标签:lin exp join sele base panda div boost latest
toad是由厚本金融风控团队内部孵化,后开源并坚持维护的标准化评分卡库。其功能全面、性能稳健、运行速度快、问题反馈后维护迅速、深受同行喜爱。如果有些小伙伴没有一些标准化的信用评分开发工具或者企业级的定制化脚本,toad应该会极大的节省大家的时间
github主页:https://github.com/amphibian-dev/toad
文档:https://toad.readthedocs.io/
演示:https://toad.readthedocs.io/en/latest/tutorial.html
whl下载地址:https://pypi.org/simple/toad/
文章转自:https://zhuanlan.zhihu.com/p/90354450
import pandas as pd from sklearn.metrics import roc_auc_score,roc_curve,auc #常见的分类评分标准 from sklearn.model_selection import train_test_split #切分数据 from sklearn.linear_model import LogisticRegression #逻辑回归 from sklearn.model_selection import GridSearchCV as gscv #网格搜索 from sklearn.neighbors import KNeighborsClassifier #k近邻 import numpy as np import glob import math import xgboost as xgb import toad
#加载数据path = "D:/风控模型/data/" data_all = pd.read_csv(path+"data.txt",engine=‘python‘,index_col=False) data_all_woe = pd.read_csv(path+"ccard_all_woe.txt",engine=‘python‘,index_col=False) #指定不参与训练列名 ex_lis = [‘uid‘,‘obs_mth‘,‘ovd_dt‘,‘samp_type‘,‘weight‘, ‘af30_status‘,‘submit_time‘,‘bad_ind‘] #参与训练列名 ft_lis = list(data_all.columns) for i in ex_lis: ft_lis.remove(i)
#训练集与跨时间验证集合 dev = data_all[(data_all[‘samp_type‘] == ‘dev‘) | (data_all[‘samp_type‘] == ‘val‘) | (data_all[‘samp_type‘] == ‘off1‘) ] off = data_all[data_all[‘samp_type‘] == ‘off2‘]
探索性数据分析 同时处理数值型和字符型
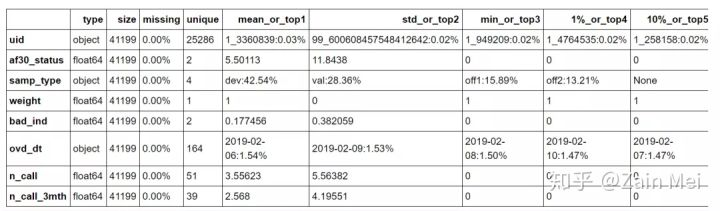
a = toad.detector.detect(data_all)
a.head(8)
dev_slct1, drop_lst= toad.selection.select(dev,dev[‘bad_ind‘], empty = 0.7, iv = 0.02, corr = 0.7, return_drop=True, exclude=ex_lis) print("keep:",dev_slct1.shape[1], "drop empty:",len(drop_lst[‘empty‘]), "drop iv:",len(drop_lst[‘iv‘]), "drop corr:",len(drop_lst[‘corr‘]))
keep: 584
drop empty: 637
drop iv: 1961
drop corr: 2043
dev_slct2, drop_lst= toad.selection.select(dev_slct1,dev_slct1[‘bad_ind‘], empty = 0.6, iv = 0.02, corr = 0.7, return_drop=True, exclude=ex_lis) print("keep:",dev_slct2.shape[1], "drop empty:",len(drop_lst[‘empty‘]), "drop iv:",len(drop_lst[‘iv‘]), "drop corr:",len(drop_lst[‘corr‘]))
keep: 560
drop empty: 24
drop iv: 0
drop corr: 0
分箱,先找到分箱的阈值
分箱阈值的方法(method) 包括:‘chi‘,‘dt‘,‘quantile‘,‘step‘,‘kmeans‘
然后利用分箱阈值进行粗分箱。
#得到切分节点 combiner = toad.transform.Combiner() combiner.fit(dev_slct2,dev_slct2[‘bad_ind‘],method=‘chi‘,min_samples = 0.05, exclude=ex_lis) #导出箱的节点 bins = combiner.export() #根据节点实施分箱 dev_slct3 = combiner.transform(dev_slct2) off3 = combiner.transform(off[dev_slct2.columns]) #分箱后通过画图观察,x分箱后某个字段 from toad.plot import bin_plot,badrate_plot bin_plot(dev_slct3,x=‘p_ovpromise_6mth‘,target=‘bad_ind‘) bin_plot(off3,x=‘p_ovpromise_6mth‘,target=‘bad_ind‘)
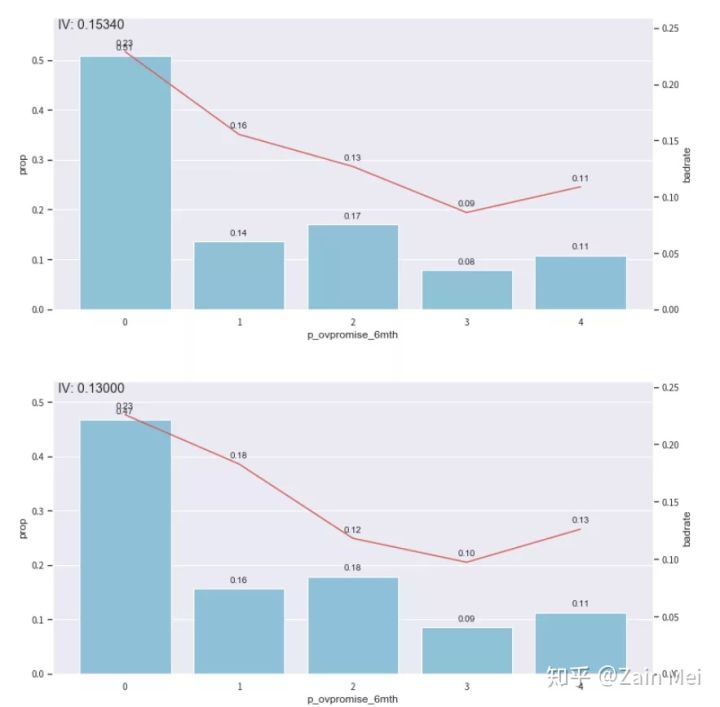
后2箱不单调
#查看单箱节点 [0.0, 24.0, 60.0, 100.0] bins[‘p_ovpromise_6mth‘]
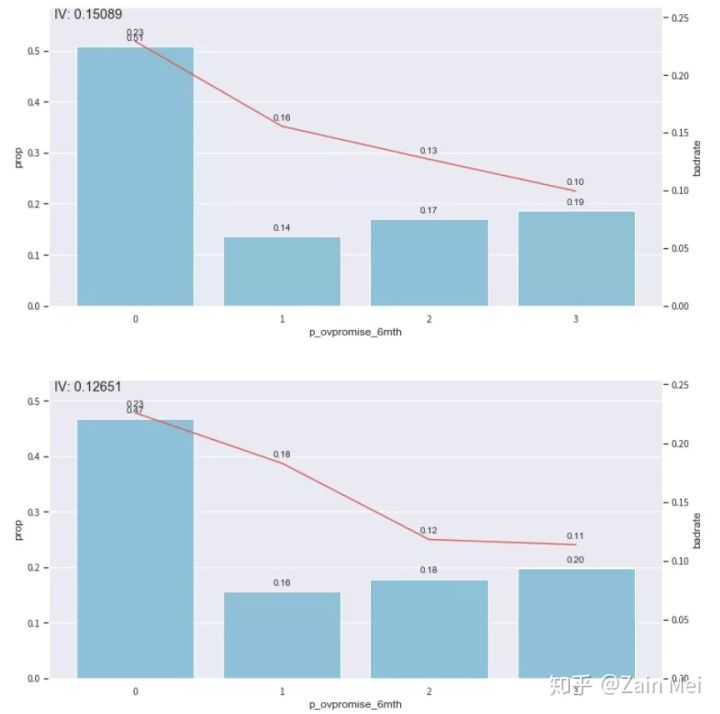
合并最后两箱
adj_bin = {‘p_ovpromise_6mth‘: [0.0, 24.0, 60.0]}
combiner.set_rules(adj_bin)
dev_slct3 = combiner.transform(dev_slct2)
off3 = combiner.transform(off[dev_slct2.columns])
bin_plot(dev_slct3,x=‘p_ovpromise_6mth‘,target=‘bad_ind‘)
bin_plot(off3,x=‘p_ovpromise_6mth‘,target=‘bad_ind‘)
对比不同数据集上特征的badrate图是否有交叉
data = pd.concat([dev_slct3,off3],join=‘inner‘) badrate_plot(data, x=‘samp_type‘, target=‘bad_ind‘, by=‘p_ovpromise_6mth‘)
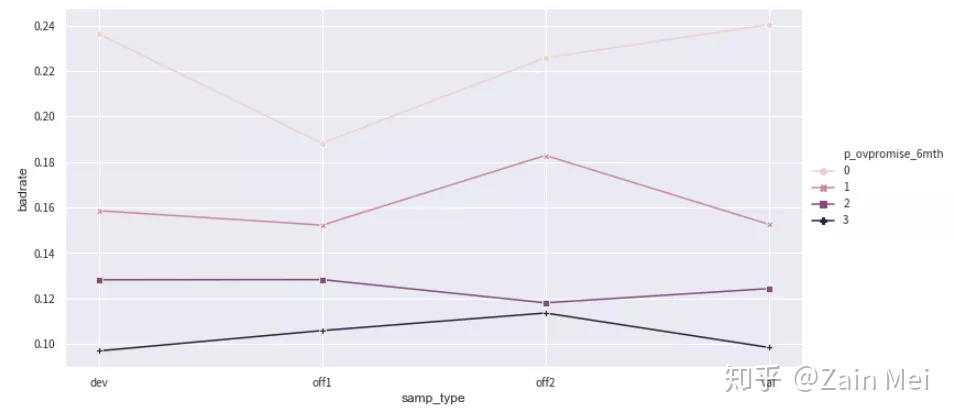
没有交叉,因此该特征的分组不需要再进行合并。篇幅有限,不对所有特征的精细化调整做展示。接下来进行WOE映射
# t=toad.transform.WOETransformer() dev_slct2_woe = t.fit_transform(dev_slct3,dev_slct3[‘bad_ind‘], exclude=ex_lis) off_woe = t.transform(off3[dev_slct3.columns]) data = pd.concat([dev_slct2_woe,off_woe])
通过稳定性筛选特征。计算训练集与跨时间验证集的PSI。删除PSI大于0.05的特征
#(41199, 476) psi_df = toad.metrics.PSI(dev_slct2_woe, off_woe).sort_values(0) psi_df = psi_df.reset_index() psi_df = psi_df.rename(columns = {‘index‘ : ‘feature‘,0:‘psi‘}) psi005 = list(psi_df[psi_df.psi<0.05].feature) for i in ex_lis: if i in psi005: pass else: psi005.append(i) data = data[psi005] dev_woe_psi = dev_slct2_woe[psi005] off_woe_psi = off_woe[psi005] print(data.shape)
由于分箱后变量之间的共线性会变强,通过相关性再次筛选特征
# dev_woe_psi2, drop_lst= toad.selection.select(dev_woe_psi,dev_woe_psi[‘bad_ind‘], empty = 0.6, iv = 0.02, corr = 0.5, return_drop=True, exclude=ex_lis) print("keep:",dev_woe_psi2.shape[1], "drop empty:",len(drop_lst[‘empty‘]), "drop iv:",len(drop_lst[‘iv‘]), "drop corr:",len(drop_lst[‘corr‘]))
keep: 85
drop empty: 0
drop iv: 56
drop corr: 335
接下来通过逐步回归进行最终的特征筛选。检验方法(criterion):
检验模型(estimator)
‘ols‘: LinearRegression,
‘lr‘: LogisticRegression,
‘lasso‘: Lasso,
‘ridge‘: Ridge,
#(41199, 33) dev_woe_psi_stp = toad.selection.stepwise(dev_woe_psi2, dev_woe_psi2[‘bad_ind‘], exclude = ex_lis, direction = ‘both‘, criterion = ‘aic‘, estimator = ‘ols‘, intercept = False) off_woe_psi_stp = off_woe_psi[dev_woe_psi_stp.columns] data = pd.concat([dev_woe_psi_stp,off_woe_psi_stp]) data.shape
接下来定义双向逻辑回归和检验模型XGBoost
#定义逻辑回归 def lr_model(x,y,offx,offy,C): model = LogisticRegression(C=C,class_weight=‘balanced‘) model.fit(x,y) y_pred = model.predict_proba(x)[:,1] fpr_dev,tpr_dev,_ = roc_curve(y,y_pred) train_ks = abs(fpr_dev - tpr_dev).max() print(‘train_ks : ‘,train_ks) y_pred = model.predict_proba(offx)[:,1] fpr_off,tpr_off,_ = roc_curve(offy,y_pred) off_ks = abs(fpr_off - tpr_off).max() print(‘off_ks : ‘,off_ks) from matplotlib import pyplot as plt plt.plot(fpr_dev,tpr_dev,label = ‘train‘) plt.plot(fpr_off,tpr_off,label = ‘off‘) plt.plot([0,1],[0,1],‘k--‘) plt.xlabel(‘False positive rate‘) plt.ylabel(‘True positive rate‘) plt.title(‘ROC Curve‘) plt.legend(loc = ‘best‘) plt.show() #定义xgboost辅助判断盘牙鞥特征交叉是否有必要 def xgb_model(x,y,offx,offy): model = xgb.XGBClassifier(learning_rate=0.05, n_estimators=400, max_depth=3, class_weight=‘balanced‘, min_child_weight=1, subsample=1, objective="binary:logistic", nthread=-1, scale_pos_weight=1, random_state=1, n_jobs=-1, reg_lambda=300) model.fit(x,y) print(‘>>>>>>>>>‘) y_pred = model.predict_proba(x)[:,1] fpr_dev,tpr_dev,_ = roc_curve(y,y_pred) train_ks = abs(fpr_dev - tpr_dev).max() print(‘train_ks : ‘,train_ks) y_pred = model.predict_proba(offx)[:,1] fpr_off,tpr_off,_ = roc_curve(offy,y_pred) off_ks = abs(fpr_off - tpr_off).max() print(‘off_ks : ‘,off_ks) from matplotlib import pyplot as plt plt.plot(fpr_dev,tpr_dev,label = ‘train‘) plt.plot(fpr_off,tpr_off,label = ‘off‘) plt.plot([0,1],[0,1],‘k--‘) plt.xlabel(‘False positive rate‘) plt.ylabel(‘True positive rate‘) plt.title(‘ROC Curve‘) plt.legend(loc = ‘best‘) plt.show() #模型训练 def c_train(data,dep=‘bg_result_compensate‘,exclude=None): from sklearn.preprocessing import StandardScaler std_scaler = StandardScaler() #变量名 lis = list(data.columns) for i in exclude: lis.remove(i) data[lis] = std_scaler.fit_transform(data[lis]) devv = data[(data[‘samp_type‘]==‘dev‘) | (data[‘samp_type‘]==‘val‘)] offf = data[(data[‘samp_type‘]==‘off1‘) | (data[‘samp_type‘]==‘off2‘) ] x,y = devv[lis],devv[dep] offx,offy = offf[lis],offf[dep] #逻辑回归正向 lr_model(x,y,offx,offy,0.1) #逻辑回归反向 lr_model(offx,offy,x,y,0.1) #XGBoost正向 xgb_model(x,y,offx,offy) #XGBoost反向 xgb_model(offx,offy,x,y)
在特征精细化分箱后,xgboost模型的KS明显高于LR,则特征交叉是有必要的。需要返回特征工程过程进行特征交叉衍生。两模型KS接近代表特征交叉对模型没有明显提升。反向模型KS代表模型最高可能达到的结果。如果反向训练集效果较差,说明跨时间验证集本身分布较为特殊,应当重新划分数据。
# c_train(data,dep=‘bad_ind‘,exclude=ex_lis)
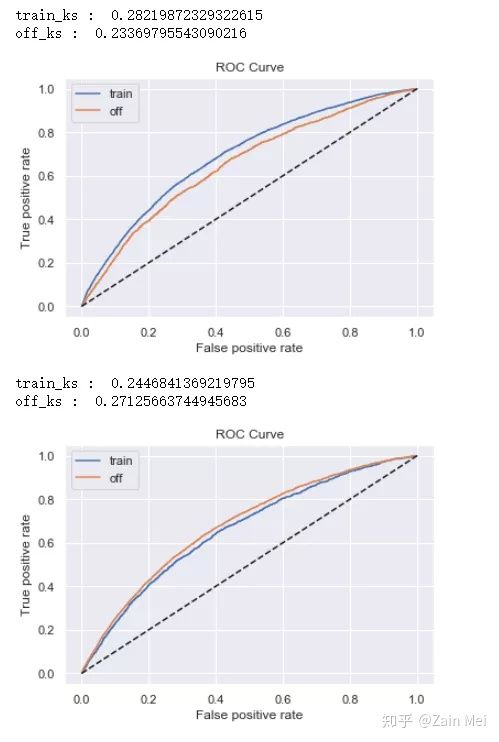
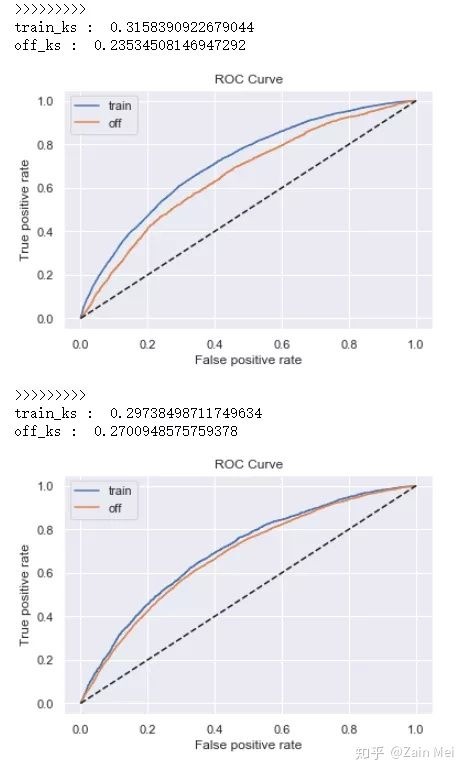
评分卡模型训练
#模型训练 dep = ‘bad_ind‘ lis = list(data.columns) for i in ex_lis: lis.remove(i) devv = data[(data[‘samp_type‘]==‘dev‘) | (data[‘samp_type‘]==‘val‘)] offf = data[(data[‘samp_type‘]==‘off1‘) | (data[‘samp_type‘]==‘off2‘) ] x,y = devv[lis],devv[dep] offx,offy = offf[lis],offf[dep] lr = LogisticRegression() lr.fit(x,y)
分别计算:F1分数 KS值 AUC值
from toad.metrics import KS, F1, AUC prob_dev = lr.predict_proba(x)[:,1] print(‘训练集‘) print(‘F1:‘, F1(prob_dev,y)) print(‘KS:‘, KS(prob_dev,y)) print(‘AUC:‘, AUC(prob_dev,y)) prob_off = lr.predict_proba(offx)[:,1] print(‘跨时间‘) print(‘F1:‘, F1(prob_off,offy)) print(‘KS:‘, KS(prob_off,offy)) print(‘AUC:‘, AUC(prob_off,offy))
训练集
F1: 0.30815569972196477
KS: 0.2819389063516508
AUC: 0.6908879633467695
跨时间
F1: 0.2848354792560801
KS: 0.23181102640650808
AUC: 0.6522823050763138
计算模型PSI和变量PSI,两个角度衡量稳定性
print(‘模型PSI:‘,toad.metrics.PSI(prob_dev,prob_off)) print(‘特征PSI:‘,‘\n‘,toad.metrics.PSI(x,offx).sort_values(0))
模型PSI: 0.022260098554531284
特征PSI:

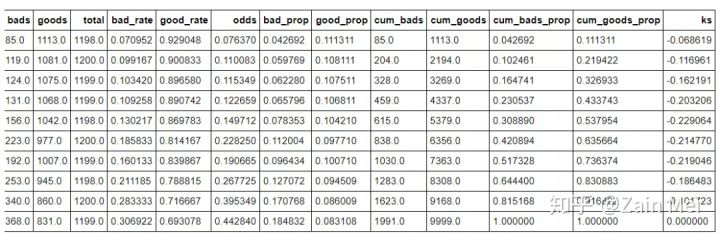
生产模型KS报告
off_bucket = toad.metrics.KS_bucket(prob_off,offy,bucket=10,method=‘quantile‘) off_bucket
生产评分卡。支持传入所有的模型参数,以及Fico分数校准的基础分与pdo(point of double odds),我一直管pdo叫步长...orz
from toad.scorecard import ScoreCard card = ScoreCard(combiner = combiner, transer = t,class_weight = ‘balanced‘,C=0.1,base_score = 600,base_odds = 35 ,pdo = 60,rate = 2) card.fit(x,y) final_card = card.export(to_frame = True) final_card.head(8)

标签:lin exp join sele base panda div boost latest
原文地址:https://www.cnblogs.com/cgmcoding/p/14026520.html