoker转为客户端需要的接口
标签:token tco range 一起 art 释放 cluster 开源 支付
原文地址:https://www.cnblogs.com/xuwc/p/14019099.html